오늘 할일
- 분석데이터 RDS 저장
- EMR 생성
- EMR에서 RDS데이터 가져오기
분석데이터 RDS 저장
데이터 추가
- 어제 생성한 데이터에 이어서 진행한다.
data_path = '/content/drive/MyDrive/Colab Notebooks/Custommer2.csv' item_df = pd.read_csv(data_path, index_col='Unnamed: 0') item_df.head()
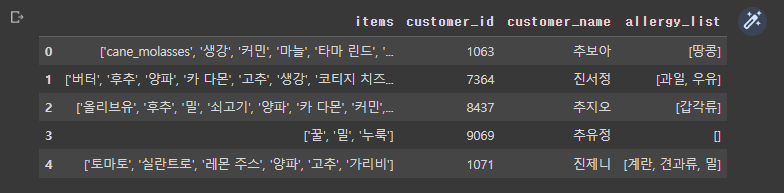
allergy_list = ['계란', '우유', '땅콩', '견과류', '밀', '갑각류', '대두', '메밀', '육류', '생선', '과일'] import random item_df['allergy_list'] = '' item_df['allergy_list'] = item_df['allergy_list'].apply(lambda x: list(set([random.choice(allergy_list) for i in range(random.randrange(0, 4))]))) item_df.to_csv('/content/drive/MyDrive/Colab Notebooks/total_Custommer.csv') item_df.head()
- 알러지 정보를 추가했다.
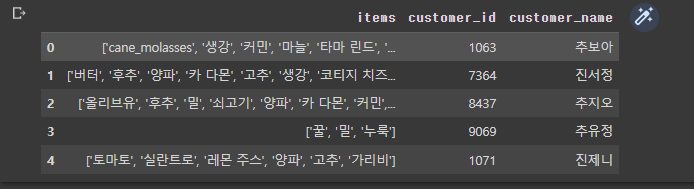
데이터 준비
- 어제 크롤링으로 생성한 데이터와 그를 번역한 최종 데이터이다.
- CSV파일로 저장해놓고 S3에 업로드 해놓는다.
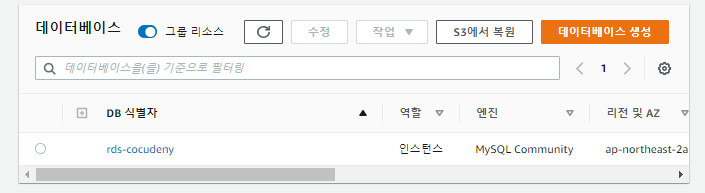
- RDS도 미리 생성해 놓았다.
- MySQL 8.0.23버전으로 프라이빗 액세스만 허용하여 생성하였다.
Cloud9
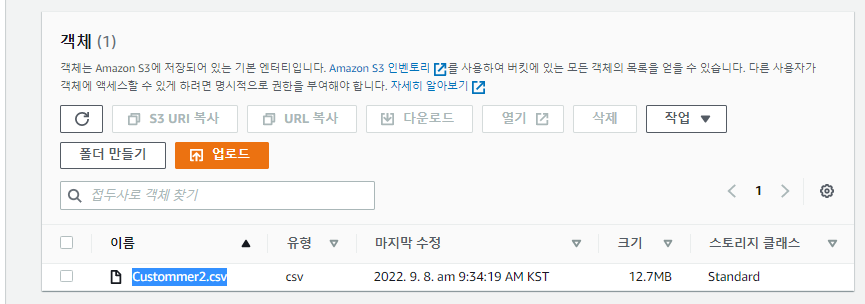
- Cloud9으로 작업하기위해 S3에서 데이터를 가져온다.
dataDownload.py
pip install boto3import boto3 bucket = 's3.cocudeny' key = 'Custommer2.csv' image_name = key.split('/')[-1] s3 = boto3.client('s3') S3_response = s3.get_object(Bucket=bucket, Key=key) print("CONTENT TYPE: " + S3_response['ContentType']) image_path = './'+image_name s3.download_file(bucket, key, image_path) print('Download is done')
- 잘 가져와졌다.
RDS에 데이터 올리기
pip install pandasimport pymysql import os import logging import sys import pandas as pd #settings data_path = '/home/ec2-user/environment/BigData/total_Custommer.csv' rds_endpoint = 'AWS RDS의 엔튿포인트' name = 'RDS 유저 이름' password = 'RDS 비밀번호' db_name = 'RDS 사용할 DB이름' table_name = '사용(생성)할 테이블이름' logger = logging.getLogger() logger.setLevel(logging.INFO) # RDS와 연결 try: conn = pymysql.connect(host=rds_endpoint, user=name, passwd=password, db=db_name, connect_timeout=5) print('connected') except pymysql.MySQLError as e: logger.error("ERROR: Unexpected error: Could not connect to MySQL instance.") logger.error(e) sys.exit(1) table_items = { 'custommer_id' : 'int not null', 'custommer_name' : 'varchar(20) not null', 'items' : 'varchar(2000)', 'allergy_list' : 'varchar(50)' } #Init Table try: ### CREATE TABLE sql_create_option = [] for k, v in table_items.items(): sql_create_option.append(k+' '+v) sql_create_option = (', ').join(sql_create_option) print('init table :',sql_create_option ) with conn.cursor() as cur: cur.execute("create table if not exists "+table_name+" ( "+sql_create_option+" )") conn.commit() print('init table successed') except pymysql.MySQLError as e: logger.error("ERROR: Init Table Error") logger.error(e) sys.exit(2) # Keys to insert form string def get_data_keys(keys): return (', ').join(keys) # datas to insert form string def get_data_vals(series): text = [] for key in ['customer_id', 'customer_name', 'items', 'allergy_list']: data = series[key] if key == 'customer_id': text.append(str(data)) else: text.append("\'" + data + "\'") return (', ').join(text) # reas CSV item_df = pd.read_csv(data_path, index_col='Unnamed: 0') item_df['items'] = item_df['items'].apply(lambda x: (', ').join([item[1:-1] for item in x[1:-1].split(', ')])) item_df['allergy_list'] = item_df['allergy_list'].apply(lambda x: (', ').join([item[1:-1] for item in x[1:-1].split(', ')])) print('CSV_read done') # collect error list error_list = [] data_keys = get_data_keys(list(table_items.keys())) # Insert all rows of DataFrame for i in range(len(item_df)): data_vals = get_data_vals(item_df.iloc[i]) command = 'insert into '+table_name+' ('+data_keys+') values('+data_vals+')' #insert Item try: with conn.cursor() as cur: cur.execute(command) conn.commit() except pymysql.MySQLError as e: logger.error("ERROR: Insert Fail.", e) print(e) error_list.append(i) print(error_list)
- 에러 없이 모두 들어갔다.
- 보기가 조금 이상하지만 잘 들어갔다.

추천시스템에 대한 조사
실시간 인기 콘텐츠, 상품 분석 모니터링
추천 시스템
- 전통적인 개인화 추천 방식에는 크게 2가지가 있다.
- 유사한 사용자들이 선호한 다른 아이템을 추천하는
collaborative Filtering방식과 과거에 선호한 아이템과 내용이 유사한 다른 아이템을 추천하는content-based Filtering방식이 있다.
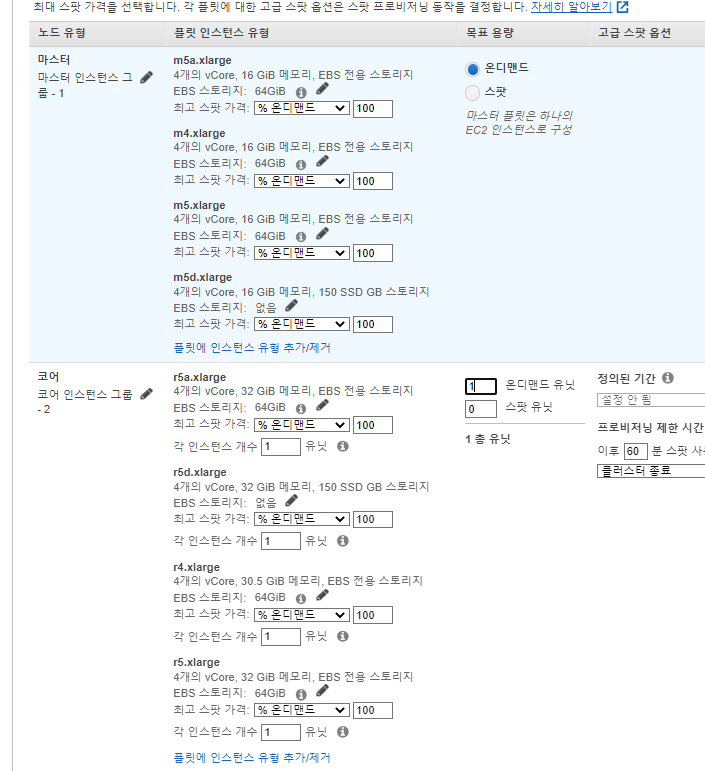
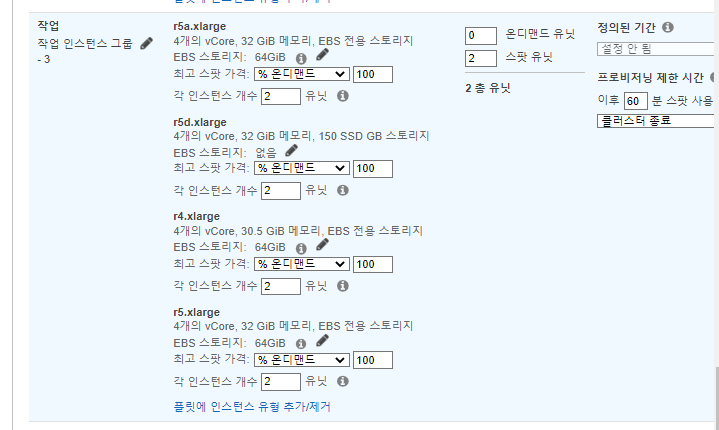
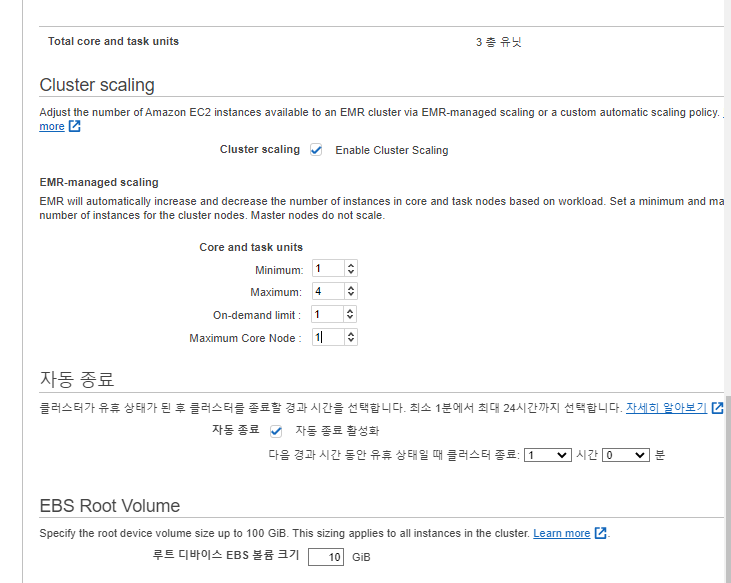
EMR 따라하기
간략한설명
- SSL 인증서를 사용하여 Hive와 외부 메타스토어 간에 암호화된 연결을 설정합니다. 새 Amazon EMR 클러스터를 시작하거나 클러스터가 실행 된 후에 이 연결을 설정할 수 있습니다.
새 Amazon EMR 클러스터에서 SSL 연결 설정
- 다음과 유사한 명령을 실행하여 Amazon RDS MySQL DB 인스턴스를 만듭니다. $RDS_LEADER_USER_NAME과 $RDS_LEADER_PASSWORD를 사용자 이름과 암호로 바꿉니다. 자세한 내용은 create-db-instance를 참조하세요.
aws rds create-db-instance --db-name hive --db-instance-identifier mysql-hive-meta --db-instance-class db.t2.micro\ --engine mysql --engine-version 5.7.19 --master-username $RDS_LEADER_USER_NAME --master-user-password $RDS_LEADER_PASSWORD\ --allocated-storage 20 --storage-type gp2 --vpc-security-group-ids $RDS_VPC_SG --publicly-accessible- 여기서 우리는 이미 존재하는 RDS를 사용할 것이다.
- 기본 사용자로 Amazon RDS MySQL DB 인스턴스에 연결합니다. 다음 예제와 같이 Hive 메타스토어에 대한 사용자를 만듭니다.
mysql -h mysql-hive-meta.########.us-east-1.rds.amazonaws.com -P 3306 -u $RDS_LEADER_USER_NAME -p
- Enter password: $RDS_LEADER_PASSWORD
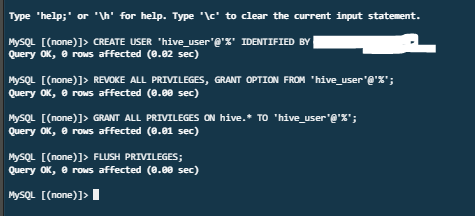
CREATE USER 'hive_user'@'%' IDENTIFIED BY 'hive_user_password'; REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'hive_user'@'%'; GRANT ALL PRIVILEGES ON hive.* TO 'hive_user'@'%' REQUIRE SSL; FLUSH PRIVILEGES;
- REQUIRE SSL 문구를 지웠다. SSL이 없기 떄문
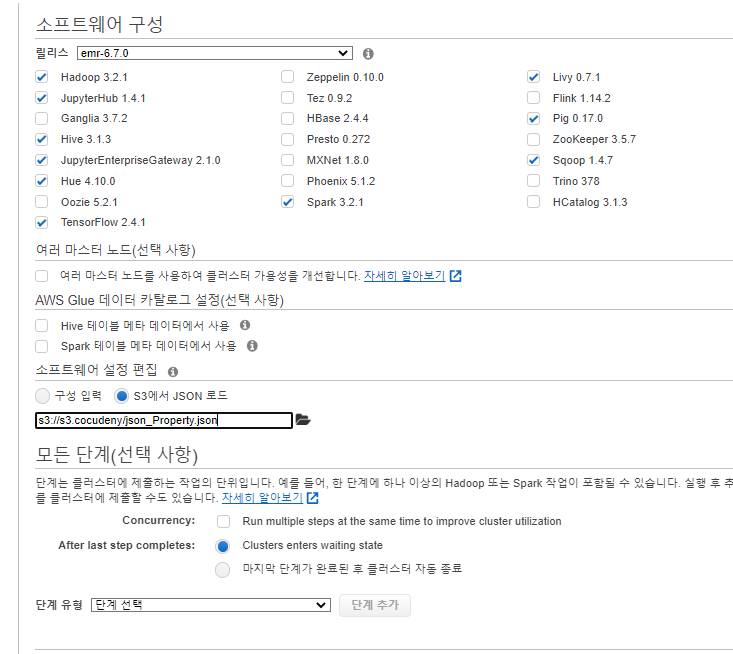
- 다음과 유사한 JSON 구성 파일을 작성합니다. hive_user 및 hive_user_password를 2단계에서 JSON 스크립트에 사용한 값으로 바꿉니다. JDBC URL의 엔드포인트를 RDS DB 인스턴스의 엔드포인트로 바꿉니다.
[ { "Classification": "hive-site", "Properties": { "javax.jdo.option.ConnectionURL": "jdbc:mysql:\/\/mysql-hive-meta.########.us-east-1.rds.amazonaws.com:3306\/hive?createDatabaseIfNotExist=true&useSSL=true&serverSslCert=\/home\/hadoop\/rds-combined-ca-bundle.pem", "javax.jdo.option.ConnectionDriverName": "org.mariadb.jdbc.Driver", "javax.jdo.option.ConnectionUserName": "hive_user", "javax.jdo.option.ConnectionPassword": "hive_user_password" } } ]
- Amazon RDS MySQL 인스턴스와 연결된 보안 그룹에서 다음 파라미터를 사용하여 인바운드 규칙을 생성합니다.
[유형(Type)]에 대해 [MYSQL/Aurora(3306)]을 선택합니다.
[프로토콜(Protocol)]의 경우 [TCP(6)]가 기본적으로 선택됩니다.
[포트 범위(Port Range)]의 경우 [3306]이 기본적으로 선택됩니다.
[소스(Source)]에 리더 노드와 연결된 Amazon EMR에서 관리하는 보안 그룹의 [그룹 ID(Group ID)]를 입력합니다.
- 아직 EMR을 생성하지 않았기 때문에 모든 IPv4주소를 열었다.
- create-cluster 명령을 실행하여 3단계의 JSON 파일과 부트스트랩 작업을 함께 사용하여 Amazon EMR 클러스터를 시작합니다. 부트스트랩 작업은 리더 노드의 /home/hadoop/에 SSL 인증서를 다운로드합니다.
aws emr create-cluster --applications Name=Hadoop Name=Hive --tags Name="EMR Hive Metastore"\ --ec2-attributes KeyName=$EC2_KEY_PAIR,InstanceProfile=EMR_EC2_DefaultRole,SubnetId=$EMR_SUBNET,EmrManagedSlaveSecurityGroup=$EMR_CORE_AND_TASK_VPC_SG,EmrManagedMasterSecurityGroup=$EMR_MASTER_VPC_SG\ --service-role EMR_DefaultRole --release-label emr-5.18.0 --log-uri s3://awsdoc-example-bucket/emr-logs-path/ --name "Hive External Metastore RDS MySQL w/ SSL"\ --instance-groups InstanceGroupType=MASTER,InstanceCount=1,InstanceType=m3.xlarge,Name="Master - 1"\ --configurations file://hive-ext-meta-mysql-ssl.json\ --bootstrap-actions Path=s3://elasticmapreduce/bootstrap-actions/run-if,Args=["instance.isMaster=true","cd /home/hadoop && wget -S -T 10 -t 5 https://s3.amazonaws.com/rds-downloads/rds-combined-ca-bundle.pem"]
- 잘 안되서 콘솔에서 직접 생성하였다.
- 부트스트랩은 안되서 일단 제외시킨다.
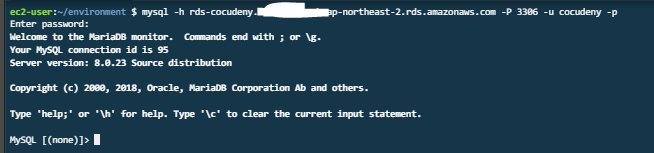
- SSH를 사용하여 리더 노드에 연결합니다.



Talking Potato