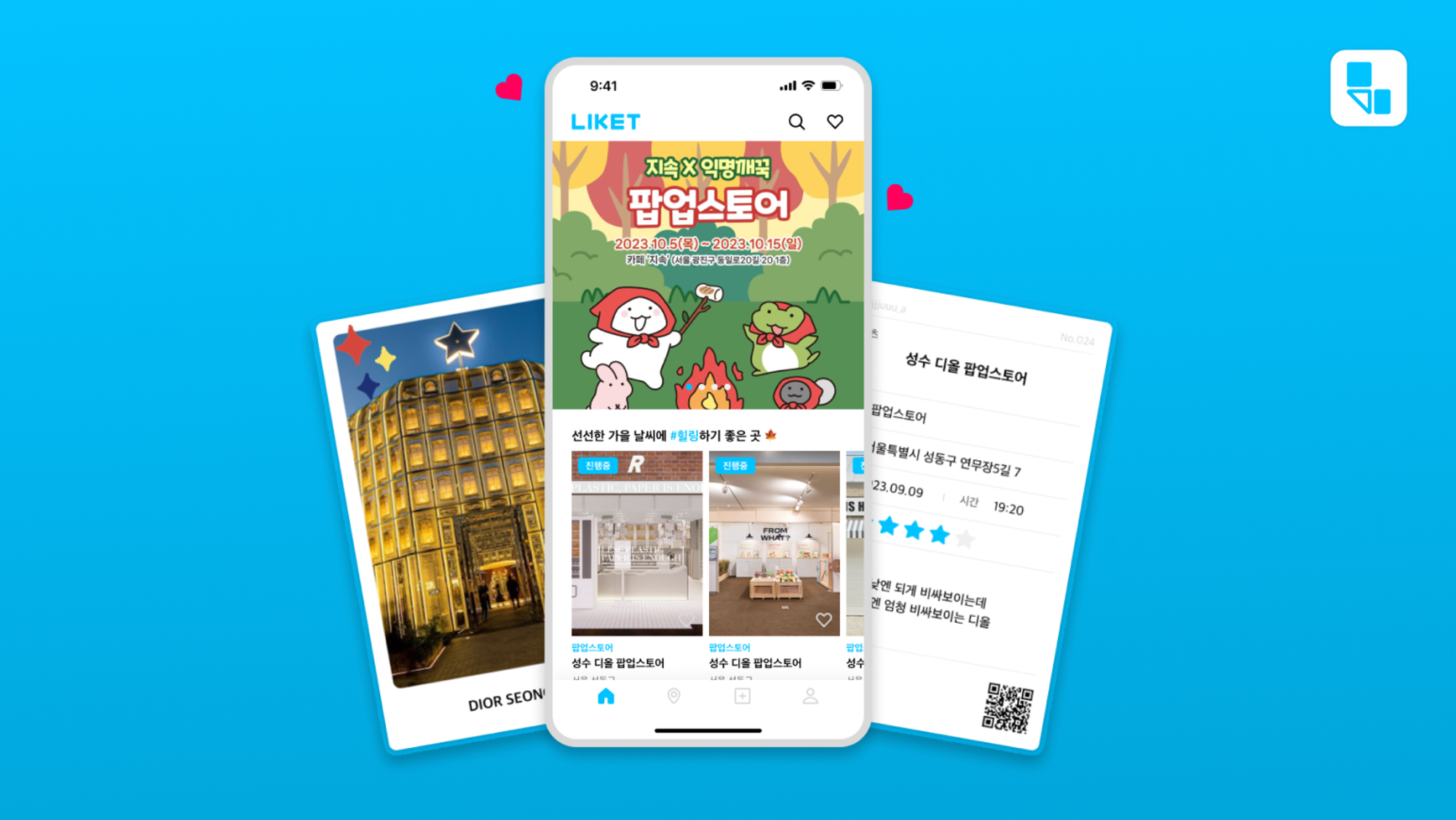
라이켓은 다양한 문화생활 정보를 공유하고 나만의 문화생활 기록을 남길 수 있는 서비스를 제공하고 있습니다.
태그별, 지역별로 관심있는 정보들만 골라보고 쉽게 문화생활을 즐겨보세요.
안녕하세요. LIKET 팀의 백엔드 개발을 담당하고 있는 민경찬입니다. LIKET에서는 지도를 통해 어떤 지역에 어떤 문화생활컨텐츠가 있는지 마커를 통해 보여주는 기능이 있습니다.
오늘은 지도에 보여줄 문화생활컨텐츠 지리 데이터를 LIKET팀에서 어떻게 관리하고 있는지 소개해보려고 합니다.
💡 LIKET의 지도 기능
LIKET에서는 아래 이미지처럼 지도를 통해 다양한 문화생활 콘텐츠를 확인할 수 있습니다.
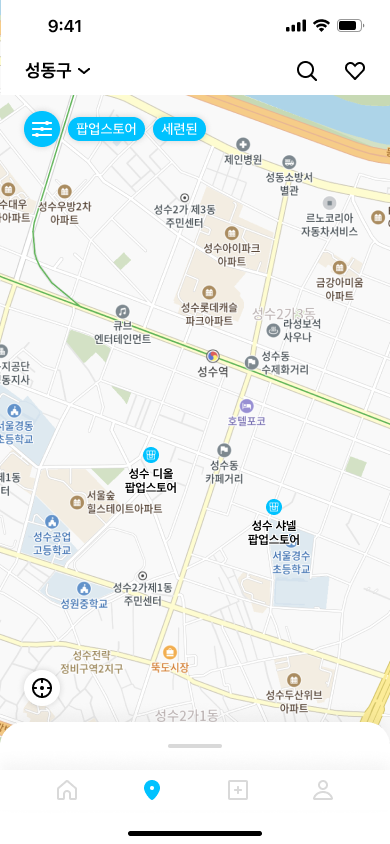
시/도로 필터링하여 특정 지역의 콘텐츠만 볼 수도 있습니다.
이를 위해서는 콘텐츠를 등록할 때 콘텐츠의 주소와 좌표를 저장해야 합니다.
❓ 컨텐츠 저장은 어떻게 했나요?
콘텐츠를 등록할 때 카카오 주소 검색 API를 통해 검색된 주소 데이터를 저장하고 있습니다.
이를 통해 각 콘텐츠가 어떤 주소를 가지고 있는지 저장합니다.
카카오에서 제공하는 주소 데이터는 다음과 같습니다.

위 데이터를 데이터베이스에 필요한 필드만 골라 그대로 저장하였습니다.
🧐 문제가 있었으니...
초기에 주소 데이터는 다음과 같은 형식으로 보관하였습니다.

100만 개의 콘텐츠 데이터를 삽입하여 부하 테스트를 진행하였습니다.
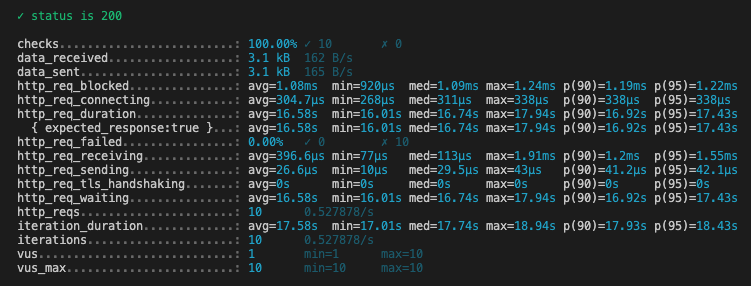
이 과정에서 시/도로 필터링하여 데이터를 가져오는 API에 부하 테스트에서 심각한 문제를 발견하였습니다.
API의 평균 응답시간이 16.58s가 나왔습니다...
🧐 원인은...
SELECT 쿼리를 분석한 결과, 법정동 코드 필터링이 문제였습니다.
QUERY PLAN
---------------------------------------------------------------------------------------------------
Gather (cost=23523.04..163673.47 rows=100 width=611)
Workers Planned: 2
-> Parallel Hash Join (cost=22523.04..162663.47 rows=42 width=611)
Hash Cond: (culture_content_tb.location_idx = location_tb.idx)
-> Parallel Seq Scan on culture_content_tb (cost=0.00..139044.19 rows=417619 width=506)
-> Parallel Hash (cost=22522.51..22522.51 rows=42 width=105)
-> Parallel Seq Scan on location_tb (cost=0.00..22522.51 rows=42 width=105)
Filter: ((b_code)::text ~~ '12%'::text)법정동 코드가 12로 시작하는 데이터를 탐색하였지만, 인덱스를 전혀 사용하지 않아 엄청나게 오래 걸리는 결과가 발생했습니다.
여기서, 법정동 코드는 무엇이고 12로 시작하는 것은 어떤 의미를 가지는 것일까요?
🧐 법정동 코드란...
법정동이란 법률로 지정된 행정 구역입니다.
행정동과 비교했을 때 자주 변경되지 않는 특징이 있습니다.

법정동의 코드는 총 10자리로 이루어져 있습니다.
서비스에서는 시/도 단위로 데이터를 필터링해서 보여주기 때문에 법정동 코드를 사용하여 원하는 시/도의 코드로 분류할 필요가 있습니다.
💡 해결 과정은...
1. 역정규화 하기
위 문제를 해결하기 위하여 첫 번째로 b_code를 분리하여 저장하였습니다. LIKE 연산을 사용하지 않게 하기 위함이죠.
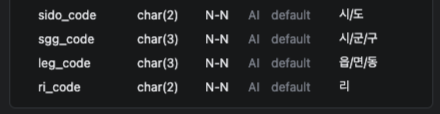
단순히
시/도만으로 필터링 할 경우b_code컬럼을 B+tree 로 인덱싱하여LIKE 'code%'로 탐색할 수 있었겠지만 다른 코드들은 인덱싱을 전혀 탈 수 없게됩니다.
나머지 코드들은LIKE '%code%'로 탐색해야하기 때문입니다. 그래서 역정규화 방식을 선택하였습니다.
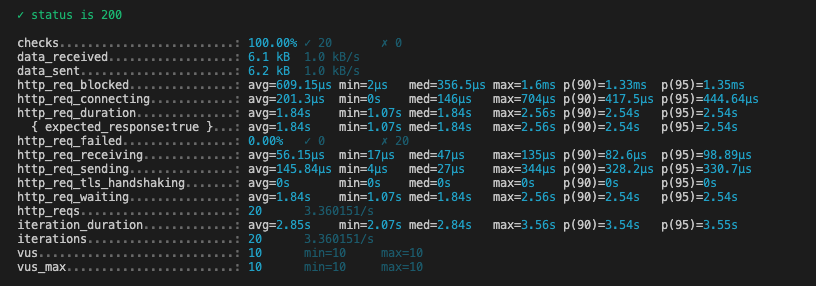
역정규화만으로 평균 16.58s가 걸리던 응답 시간이 1.84s로 줄었습니다.
하지만 1.84s조차도 너무나도 긴 시간입니다.
2. 인덱싱 태우기
여전히 Parallel Seq Scan 방식을 사용하고 있습니다.
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------
Gather (cost=44116.41..184256.95 rows=1 width=627) (actual time=502.582..508.818 rows=0 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Hash Join (cost=43116.41..183256.85 rows=1 width=627) (actual time=390.758..390.761 rows=0 loops=3)
Hash Cond: (culture_content_tb.location_idx = location_tb.idx)
-> Parallel Seq Scan on culture_content_tb (cost=0.00..139044.19 rows=417619 width=506) (never executed)
-> Parallel Hash (cost=43116.40..43116.40 rows=1 width=121) (actual time=389.783..389.784 rows=0 loops=3)
Buckets: 1024 Batches: 1 Memory Usage: 0kB
-> Parallel Seq Scan on location_tb (cost=0.00..43116.40 rows=1 width=121) (actual time=389.728..389.728 rows=0 loops=3)
Filter: (sido_code = '12'::bpchar)
Rows Removed by Filter: 334333역정규화 결과, WHERE sido_code = $1 처럼 등호 조건식을 사용할 수 있게되었습니다.
따라서, Char타입의 컬럼을 B+Tree로 인덱싱하는 것으로 완벽하게 인덱스를 태울 수 있었습니다.
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------
Gather (cost=1008.46..141148.99 rows=1 width=627) (actual time=99.466..104.329 rows=0 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Hash Join (cost=8.46..140148.89 rows=1 width=627) (actual time=2.445..2.452 rows=0 loops=3)
Hash Cond: (culture_content_tb.location_idx = location_tb.idx)
-> Parallel Seq Scan on culture_content_tb (cost=0.00..139044.19 rows=417619 width=506) (actual time=1.111..1.111 rows=1 loops=3)
-> Hash (cost=8.44..8.44 rows=1 width=121) (actual time=0.253..0.254 rows=0 loops=3)
Buckets: 1024 Batches: 1 Memory Usage: 8kB
-> Index Scan using index_sido_code on location_tb (cost=0.42..8.44 rows=1 width=121) (actual time=0.253..0.253 rows=0 loops=3)
Index Cond: (sido_code = '12'::bpchar)
Planning Time: 8.333 ms분석결과 아주 깔끔하게 Index Scan으로 변경되었습니다.
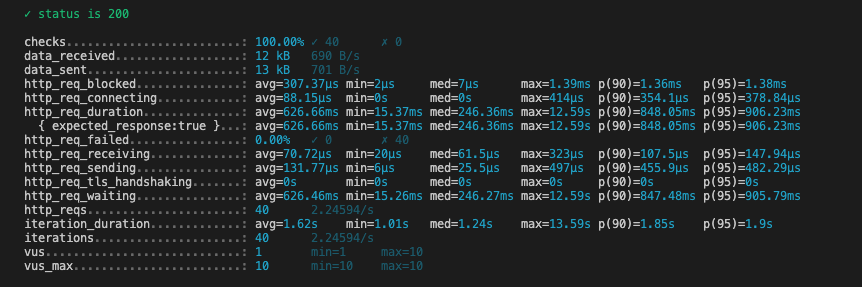
평균 응답 시간도 626.66ms까지 줄어들었습니다.
⭐️ 결론
오늘은 LIKET팀에서 컨텐츠 목록 지도 기능과 필터링하는 과정에서 발생했던 슬로우 쿼리를 해결하는 방법에 대해서 이야기해보았습니다.
언제나 최선의 결론을 내리도록 노력하는 LIKET 팀의 백엔드 개발자 민경찬이였습니다. 감사합니다.


안녕하세요 글 잘읽었습니다. 법정동 코드 컬럼을 시도/시군구/읍면동/리 4개의 컬럼으로 분리하신걸 역정규화하셨다고 언급하셨는데, 제가 알기로 역정규화란 데이터를 통합하는것으로 알고있는데 제가 잘못알고있는걸까요?