
3-1 강 소스코드와 명령어
컴퓨터는 명령어를 처리하는 기계
그렇다면 개발자가 입력한 소스코드를 컴퓨터는 어떻게 명령어로 인식을 하는가?
고급언어, 저급언어
고급언어 : 자바, C++, C, Python (개발자가 읽기 쉬운 언어)
저급언어(명령어) : 컴퓨터가 이해하는언어 >
저급언어
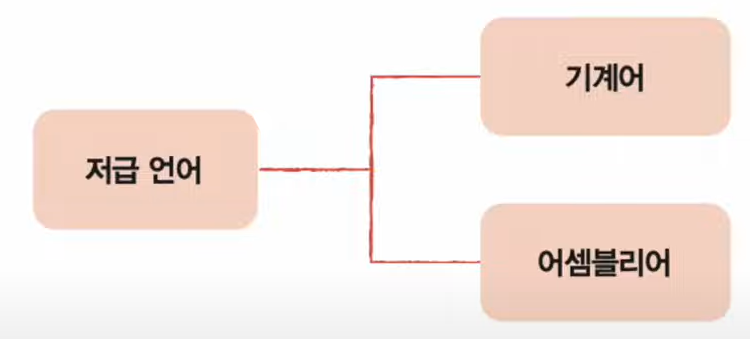
1. 기계어


-> 사람이 읽을 순 없어..
이를 사람이 읽기 쉬운 형태로 번역한 언어가 필요..
2. 어셈블리언어
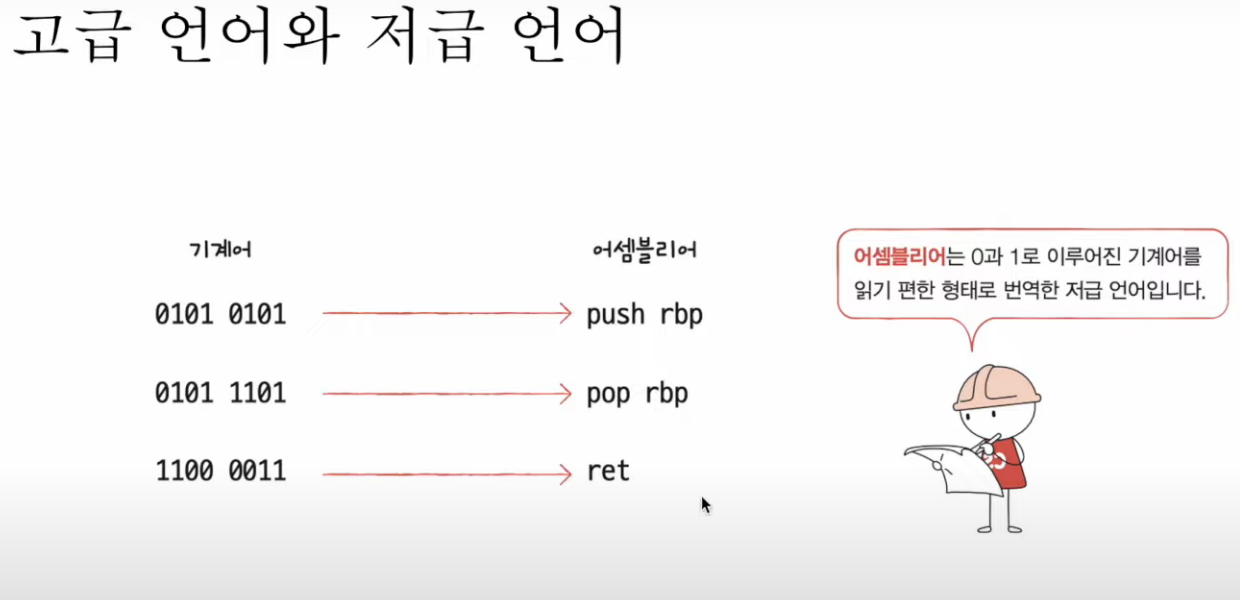
- 어셈블리어는 한줄 한줄이 명령어!
🎇 하드웨어와 밀접하게 맞닿아있는 프로그램을 개발해는 임베디드 개발자, 게임 개발자, 정보보안 분야에서는 어셈블리어를 통한 개발에 많이 사용된다! 또한 '관찰'의 대상의 하나로 프로그램의 수행 절차를 확인 할 수 있다.
고급언어 변환 과정

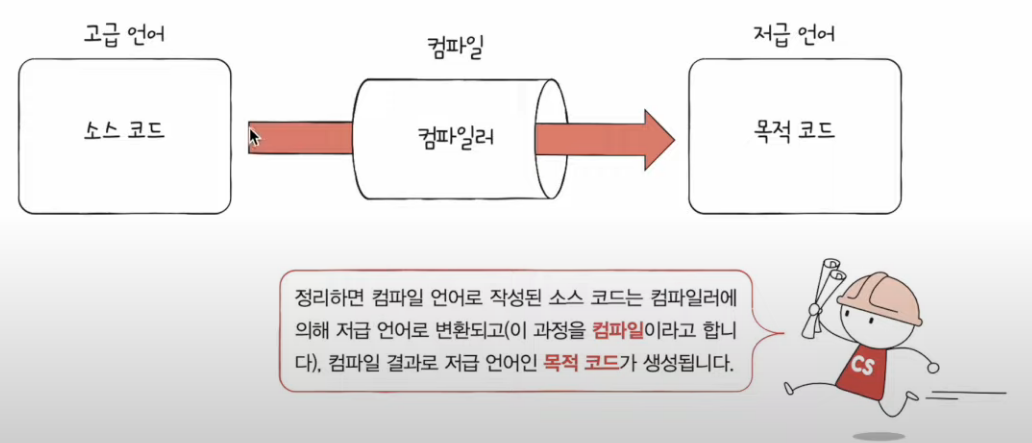
컴파일 언어
컴파일 : 소스코드가 저급언어로 변환되는 과정.
처음부터 끝까지 통째로 진행.
- 만약 소스 코드내 문법, 실행가능한 코득, 불필요한코드인지 검사하며 처음부터 끝까지 실행하다가 오류를 하나라도 발견하면 해당 소스코드는 컴파일에 실패함!!
인터프리트 언어 :
- 인터프리터에 의해 한줄씩 실행됨.
- 소스코드 전체가 저급언어로 변환되기까지 기다릴 필요가 없음.
- 오류 전까지 실행!

🎇 일반적으로 인터프리터 언어는 컴파일 언어보다 느리다. 하지만 컴파일언어와 인터프리터 언어의 구분이 모호한 언어도 있다.
C, C++ 은 구분이 명확, BUT Java의 경우 컴파일과 인터프리트를 동시 수행, 즉 언어가 반드시 하나의 방식으로만 작동하는 것은 아니다!
#### 컴파일, 인터프리터 변환 과정
목적파일 vs 실행파일
- 목적파일 : 목적코드로 이루어진 파일
목적코드가 실행 파일이 되기 위해서는 링킹이라는 작업이 필요
main.c
helper.c에있는 HELPER_더하기
화면_출력 라이브러리helper.c
HELPER_더하기컴파일 언어로 구성된 main.c와 helper.c라는 두개의 소스 코드가 작성되었을 시 각각의 목적파일은 helper.o, main.o가 생성.
but main.o는 바로 실행이 되지 않음. main.o에 없는 외부 기능들, helper.c의 더하기 기능과 화면_출력 기능을 main.o에 연결 짓는 작업이 필요함. 이러한 연결 작업을 링킹
그래서! 링킹 작업이 끝나야 하나의 실행파일이 생성됨.
3-2 강 명령어의 구조
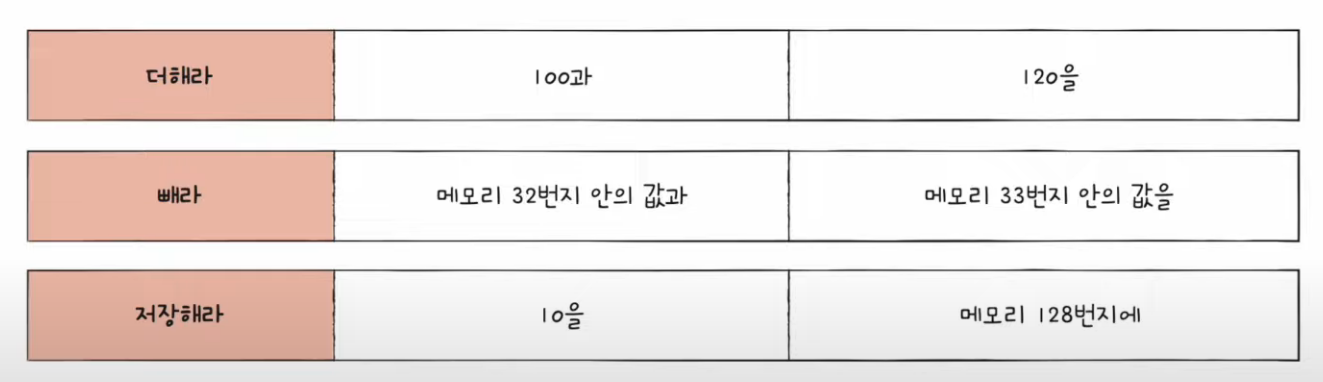
- 하나의 명령어를 자세히 보면 연산코드, 오퍼랜드, 주소지정 방식!
명령어의 구조
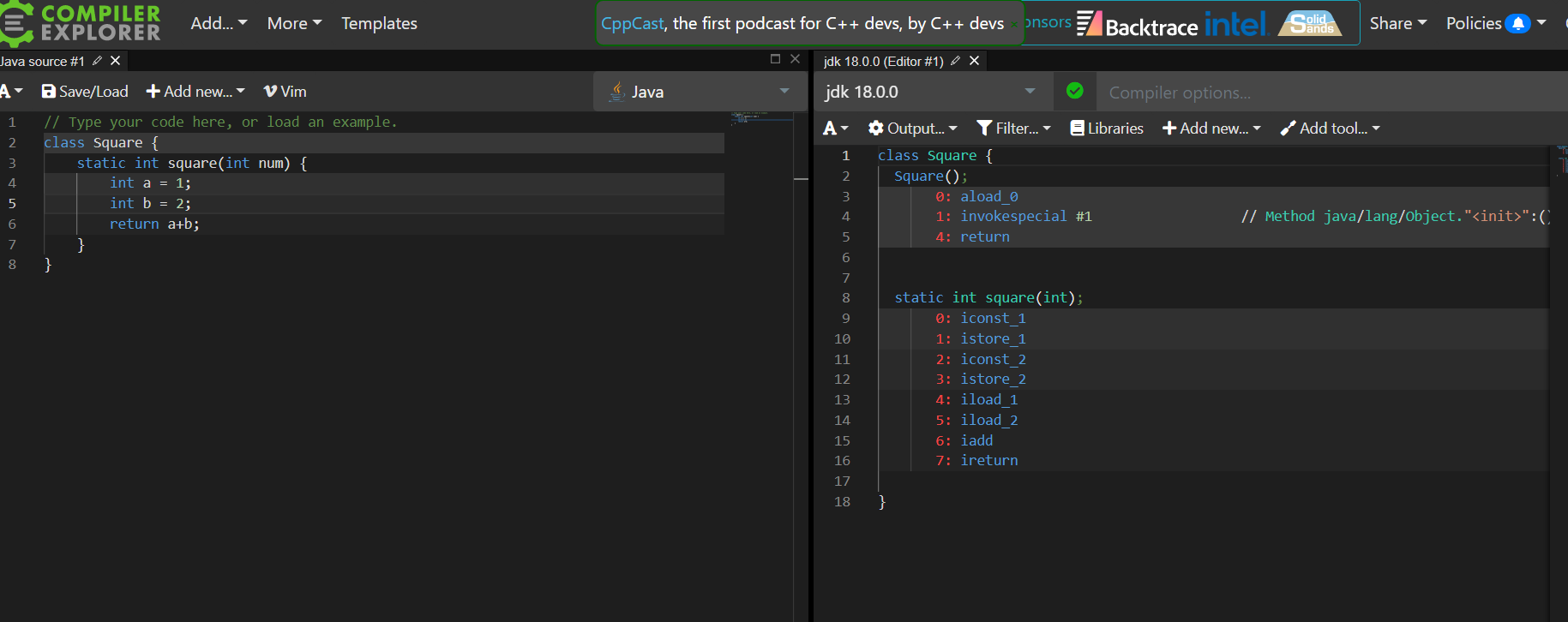
무엇을 대상으로, 무엇을 수행해라!
- 연산코드 : 명령의 작동(더해라, 빼라 ,저장해라) / 연산자 라고도 함
- 오퍼랜드 : 연산에 필요한 데이터 or 연산에 필요한 데이터가 담긴 주소 / 피연산자 라고도 함
명령어는 연산코드 + 오퍼랜드

- 여기서 어셈블리어에서 붉은 색은 연산코드, 검은 색은 오퍼랜드.

오퍼랜드 란?
- 연산에 사용될 데이터 or 연산에 사용될 데이터가 저장된 위치
- 대부분 데이가 저장된 위치를 자주 저장함(그래서 주소필드 라고도 함)

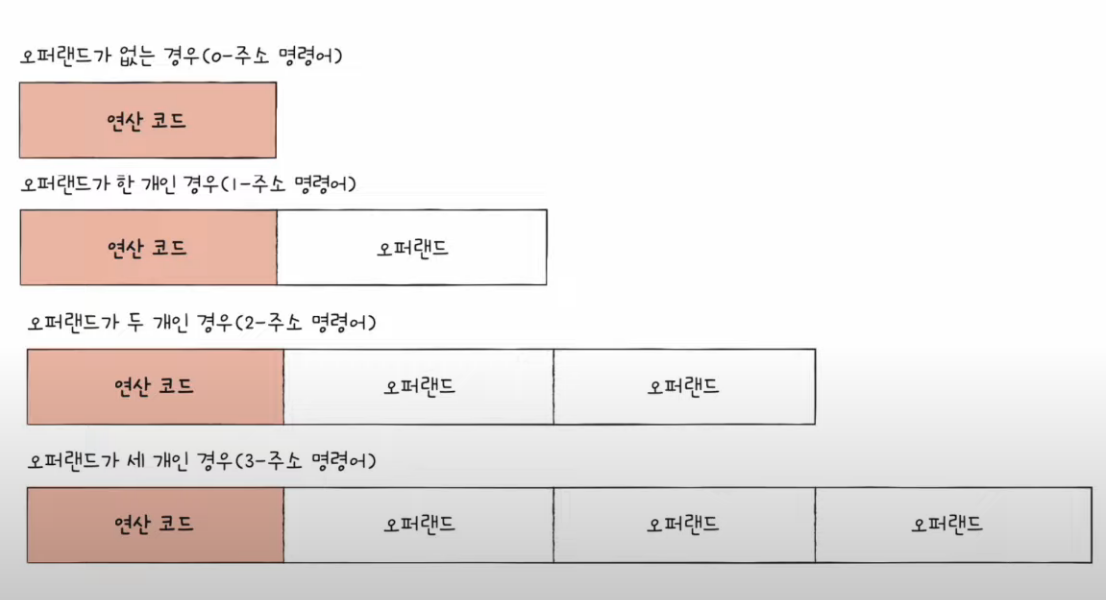
오퍼랜드가 없는 경우도 있다!
연산코드 란?
🎇CPU마다 종류 & 생김새가 다르다.. 하지만 대부분 가지고 있는 것들은 다음과 같다!
- 데이터 전송
- 산술/논리연산
- 제어 흐름 변경
- 입출력 제어
추가적인 CPU정보
1. 데이터 전송

Stack의 자료구조(한쪽끝이 막혀있는 자료구조!)
가장 마지막으로 들어간 애가 나오는 구조
Queue의 자료구조(양쪽끝이 열린 자료구조!)
먼저들어간 애가 먼저 나오는 구조
2. 산술/논리 연산

3. 제어 흐름 변경
- 특정 메모리 주소로 옮기는 것
- CALL, RETURN은 함수 호출 및 RETURN이라고 생각하면 됨~

4. 입출력제어

주소지정방식
오퍼랜드에 왜 직접적으로 데이터를 담기보다는 주소로 지정을 할까?
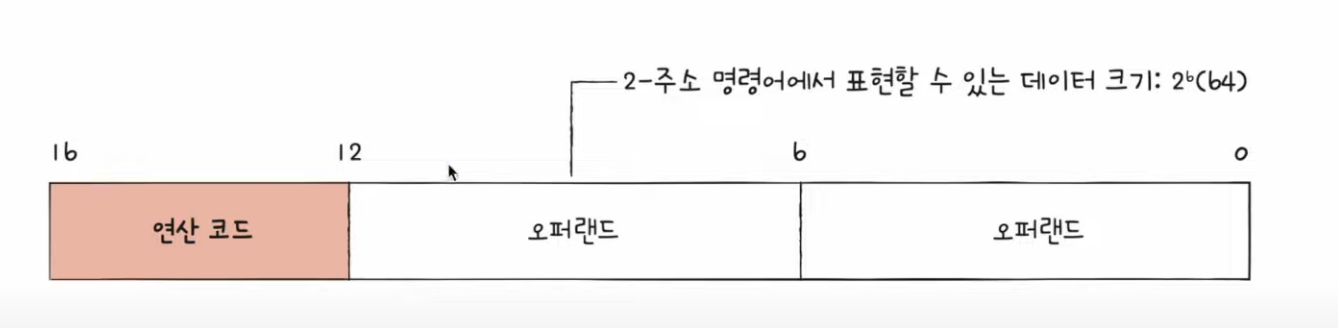
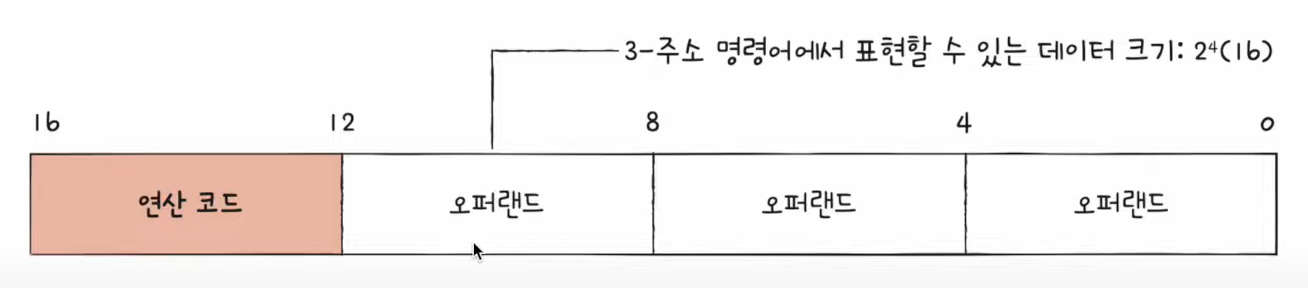
- 오퍼랜드에 저장할 수 있는 데이터크기는 작아 큰수를 표현하기 어려움.. 그래서 주소를 넣으면 정보의 제한크기가 늘어남.
- 오퍼랜드가 늘어 날수록 각 오퍼랜드에 저장할 크기가 줄어듬.
- 주소로 표현하면 데이터 크기가 확 늘어남!!
- CPU의 레지스터에 저장할 수도 있음.
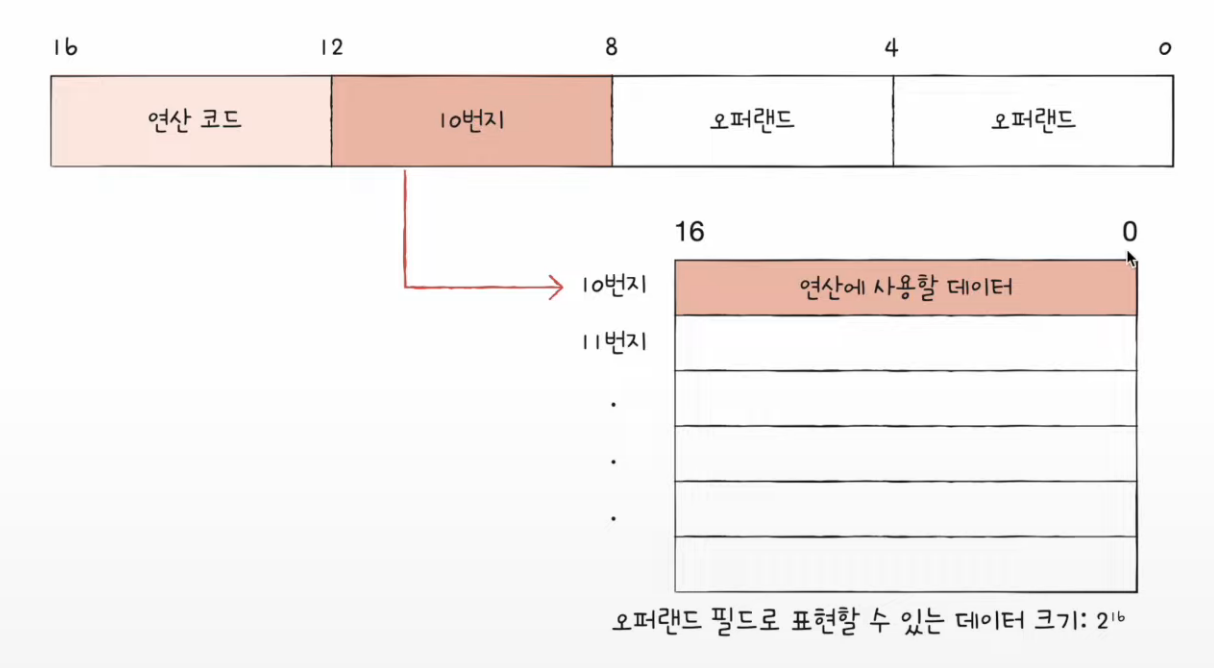
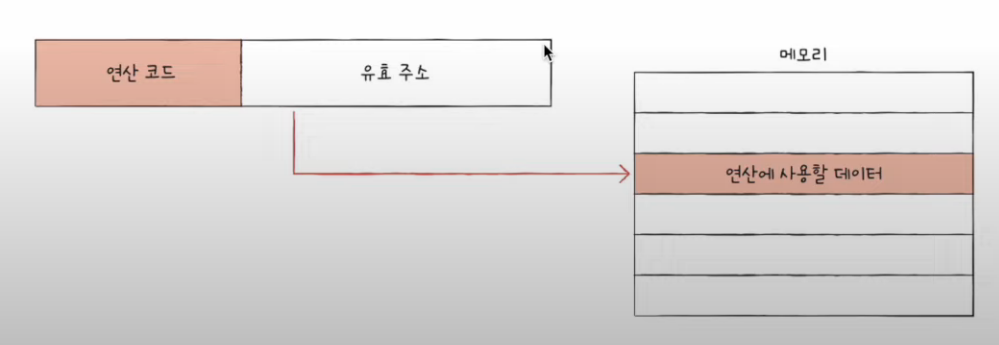
유효주소 : 연산에 사용할 데이터가 저장된 위치
위 그림에서 유효주소는 10번지
명령어 주소 지정 방식
- 연산에 사용할 데이터가 저장된 위치를 찾는 방법
- 유효 주소를 찾는 방법
- 다양한 명령어 주소 지정 방식들 ...
1) 즉시 주소 지정 방식(immediate addressing mode)
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접명시
- 가장 간단한 형태의 주소 지정 방식
- 연산에 사용할 데이터의 크기가 작아질 수 있지만 빠르다.
2) 직접 주소 지정 방식(direct addressing mode)
- 오퍼랜드 필드에 유효 주소 직접적으로 명시
- 유효주소를 표현할 수 있는 크기가 연산코드 만큼 줄어듦
- 즉, 오퍼랜드 필드의 길이가 연산 코드의 기링만큼 짧아져 표현할 수있는 유효 주소에 제한이 생길수 있다!
3) 간접 주소 지정 방식(indirect addressing mode)
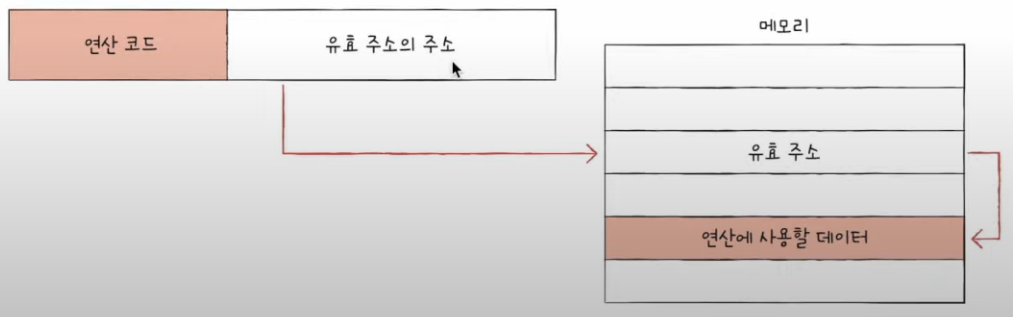
- 오퍼랜드 필드에 유효 주소의 주소를 명시
- 다만 앞선 주소지정 방식들에 비해 속도가 느림.
- 메모리 접근을 많이하기 때문에.. 하지만 유효주소를 충분히 크게 가능함
cpu가 메모리 뒤적거리는 시간은 매우 느리다~
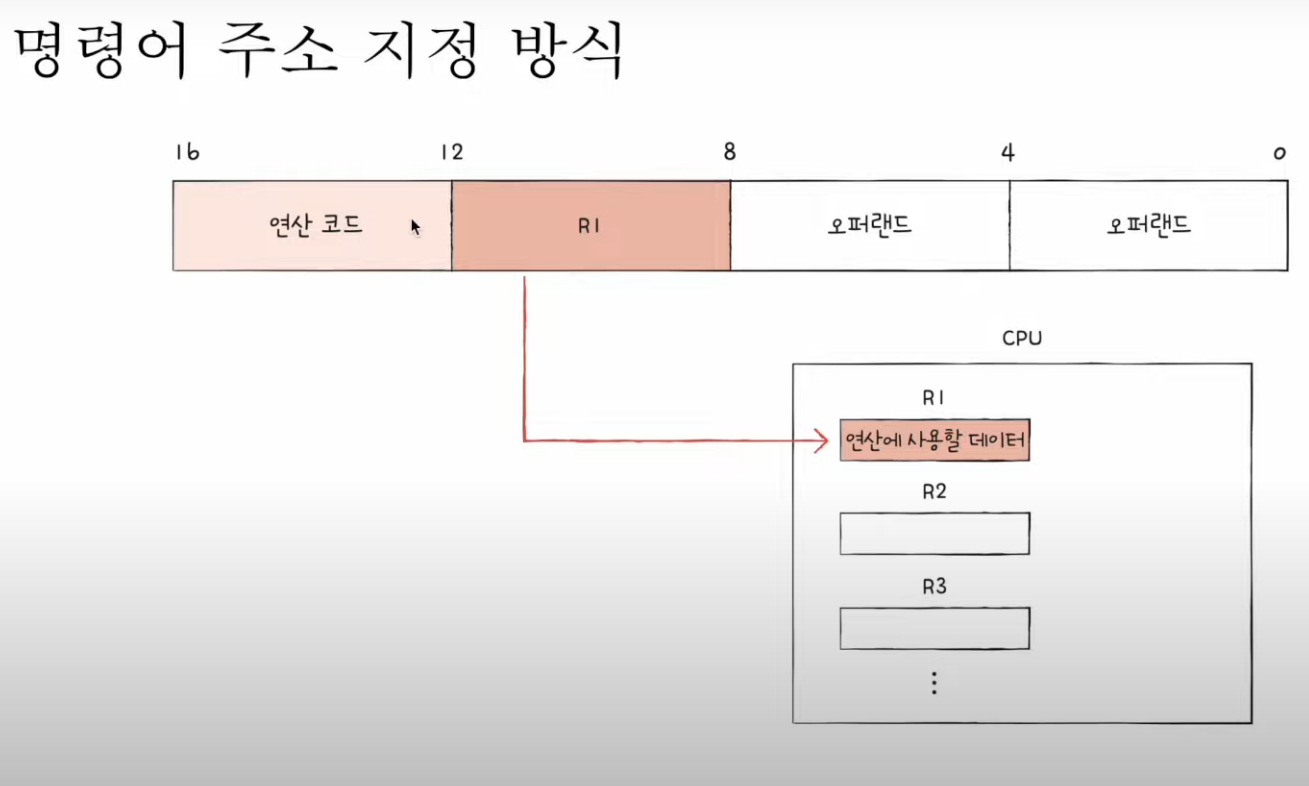
4) 레지스터 주소 지정 방식(register addressing mode)
- 연산에 사용할 데이터가 저장된 레지스터에 명시
- 당연히 CPU는 레지스터 안에 있기때문에 접근속도가 메모리보다 빠름.
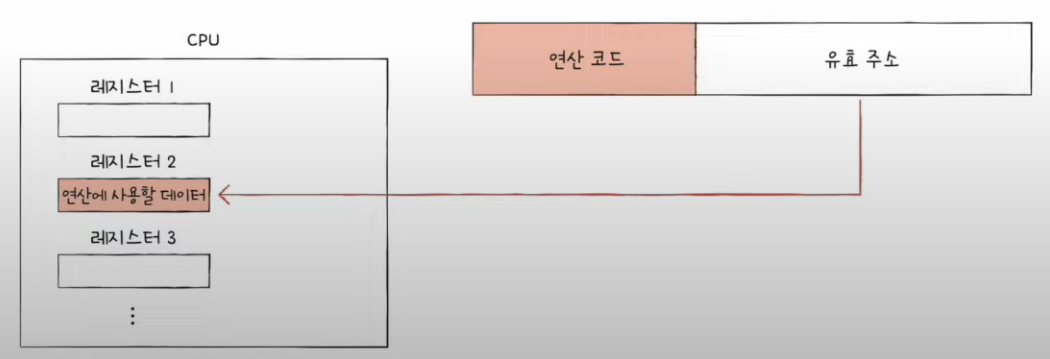
5) 레지스터 주소 지정 방식
- 연산에 사용할 데이터가 저장된 레지스터 명시!
- 메모리에 접근하는 속도보다 레지스터에 접근하는 것이 빠르다!!
- 하지만 결국 직접 주소방식처럼 레지스터 크기에 재한이 생길수 있음.
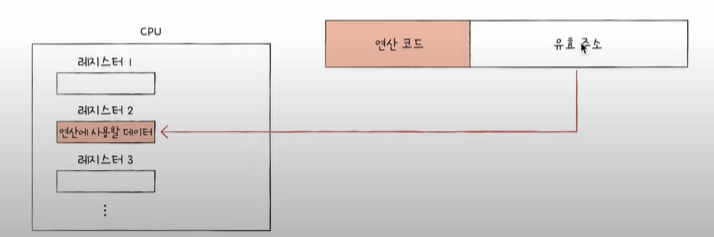
6) 레지스터 간접 주소 지정 방식
- 연산에 사용할 데이터를 메모리에 저장
- 그 주소를 저장한 레지스터를 오퍼랜드 필드에 명시
- 간접 주소 지정 방식보다는 빠르다

정리
오퍼랜드 필드 값에 저장하는 값들
- 즉시 주소 지정 방식 : 연산에 사용할 데이터
- 직접 주소 지정 방식 : 유효주소 (메모리 주소)
- 간접 주소 지정 방식 : 유효주소의 주소
- 레지스터 주소 지정 방식 : 유효주소(레지스터 이름)
- 레지스토 간접 주소 지정 방식: 유효주소를 저장한 레지스터
