해싱 (Hashing) : 자료를 검색하기 위한 자료 구조
- 검색을 위한 자료 구조
- 키(key)에 대한 자료를 검색하기 위한 사전(dictionary) 개념의 자료 구조
- key는 유일하고 이에 대한 value를 쌍으로 저장
- index = h(key) : 해시 함수가 key에 대한 인덱스를 반환해줌 해당 인덱스 위치에 자료를 저장하거나 검색하게 됨
- 해시 함수에 의해 인덱스 연산이 산술적으로 가능 O(1)
- 저장되는 메모리 구조를 해시테이블이라 함
jdk 클래스 : HashMap, Properties
그래서 일반적으로 빠른 검색을 위해선 HashMap을 사용한다.
해쉬 테이블
강의를 참조한 예시로
예로들어
100개의 자리가 있을때 들어온 손님을 나머지 연산으로 자리를 앉힌다고 생각하자
24번 고객은 24번 자리에
156번 고객은 56번 자리에 ..
key (156) index는 56번이다.

해시충돌
데이터를 Key로 간소화하여 저장한다는 아이디어는 좋지만, 두 개의 다른 key가 동일한 hash(index)를 갖는다면??
같은 키값을 갖는 데이터가 생긴다는 것은, 특정 키의 버켓에 데이터가 집중된다는 뜻이다. 그래서 너무 많은 해시 충돌은 해시테이블의 성능을 떨어뜨린다.
해시 함수를 잘 정의하여 해시 충돌을 최소화 하는 것이 성능 개선에 도움이 된다. 또한 일반적으로 jdk는 75% 정도의 해쉬테이블이 차게 된다면 테이블을 늘리지만 해시함수의 입력값은 무한하지만, 출력값의 가짓수는 유한(출력값, 즉 키가 유한하지 않다면 해시기법을 사용하는 의미가 없다.)하므로 해시 충돌은 반드시 발생한다.(비둘기집 원리)
- 개방주소법
- 해시 충돌이 일어나면 다른 버켓에 데이터를 삽입하는 방식
예로들어 충돌이나면 몇칸띄어서 옆자리에 앉히는 방식이다.- 선형 탐색(Linear Probing): 해시충돌 시 다음 버켓, 혹은 몇 개를 건너뛰어 데이터를 삽입한다.
- 제곱 탐색(Quadratic Probing): 해시충돌 시 제곱만큼 건너뛴 버켓에 데이터를 삽입(1,4,9,16..)
- 이중 해시(Double Hashing): 해시충돌 시 다른 해시함수를 한 번 더 적용한 결과를 이용함.
- 체이닝
- 버켓 내에 연결리스트(Linked List)를 할당하여, 버켓에 데이터를 삽입하다가 해시 충돌이 발생하면 연결리스트로 데이터들을 연결하는 방식이다.
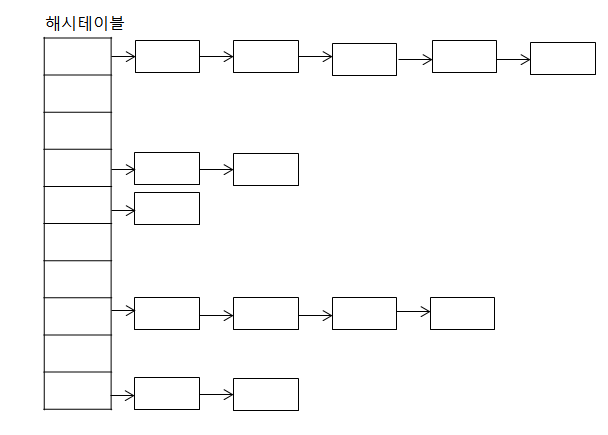
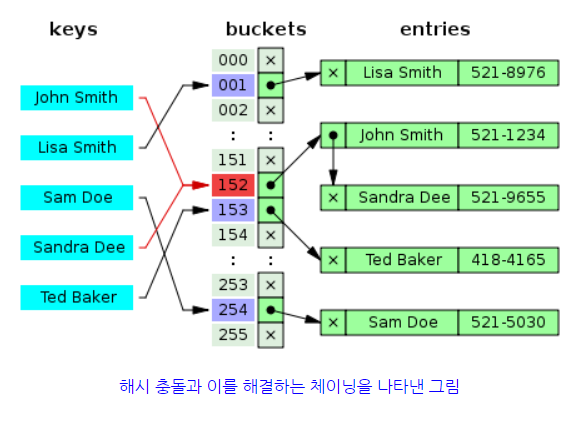
두개 비교
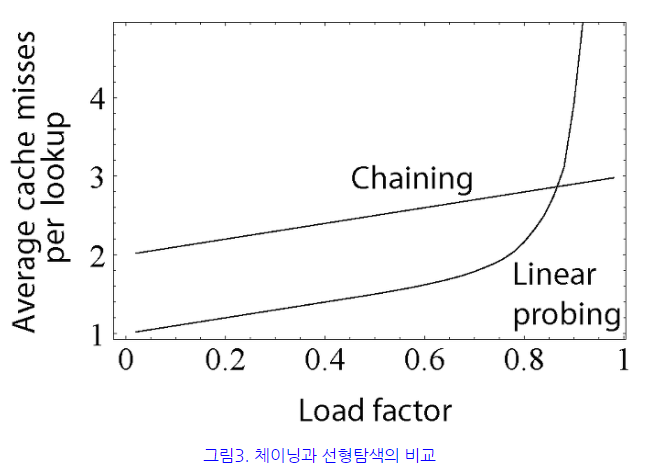
- 체이닝은 복잡한 계산식을 사용할 필요가 없다. 하지만 해시테이블이 채워질수록, Lookup 성능저하가 Linear하게 발생한다.
- 개방주소법은
체이닝처럼 포인터가 필요없고, 지정한 메모리 외 추가적인 저장공간도 필요없다, 삽입,삭제시 오버헤드가 적다, 저장할 데이터가 적을 때 더 유리하다.

HelloWorld에서 RealWorld로