오늘의 할일
- S3에서 Lambda로 이미지 가져오기
- 가져오는것 확인하고 RDS연결
- 최종 S3toRDS 확인
- 개발자 작업환경 아키텍처 구성 및 CI/CD화
- https://aws.amazon.com/ko/blogs/compute/new-deployment-options-for-aws-lambda/
- Auto lambda deploy with s3
S3에서 Lambda로 이미지 가져오기
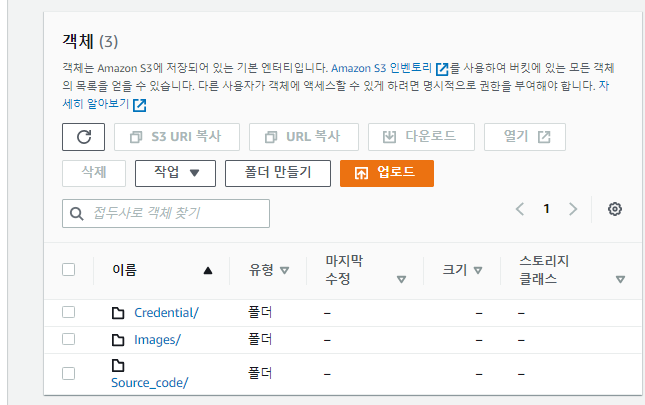
S3 생성
- Credential: GCP API Credential을 업로드할 폴더
- Images: 이미지가 업로드될 폴더
- Source_code: Lambda테스트코드를 업로드할 폴더
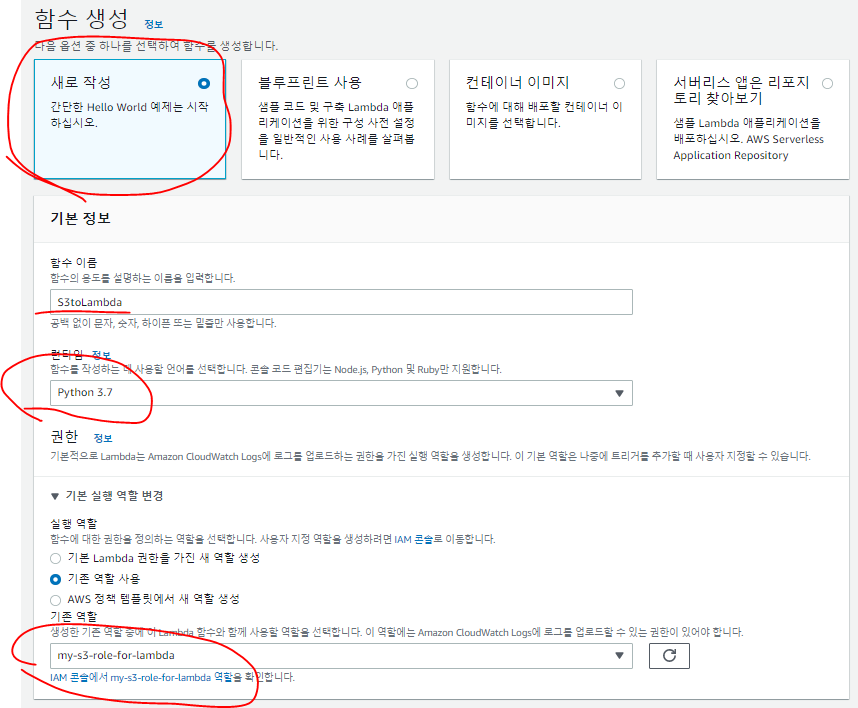
Lambda함수 생성
테스트코드 S3를 통해 Lambda에서 Deploy하기
- 현재 계속 작업하고 있는 Cloud9을 통해 코드를 작성하고 배포하고있다.
lambda_function.py
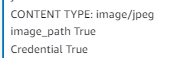
import sys import os from struct import pack import json import urllib.parse import boto3 print('Loading function') s3 = boto3.client('s3') def detect_document(path): """Detects document features in an image.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() # [START vision_python_migration_document_text_detection] with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.document_text_detection(image=image) if response.error.message: raise Exception( '{}\nFor more info on error messages, check: ' 'https://cloud.google.com/apis/design/errors'.format( response.error.message)) # [END vision_python_migration_document_text_detection] return response.full_text_annotation.pages[0].blocks def lambda_handler(event, context): text_data = [] print("Received event: " + json.dumps(event, indent=2)) # Get the object from the event and show its content type bucket = event['Records'][0]['s3']['bucket']['name'] key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') image_name = key.split('/')[-1] image_path = '/tmp/'+image_name credential_key = 'Credential/fabled-meridian-352009-e226c97ba30a.json' credential_name = credential_key.split('/')[-1] credential_path = '/tmp/'+credential_name os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credential_path try: S3_response = s3.get_object(Bucket=bucket, Key=key) print("CONTENT TYPE: " + S3_response['ContentType']) image_path = '/tmp/'+image_name s3.download_file(bucket, key, image_path) s3.download_file(bucket, credential_key, credential_path) except Exception as e: print(e) print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket)) raise eS3에 업로드하기
zip -r ../lambda_source.zip *aws s3 cp ../lambda_source.zip s3://s3.cocudeny/Source_code/
S3 -> Lambda연결하기
에러
- 이렇게 에러가나온다.
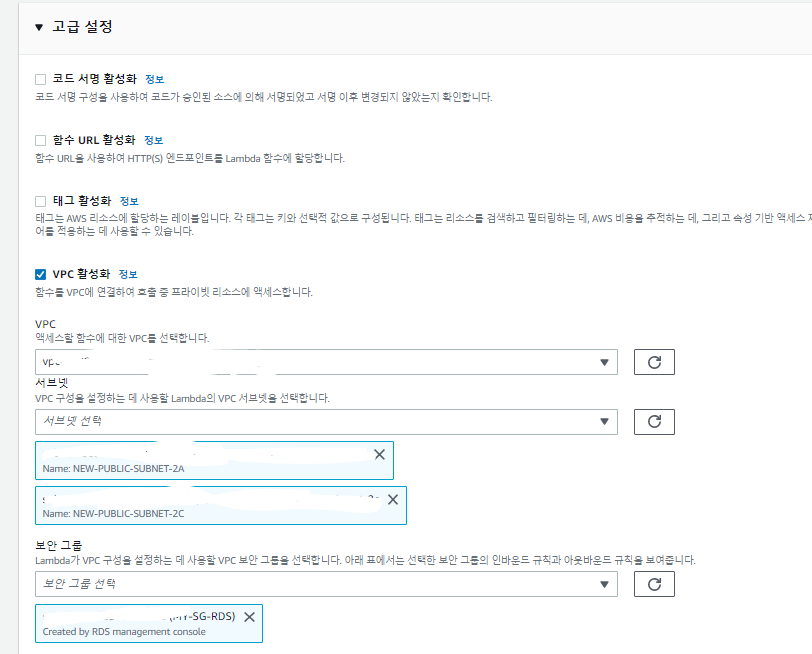
- 혹시,,,, RDS연결때문에 VPC에 연결해서 그런것일까?
- 그래서 네트워크에 퍼블릭으로 연결되어 그런것일까?
- 그렇기엔 Public서브넷에서 생성된 Cloud9이 잘 돌아간다.


가정1
- VPC에 연결했기 때문인가?
- 그렇다면 VPC를 연결하지 않은 Lambda로 테스트해보자.
- VPC를 연결하지 않은 Lambda는 S3의 파일을 빠르게 받아오는 것을 볼 수 있다.
- VPC에 연결되지 않은걸까?
- Cloud9에는 위와같은 Credential이 존재한다.
- Lambda -> RDS 테스트를해본다.
Lambda -> RDS 연결하기
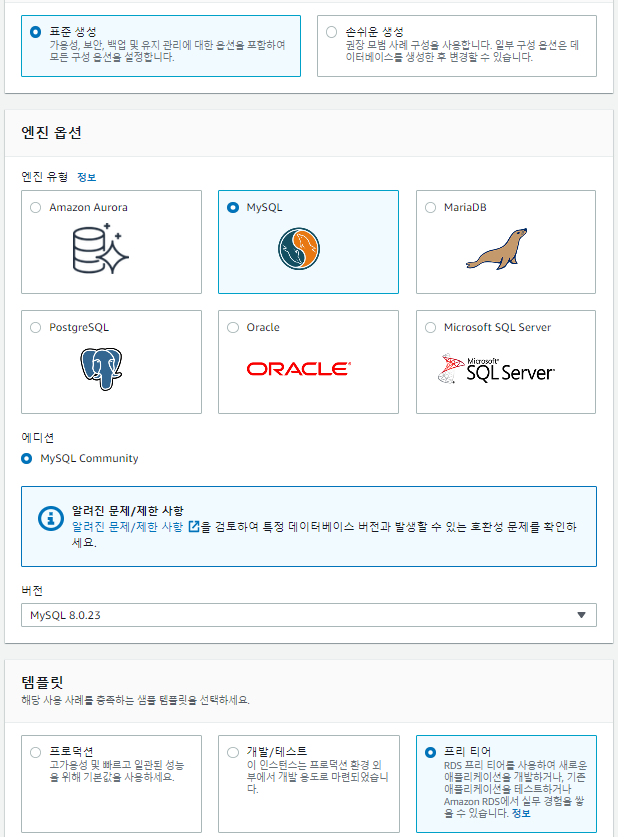
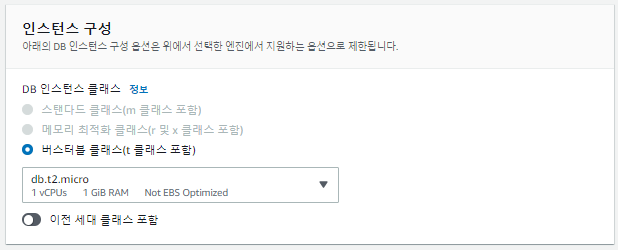
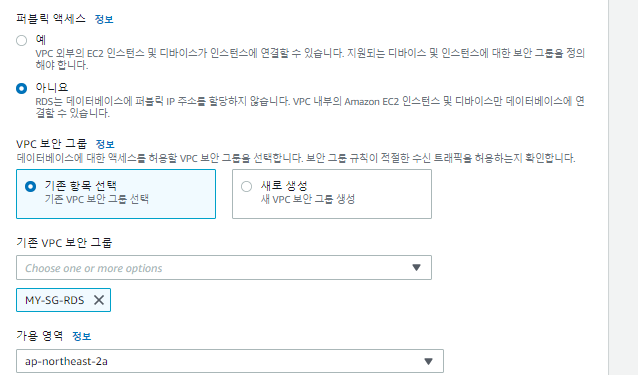
RDS생성
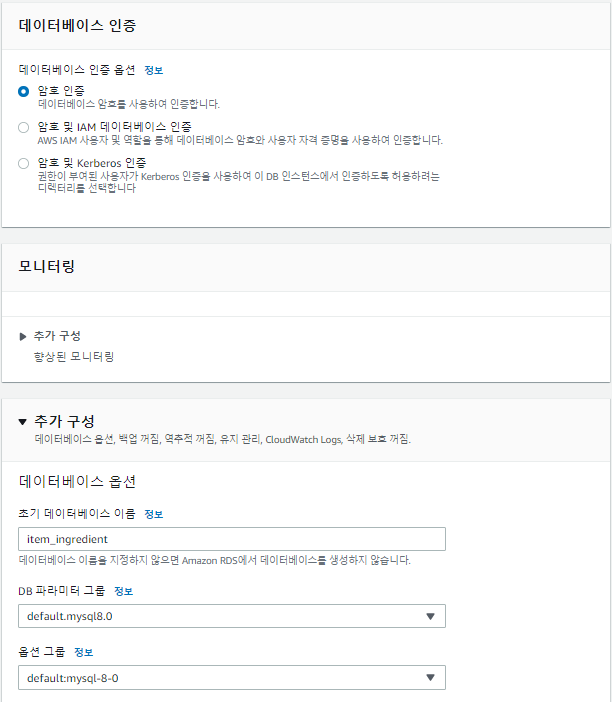

RDS연결 테스트 Lambda Code
lambda_function.py
import json import sys import logging import rds_config import pymysql import os #rds settings rds_host = rds_config.rds_endpoint name = rds_config.db_username password = rds_config.db_password db_name = rds_config.db_name logger = logging.getLogger() logger.setLevel(logging.INFO) try: conn = pymysql.connect(host=rds_host, user=name, passwd=password, db=db_name, connect_timeout=5) print('connected') except pymysql.MySQLError as e: logger.error("ERROR: Unexpected error: Could not connect to MySQL instance.") logger.error(e) sys.exit() logger.info("SUCCESS: Connection to RDS MySQL instance succeeded") def lambda_handler(event, context): """ This function fetches content from MySQL RDS instance """ item_count = 0 with conn.cursor() as cur: #cur.execute("create table if not exists Employee ( EmpID int NOT NULL, Name varchar(255) NOT NULL, PRIMARY KEY (EmpID))") #cur.execute('insert into Employee (EmpID, Name) values(1, "Joe")') #cur.execute('insert into Employee (EmpID, Name) values(2, "Bob")') #cur.execute('insert into Employee (EmpID, Name) values(3, "Mary")') #conn.commit() cur.execute("select * from Employee") for row in cur: item_count += 1 logger.info(row) #print(row) conn.commit() print("Added %d items from RDS MySQL table" %(item_count)) return "Added %d items from RDS MySQL table" %(item_count)rds_config.py
rds_endpoint = 'rds-cocudeny.cidsblwezpmk.ap-northeast-2.rds.amazonaws.com' db_username ='cocudeny' db_password = 'Kosa0401!' db_name = 'item_ingredient'S3에 업로드
zip -r ../rds_lambda_source.zip *aws s3 cp ../rds_lambda_source.zip s3://s3.cocudeny/Source_code/
- 잘 업로드 되었다.
RDS Connection Test
- It works!

현재상황 정리
- S3와 Lambda를 연결하는데 VPC를 구성하면 S3에서 데이터를 읽어오지 못한다.
- 그러나 RDS와 통신하려면 VPC를 구성해야한다.
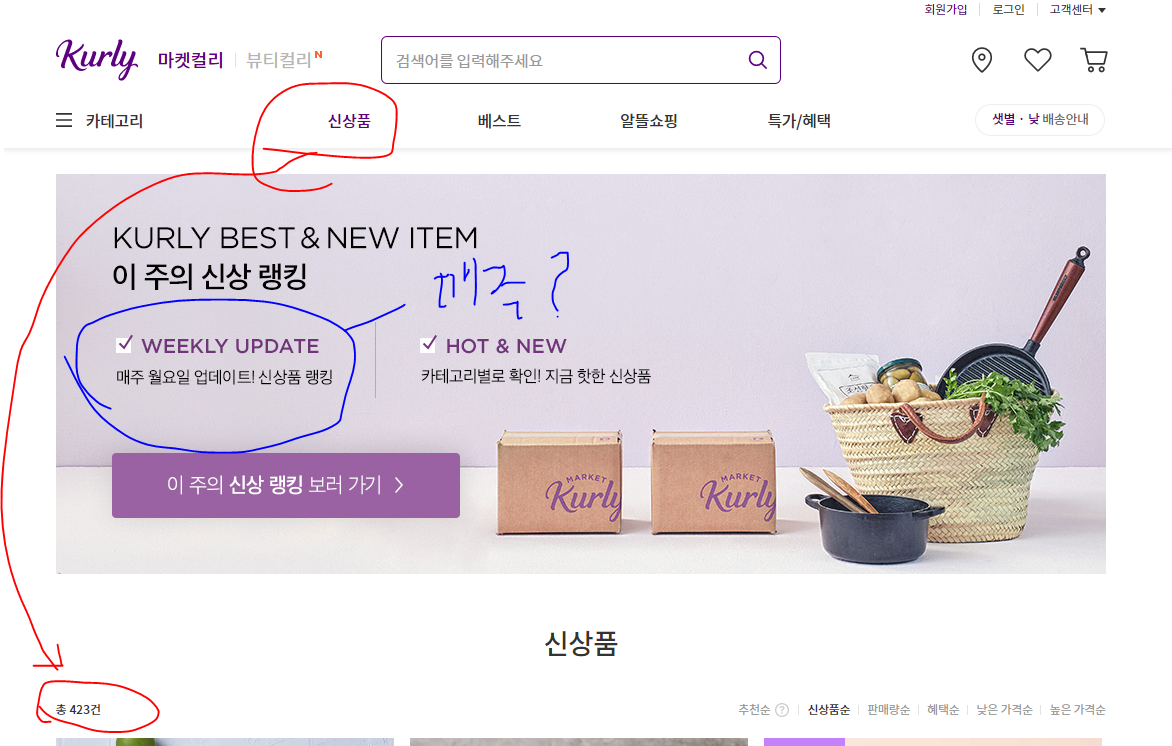
가정
- 위는 마켓컬리에서의 신상품 항목이다.
- 신상품이 어느정도의 간격을 두고 업로드 되는지 모르지만,
방법 1, Lambda 2개를 사용하기
- S3에서 이미지를 읽어와서 텍스트데이터로 가져오는 이미지 프로세싱 파트 Lambda 1개
- 받은 텍스트로 키워드를 분석해 RDS로 연결하는 Labda 1개
- 요금은?
- https://aws.amazon.com/ko/lambda/pricing/
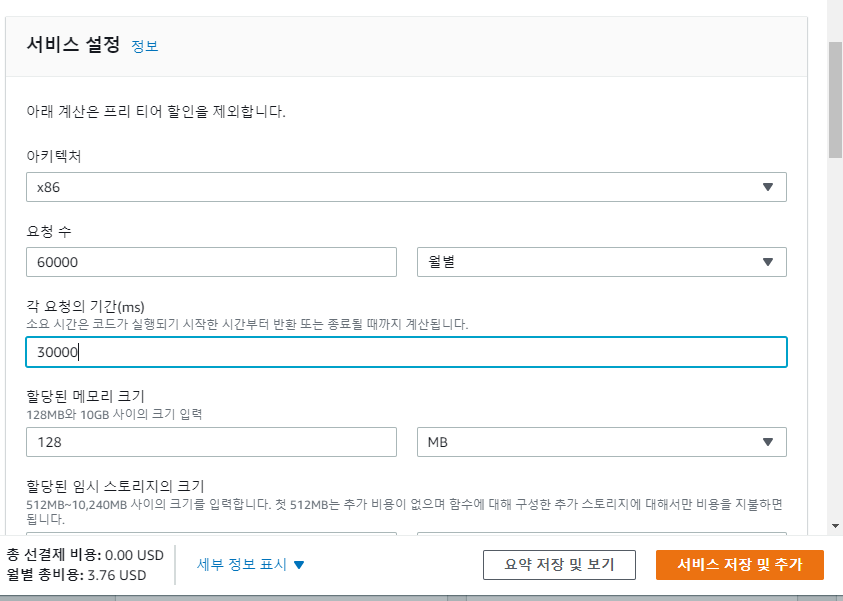
- 월 평균 요청 30000건 (Lambda를 2개사용한다면 60000건)
- 전체 프로세스에 30000ms가 소요된다고 가정할 시의 가격.
- 3.76$
- 여기에 DataTransfer요금이 부과된다.
DataTransfer요금
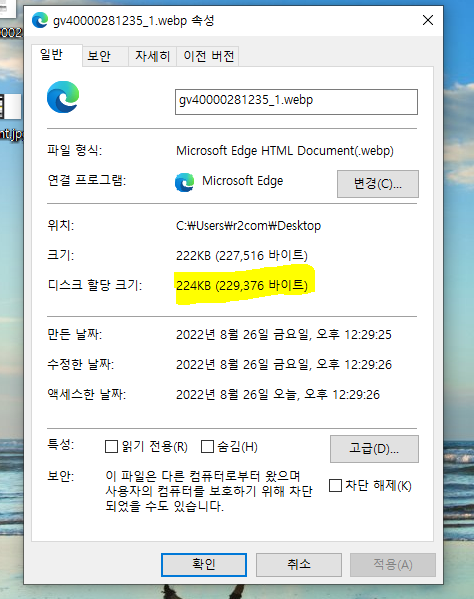
M사의 영양정보 이미지의 크기
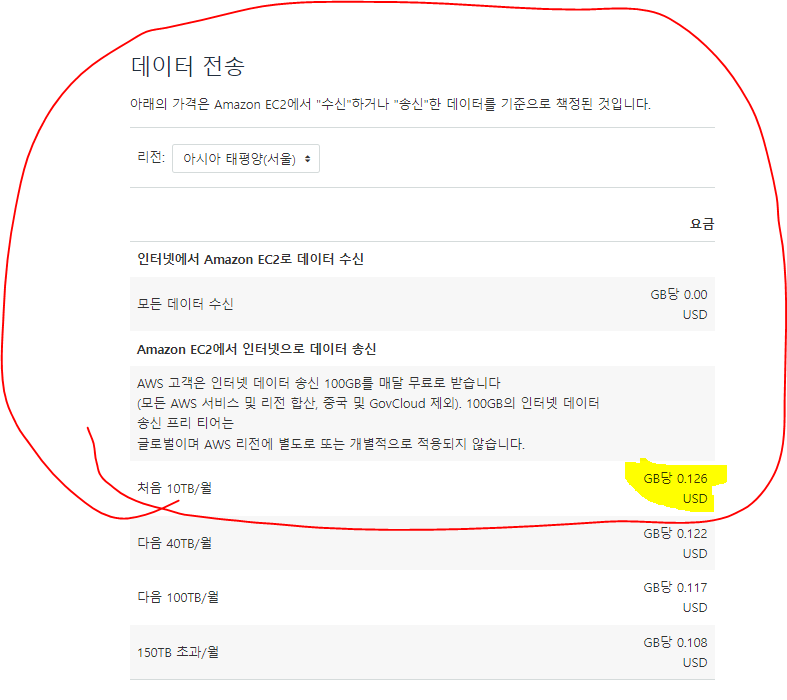
- 224Kb의 크기이며, 최대 1mb로 가정하고, 만약 월 30000건이라 생각하면 30Gb의 크기가 된다.
- 1Gb비용 0.126$ * 30 = 3.78$
방법 2, VPC Nat게이트웨이 이용하기
- https://aws.amazon.com/ko/vpc/pricing/
- 공식으로 안내해주듯이 DataTransfer요금을 절약할 수 있는 VPC엔드포인트를 사용하는 것이 더 좋을 것 같다.
방법 3, VPC 엔드포인트 이용하기
- https://stackoverflow.com/questions/39779962/access-aws-s3-from-lambda-within-vpc
- 위 링크에서 나와 똑같은 문제에 직면한 사람이 있는데 여기서 두가지 방법을 소개하고 있다.
- VPC 엔드포인트를 새로 생성하는 방법, NAT 게이트웨이를 추가하는 방법
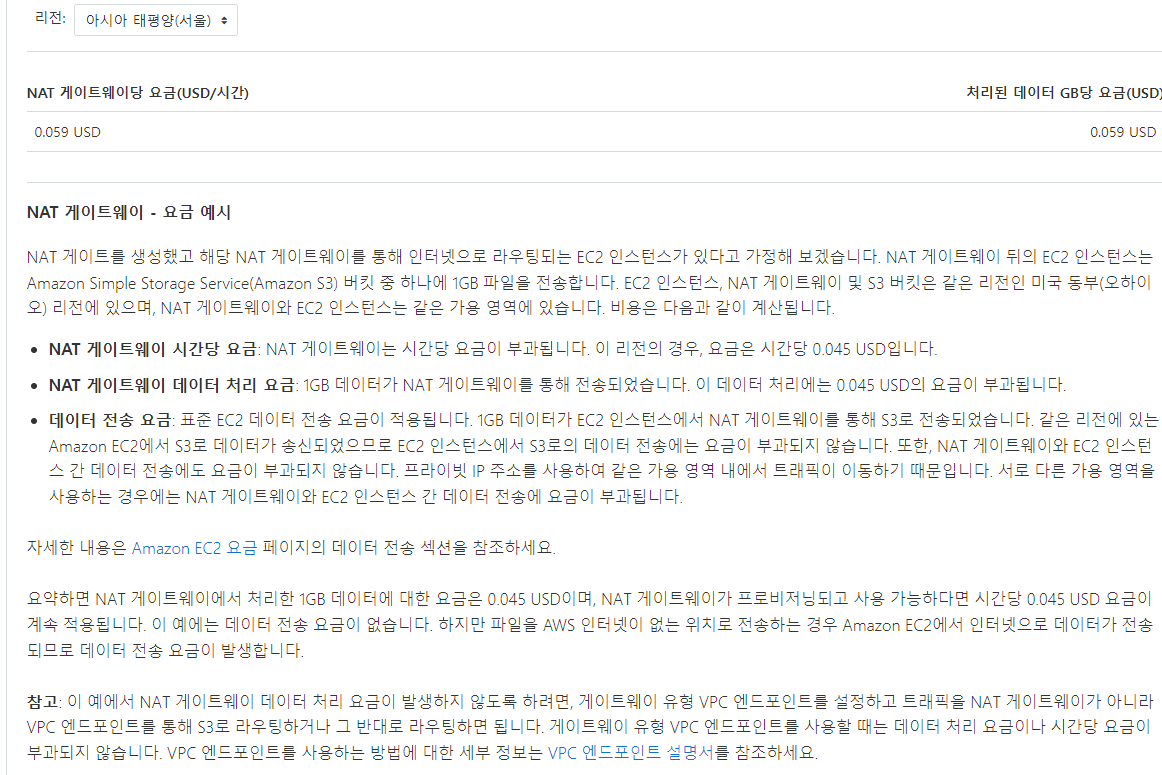
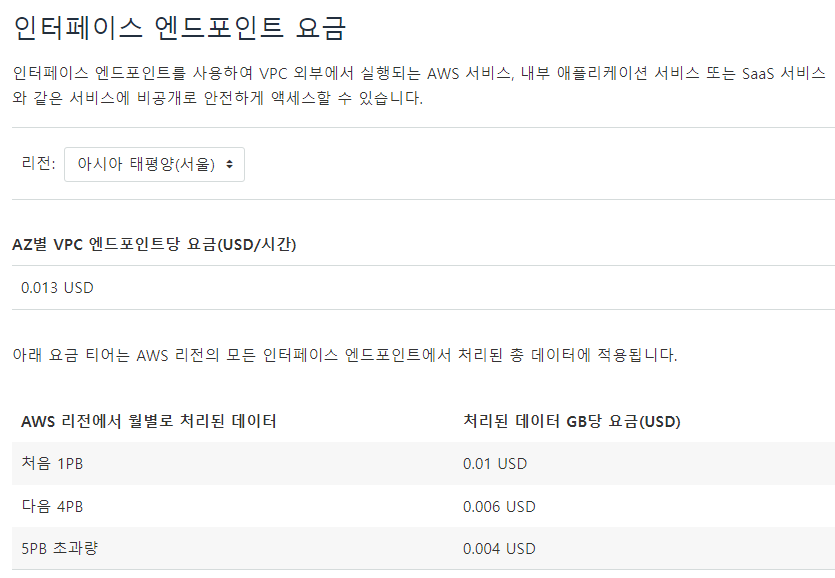
VPC 엔드포인트 요금
- https://repost.aws/questions/QUf38Wtw7qTLOHeU-aiLHbfg/aws-vpc-end-point
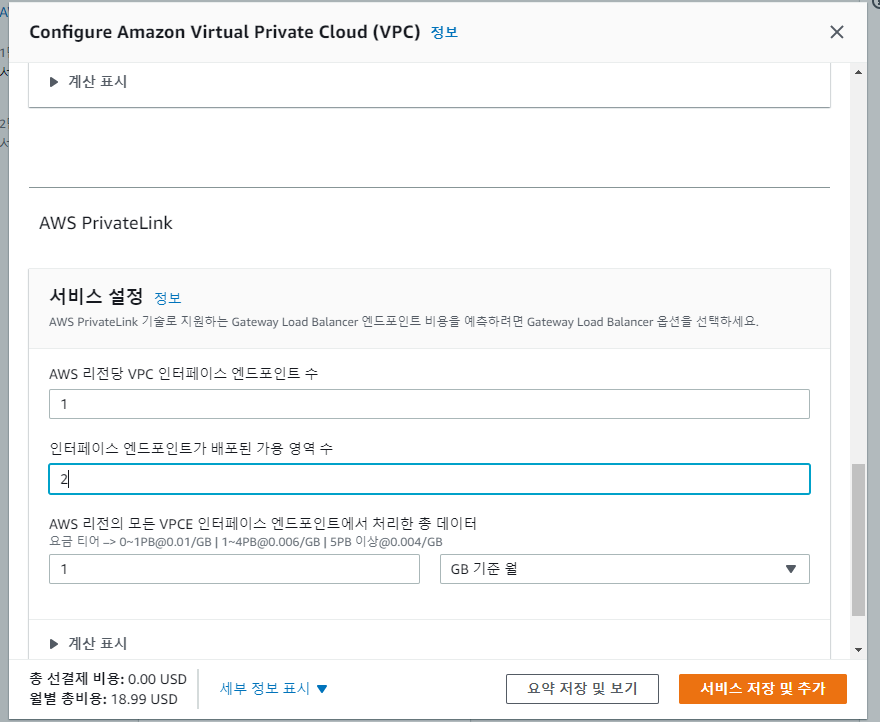
- Lambda의 VPC구성은 가용성을 위해 최소 2개의 영역을 선택해야 한다. 최소 하나의 가용영역에서 엔드포인트를 적용한다면
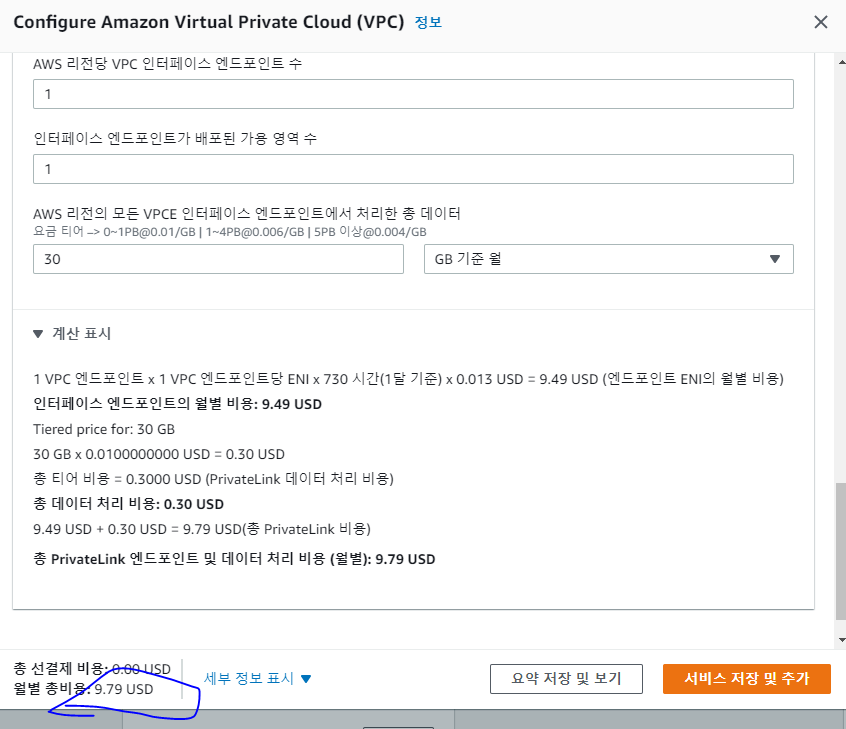
- 9.79$로 사용할 수 있다.
- 여기에 Lambda 연산 비용 30000ms가 추가된다.
- 다만 DataTransfer비용을 절약할 수 있다.
Two Lambdas VS VPC EndPoint
비용
- Lambda Double
- Lambda cost : 3.76$
- Data Transfer : 3.78$
- Total : 7.54$
- VPC EndPoint
- VPC Endpoint: 9.76$(single AZ)
- Data Transfer: Free
- Total: 9.76$
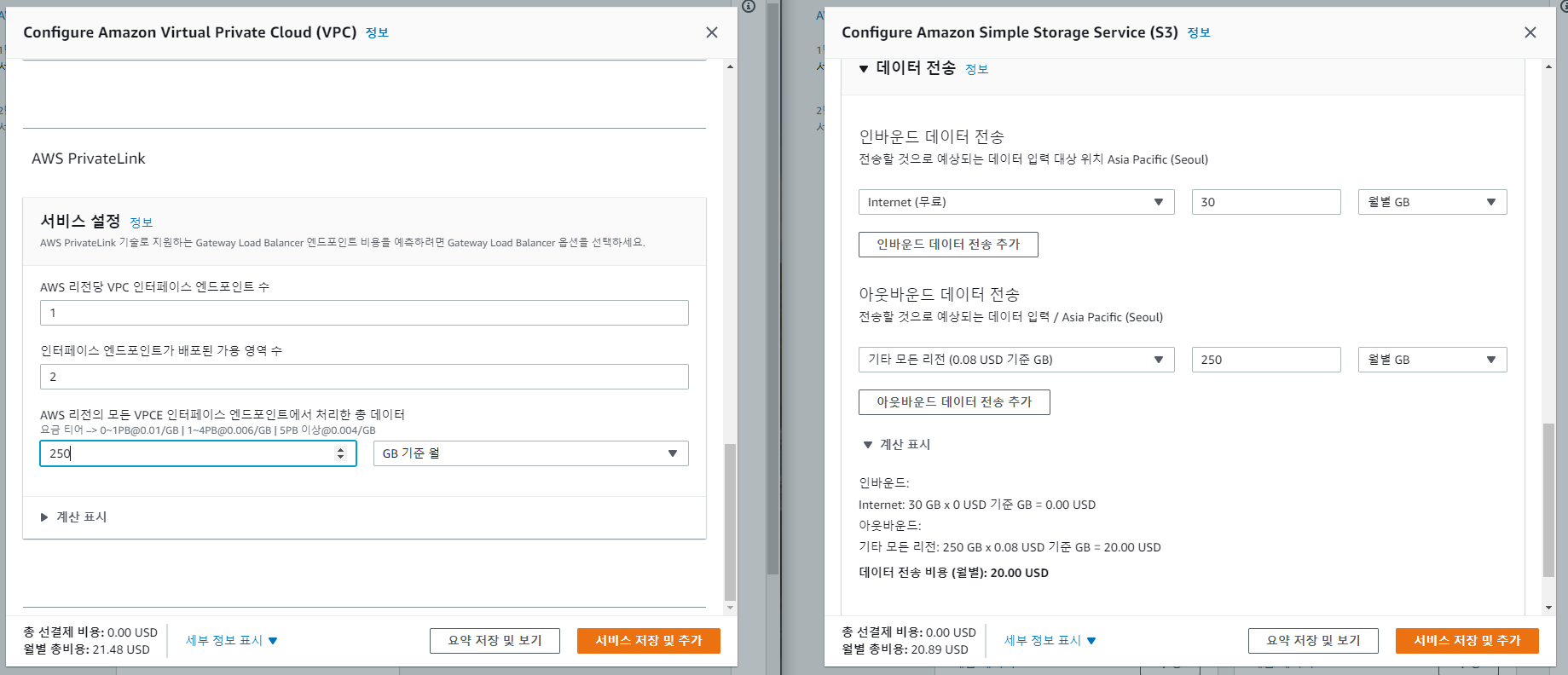
Data Transfer
- VPC 엔드포인트로 DataTransfer비용으로 이득을 보기위해서는 S3에서 데이터를 250Gb이상 가져올 때 부터 이득을 볼 수 있다.
가용성
- Lambda Double
- Auto Multy region
- VPC EndPoint
- Multy region(Extra Cost)
추가
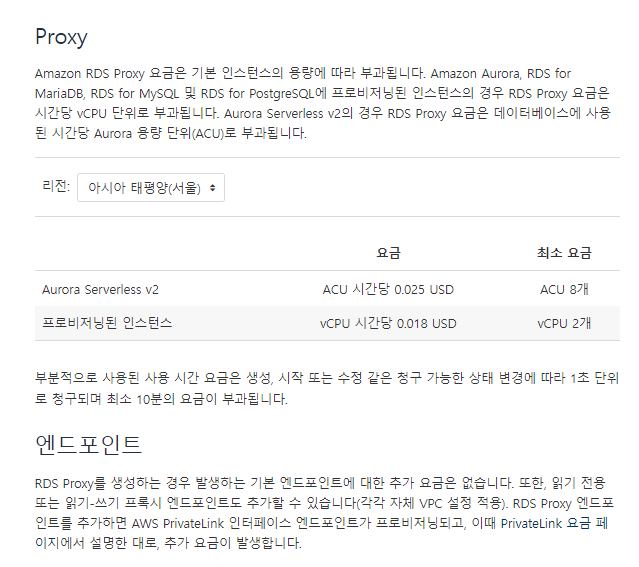
- Lambda에서 Amazon RDS 프록시를 이용하여 RDS와 연결할 수 잇다.
- 당연히 추가요금이 발생한다.
결론
- 비용과 가용성면에서 Lambda를 두번사용하는 것이 더 이득일 것이다.



정리
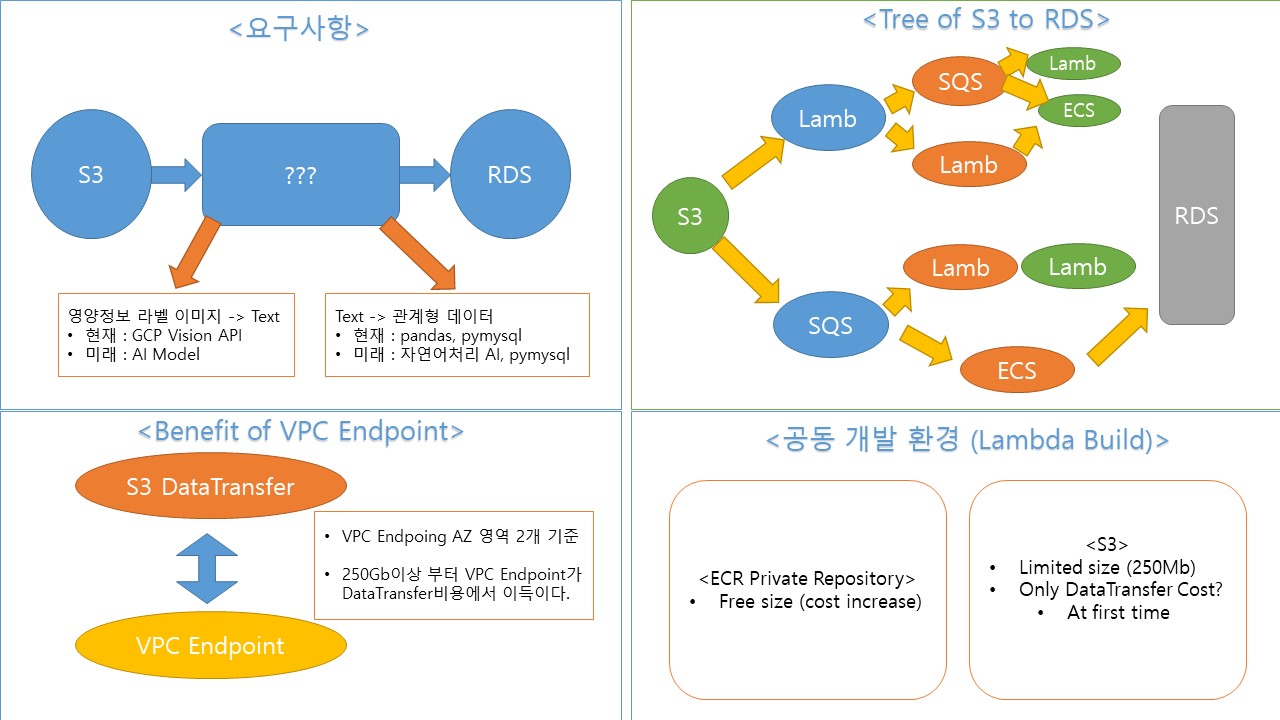
Double Lambda Architecture 구성하기
Lambda 1
ECR 생성
- Private Repository를 생성했다.
이미지 생성
app.py
import sys import os from struct import pack import json import urllib.parse import boto3 #import TextProcessing #import rds_connect print('Loading function') s3 = boto3.client('s3') def detect_document(path): """Detects document features in an image.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() # [START vision_python_migration_document_text_detection] with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.document_text_detection(image=image) if response.error.message: raise Exception( '{}\nFor more info on error messages, check: ' 'https://cloud.google.com/apis/design/errors'.format( response.error.message)) # [END vision_python_migration_document_text_detection] return response.full_text_annotation.pages[0].blocks def detect_document(path): """Detects document features in an image.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() # [START vision_python_migration_document_text_detection] with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.document_text_detection(image=image) if response.error.message: raise Exception( '{}\nFor more info on error messages, check: ' 'https://cloud.google.com/apis/design/errors'.format( response.error.message)) # [END vision_python_migration_document_text_detection] return response.full_text_annotation.pages[0].blocks def handler(event, context): text_data = [] # Get the object from the event and show its content type bucket = event['Records'][0]['s3']['bucket']['name'] key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') image_name = key.split('/')[-1] image_path = '/tmp/'+image_name credential_key = 'fabled-meridian-352009-e226c97ba30a.json' credential_name = credential_key credential_path = '/tmp/'+credential_name os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credential_path try: S3_response = s3.get_object(Bucket=bucket, Key=key) print("CONTENT TYPE: " + S3_response['ContentType']) image_path = '/tmp/'+image_name s3.download_file(bucket, key, image_path) s3.download_file(bucket, credential_key, credential_path) response = detect_document(image_path) print(os.path.isfile(image_path)) print(os.path.isfile(credential_path)) print(response) #text_data = TextProcessing.TextProcessing(response) except Exception as e: print(e) print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket)) raise e ''' if text_data: print(text_data) else: print('Errer: Detected Notting') '''Dockerfile
FROM public.ecr.aws/lambda/python:3.7 # Copy function code COPY app.py ${LAMBDA_TASK_ROOT} #COPY rds_config.py ${LAMBDA_TASK_ROOT} #COPY rds_connect.py ${LAMBDA_TASK_ROOT} #COPY TextProcessing.py ${LAMBDA_TASK_ROOT} # Install the function's dependencies using file requirements.txt # from your project folder. COPY requirements.txt . RUN pip3 install -r requirements.txt --target "${LAMBDA_TASK_ROOT}" # Set the CMD to your handler (could also be done as a parameter override outside of the Dockerfile) CMD [ "app.handler" ]requirements.txt
# 20220825 ver1 requirements #pymysql #pandas google google-cloud google-cloud-vision google-api-python-client wget #pillow

이미지 Push
Lambda1 생성
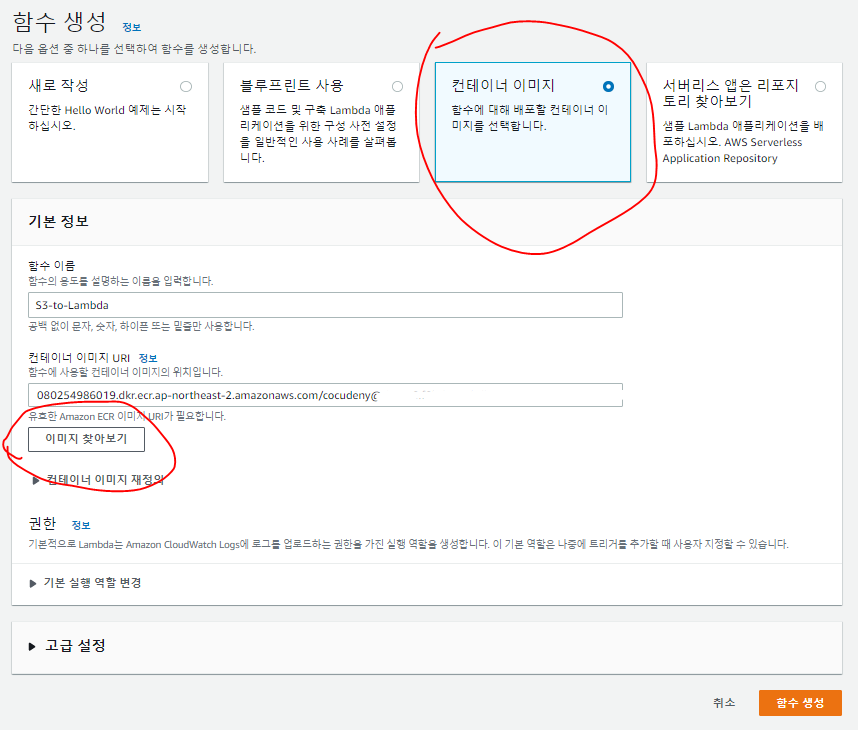
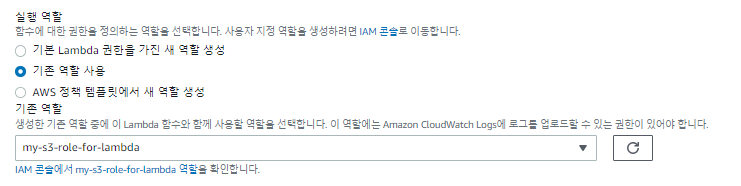
Test
{
"Records": [
{
"eventVersion": "2.1",
"eventSource": "aws:s3",
"awsRegion": "ap-northeast-2",
"eventTime": "2022-08-16T07:20:37.735Z",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": "A1CEH2BS6H1WQW"
},
"requestParameters": {
"sourceIPAddress": "112.221.225.165]"
},
"responseElements": {
"x-amz-request-id": "A7BVGC2SAB10TV70",
"x-amz-id-2": "lux6n/yGmpzZj8Tk3OF758amJ9/HYX/6GqFhJJDTEDOVTSP5d0WozrW37Nh3/HKry5DHf5NT5PByOi15BZwB6EZT0su23WQu7pHN7v3ZQas="
},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "6747ad47-81e3-4da6-b330-176290783e85",
"bucket": {
"name": "s3.cocudeny",
"ownerIdentity": {
"principalId": "A1CEH2BS6H1WQW"
},
"arn": "arn:aws:s3:::s3.cocudeny"
},
"object": {
"key": "Images/capture.JPG",
"size": 263910,
"eTag": "10852e22b2fa01a99695f4924cdbc0c5",
"sequencer": "0062FB4545AC7A94A6"
}
}
}
]
}
Talking Potato