
LV3.추석 트래픽
https://programmers.co.kr/learn/courses/30/lessons/17676
예제확인
문제 설명
이번 추석에도 시스템 장애가 없는 명절을 보내고 싶은 어피치는 서버를 증설해야 할지 고민이다. 장애 대비용 서버 증설 여부를 결정하기 위해 작년 추석 기간인 9월 15일 로그 데이터를 분석한 후 초당 최대 처리량을 계산해보기로 했다. 초당 최대 처리량은 요청의 응답 완료 여부에 관계없이 임의 시간부터 1초(=1,000밀리초)간 처리하는 요청의 최대 개수를 의미한다.
입력 형식
- 입력으로 들어오는
line배열은1<=N<=2,000개의 로그 문자열로 되어있으며, 응답완료시간S와 처리시간T로 되어있다.- 응답완료시간
S는 고정길이2016-09-15 hh:mm:nn.nns형식으로 되어있다.
(예: 2016-09-15 03:10:33.020 0.011s)- 처리시간은 시작시간과 끝시간을 포함한다.
lines배열은 응답완료시간 S를 기준으로 오름차순 정렬되어 있다.
출력 형식
solution함수에서는 로그 데이터lines배열에 대해 초당 최대 처리량을 리턴한다.
문제 살펴보기
자료형
- 먼저 시간정보를 담은 로그데이터가 들어오니,
datetime모듈의datetime, timedelta모듈을 사용한다.✨datetime
from datetime import datetime, timedelta string = "2016-09-15 20:59:57.421" print(datetime.strptime(string, "%Y-%m-%d %H:%M:%S.%f")) #%s에서 .%f를 추가하여 초 에 소숫점 자리까지 표현한다. #2016-09-15 20:59:57.421000
✨timedelta
from datetime import datetime, timedelta string = "2016-09-15 20:59:57.421" time = datetime.strptime(string, "%Y-%m-%d %H:%M:%S.%f") print(time) #2016-09-15 20:59:57.421000 process_time = timedelta(seconds=10) #timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0) print(time + process_time) #2016-09-15 21:00:07.421000
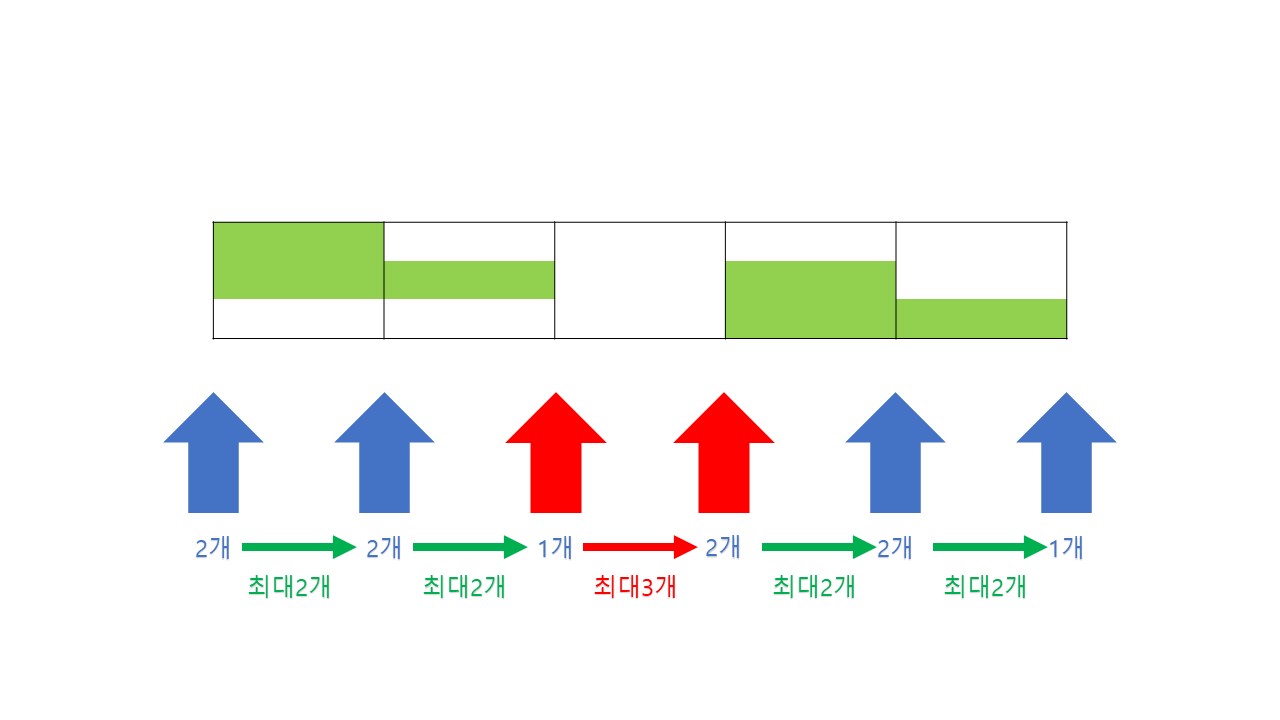
- 또, 1초간격으로 구간을 설정하게 되는데 끝시간과 시작시간을 포함하므로, 구간의 설정은 모든 시작시간과 끝시간을 시작으로 하는 1초 간격의 구간으로 검사해야한다.
- 위 그림과 같은 상황에서 끝시간과 다음 트래픽의 시작시간을 포함하여 한 구간에 3개의 트래픽으로 잡힐 수 있다. 따라서 끝시간, 시작시간 둘다 구간의 시작점으로 가정해야하며, 빠른 순서대로 하나씩 꺼내쓰기 위해 힙을 사용한다.
✨heapq
import heapq heap = [] for i in range(5, 0, -1): heapq.heappush(heap, i) print(heap) #[1, 2, 4, 5, 3] for i in range(5): print(heapq.heappop(heap)) #1, 2, 3, 4, 5
문제 풀기
코드
from datetime import datetime, timedelta
import heapq
def cutTimes(line): #트래픽의 시작시간과 끝시간을 datetime형 리스트로 반환한다.
split_line = line.split(' ')
time = split_line[0] + ' ' + split_line[1]
interval = float(split_line[2][:-1])
end = datetime.strptime(time, "%Y-%m-%d %H:%M:%S.%f")
start = end - timedelta(seconds=interval-0.001) #시작시간 포함이기 떄문에 0.001초 빼준다.
return [start, end]
def solution(lines):
queue = []
heap = []
interval = timedelta(seconds=0.999) #시작시간이 포함이기 떄문에 간격은 1초-0.001초로 한다.
for line in lines: #모든 트래픽을 datetime형으로 바꾸고, queue와 heap에 넣어준다.
start, end = cutTimes(line)
queue.append([start, end])
heapq.heappush(heap, start)
heapq.heappush(heap, end)
answer = 1
for i in range(len(heap)):
start = heapq.heappop(heap) #트래픽의 시작, 끝시간 둘가 구간의 시작이 될 수 있다.
end = start+interval #구간의 끝점
max_count = 0
for item in queue: #구간에 조금이라도 걸치면 max_count += 1
if((start <= item[0] <= end) or (start <= item[1] <= end) or ((item[0]<=start) and (end<=item[1]))):
max_count += 1
answer = max_count if answer<max_count else answer #answer이 max_count보다 작으면 answer = max_count
return answer
Talking Potato