
네트워크 계층(4, 5장) 개요
- 트랜스포트 계층
: 네트워크 계층 호스트들 간의 통신 서비스에 의존함으로써 다양한 형태의 프로세스 간 통신을 제공
네트워크 계층이 실제로 어떻게 구현되었는지 알지 못해도 동작. - 네트워크 계층이 호스트 사이의 통신 서비스를 어떻게 제공하는지 ?
: 다른 계층과 달리, 각 호스트와 네트워크의 라우터마다 네트워크 계층의 일부가 존재 - 네트워크 계층의 서로 상호작용하는 두 부분
1. 데이터 평면(data plane)
2. 제어 평면(control plane) : 라우팅 알고리즘 OSPF, BGP - 네트워크 계층 기능 : 라우터별 제어(per-router)
: 한 라우터의 입력 링크에 도착한 데이터그램이 다른 한 목적 라우터의 출력 링크에 어떻게 도착하는지를 결정
-> 전통적인 IP포워딩, 일반화된 포워딩 - IPv4, IPv6 프로토콜과 주소체계
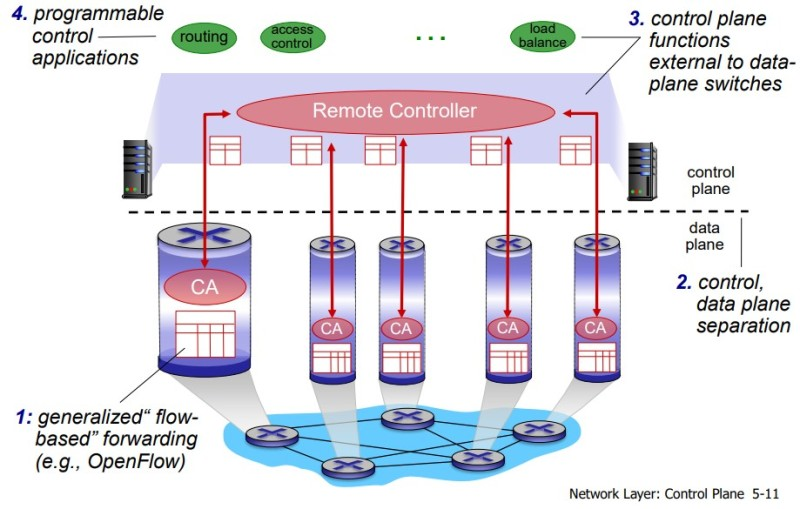
- 소프트웨어 정의 네트워크(software-defined network, SDN)
: 제어 평면의 기능을 분리된 서비스처럼 사용하여 데이터 평면과 제어평면을 뚜렷하게 구분
ex. 원격 '컨트롤러'
4.1 네트워크 계층 개요
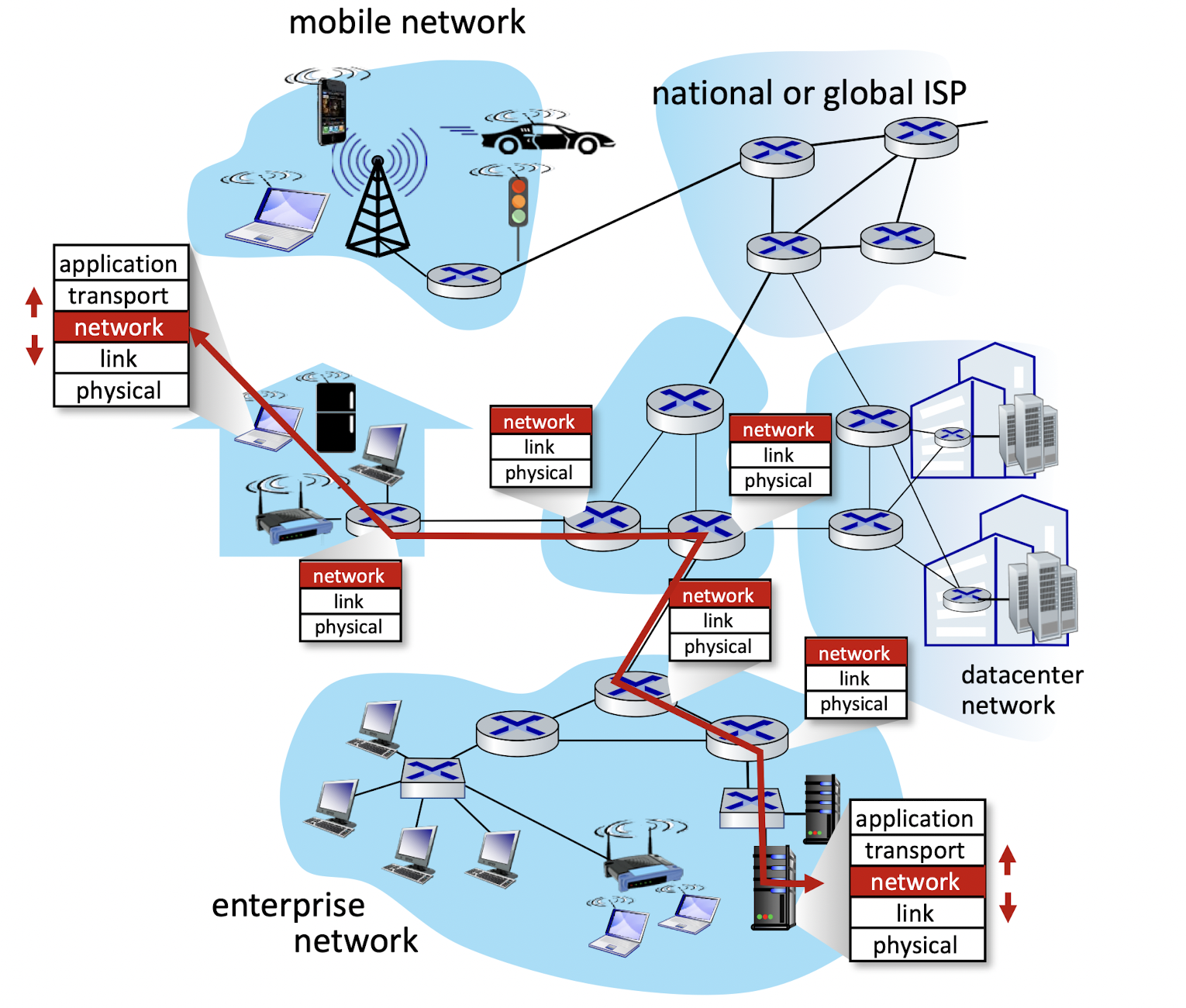
호스트H1 -> 호스트H2 정보를 보낸다고 가정.
라우터는 트랜스포트, 애플리케이션 계층 지원X -> 네트워크 상위 계층 존재X
- H1 네트워크 계층
: H1의 트랜스포트 계층으로부터 세그먼트를 얻어 각 세그먼트를 데이터그램으로 캡슐화
인접한 라우터에게 데이터그램을 전송 - H2 네트워크 계층
: 트랜스포트 계층 세그먼트를 추출하여 H2의 트랜스포트 계층까지 전달 - 각 라우터의 데이터 평면
: 입력 링크에서 출력 링크로 데이터그램 전달 - 각 라우터의 제어 평면
: 데이터그램이 출발지 호스트에서 목적지 호스트까지 잘 전달되게끔 로컬 포워딩, 라우터별 포워딩 대응시킴
4.1.1 포워딩과 라우팅: 데이터 평면과 제어 평면
[네트워크 계층의 근본적인 역할]
: 송신 호스트에서 수신 호스트로 패킷을 전달하는 것
[중요한 기능]
1. 포워딩(전달)
: 패킷이 라우터의 입력 링크에 도달했을 때 라우터는 그 패킷을 적절한 출력 링크로 이동시켜야 함.
포워딩에서 예외적으로 가장 보편적이고 중요한 한 기능이 데이터 평면에서 실행.
매우 짧은 시간(나노초)단위 -> 하드웨어에서 실행
2. 라우팅
: 송신자가 수신자에게 패킷을 전송할 때 네트워크 계층은 패킷 경로를 결정
-> 라우팅 알고리즘 (in 제어평면)
긴 시간(초)단위 -> 네트워크 전반에 걸쳐 출발지에서 목적지까지 데이터그램의 종단 간 경로 결정, 소프트웨어에서 실행
[포워딩 테이블]
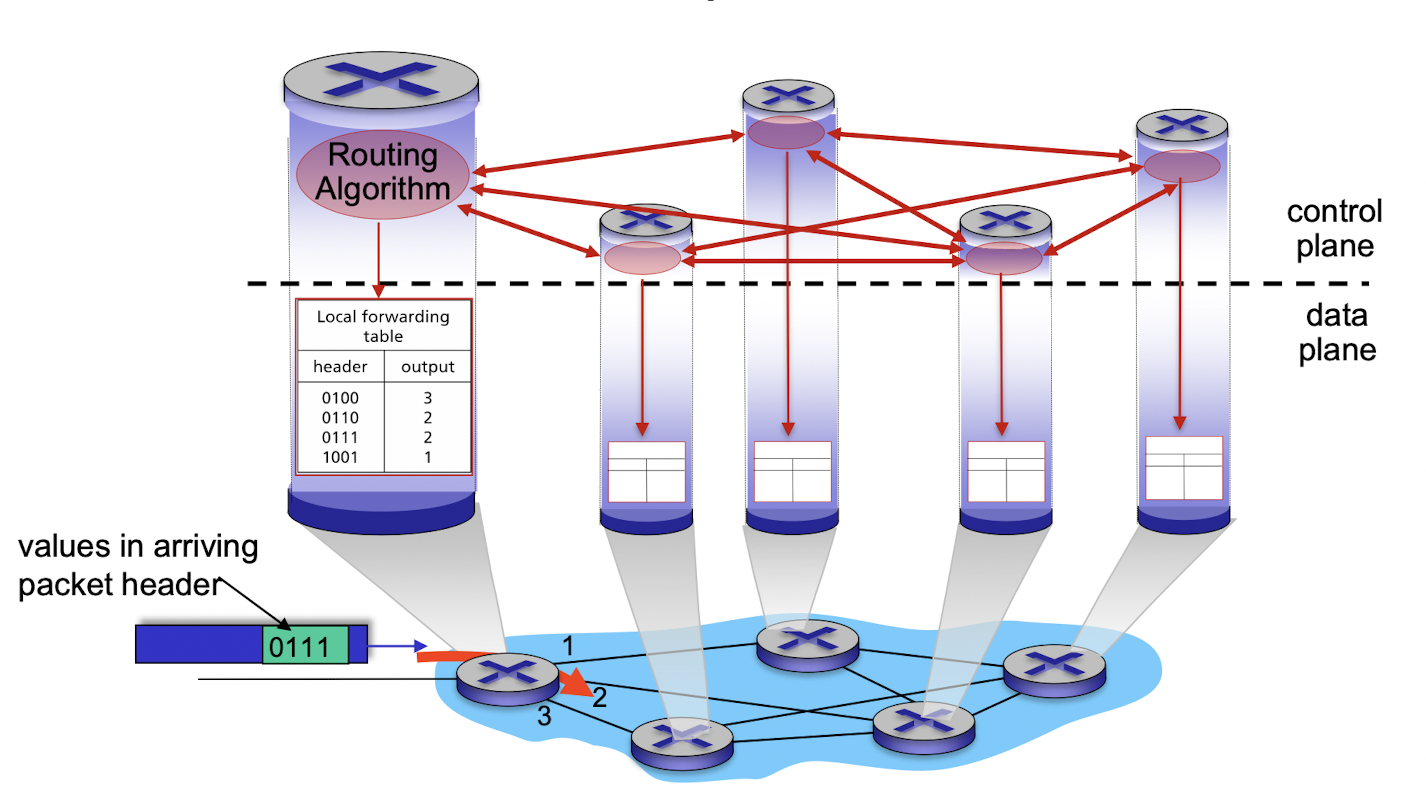
- 라우터는 도착하는 패킷 헤더의 필드값을 조사하여 패킷 전달
- 필드값 -> 포워딩 테이블의 내부 색인으로 사용
- 포워딩 테이블 헤더의 값 = 해당 패킷이 전달되어야 할 라우터의 외부 링크 인터페이스, 패킷의 목적지 주소 or 패킷이 속한 연결의 지시
[제어 평면: 전통적인 접근 방법]
- 라우팅(제어 평면) & 포워딩(데이터 평면) 사이의 상호작용으로 포워딩 테이블 구성
- 라우팅 알고리즘
- 라우터의 포워딩 테이블의 내용 결정
- 각각의 모든 라우터에서 실행
- 라우터가 포워딩 + 라우팅 기능 수행
- 한 라우터의 라우팅 알고리즘 기능은 다른 라우터의 것과 소통 -> 포워딩 테이블의 값 계산
- 소통? 라우팅 프로토콜에 따라 라우팅 정보에 포함된 라우팅 메시지를 교환
- 제어 평면과 상호작용 !!- 각 라우터는 다른 라우팅 구성요소와 소통하기 위한 라우팅 구성요소를 갖고 있다!
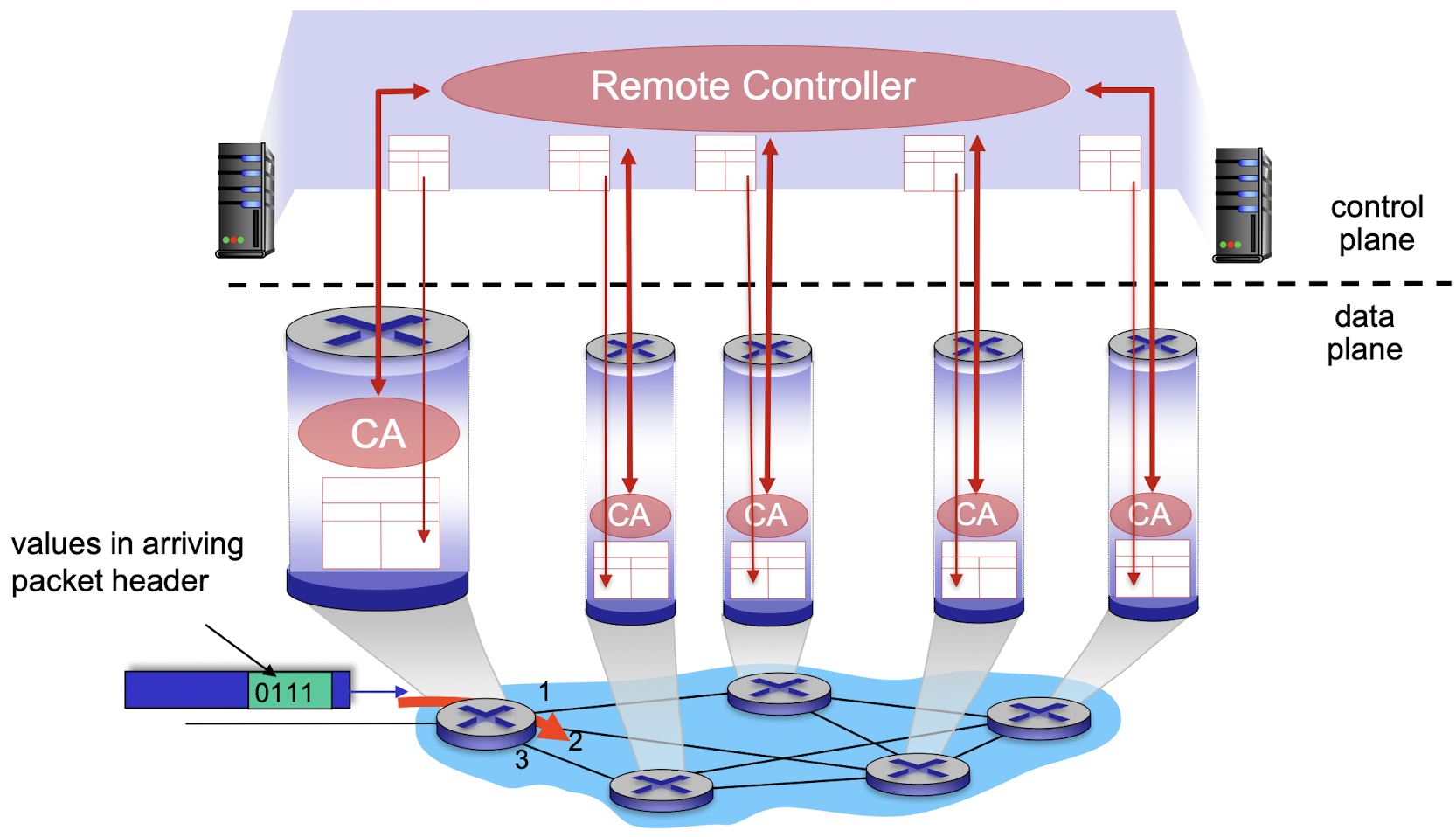
[제어 평면: SDN 접근 방법]
- 인간이 포워딩 테이블을 수동으로 구성할 수 있다?
-> 제어 평면 기능이 데이터 평면에서의 포워딩 테이블의 내용 결정하는 방법?- 물리적으로 분리된 라우터로부터, 원격 컨트롤러 컴퓨터와 각각의 라우터에 의해 사용될 포워딩 테이블을 분배하는 다른 접근법
- 원격 컨트롤러
: 높은 신뢰성과 중복성을 갖춘 원격 데이터 센터에 설치
ISP, 제3자에 의해 관리됨.- How to 라우터, 원격 컨트롤러 소통?
: 포워딩 테이블과 그 밖의 라우팅 정보를 포함한 메시지 교환
네트워크가 '소프트웨어적으로 정의되었을 때', 포워딩 테이블을 계산하는 컨트롤러는 라우터와 상호작용을 하며 소프트웨어에서 실행
4.1.2 네트워크 서비스 모델
네트워크 서비스 모델 : 송수신 호스트 간 패킷 전송 특성 정의
Q.
트랜스포트 계층은 네트워크 계층이 목적지까지 패킷을 전달한다는 것을 믿을 수 있는가?
여러 패킷이 전송될 때, 보낸 순서와 동일하게 수신 호스트의 트랜스포트 계층에 전달될 수 있는가?
연속적인 두 패킷 사이의 송신 시간이 이들 패킷의 수신시 걸리는 시간과 동일한가?
네트워크가 네트워크 혼잡에 대한 피드백을 제공할 수 있는가?
송신 호스트와 수신 호스트에서 트랜스포트 계층을 연결하는 채널의 추상적인 관점은?
A.
네트워크 계층이 제공하는 서비스 모델에 따라 답이 결정된다.
[네트워크 계층에서 제공할 수 있는 서비스]
1. 보장된 전달
2. 지연 제한 이내의 보장된 전달
3. 순서화 패킷 전달 : 순서대로 도착하는 것을 보장
4. 최소 대역폭 보장 : 특정한 비트율의 전송 링크를 에뮬레이트
5. 보안 서비스 : 트랜스포트 계층의 모든 세그먼트에 대한 기밀성 유지
[best-effort service 최선형 서비스]
- 보장된 전달X, 순서화 패킷 전달 보장X, 최소 대역폭 보장X, 종단 시스템 간 지연 보장X
- 여러 네트워크 구조는 최선형 서비스보다 좋은 서비스 모델 정의•구현
1. ATM 네트워크 구조[Black 1995]
: 순서화 패킷 전달O, 지연 제한 이내의 보장된 전달O, 최소 대역폭 보장O
2. Intserv 구조[RFC 1633]
: 인터넷 구조 서비스 모델
종단 간 지연 보장O, 혼잡 방지 통신 목표
- 최선형 서비스 인터넷 모델
1. 매커니즘의 단순성 -> 인터넷 널리 배포될 수 있었음
- 대역폭의 충분한 provisioning
-> Netflix와 같은 스트리밍 비디오 서비스, 실시간 회의 good!- 클라이언트의 네트워크에 가까이 연결된 복제된 애플리케이션 계층 분산 서비스는 여러 위치에서 서비스 제공 가능
- 탄력적인 서비스의 혼잡 제어
- 이 모델의 성공을 논하기 어려움.
4.2 라우터 내부에는 무엇이 있을까?
- 용어 정리
- 포워딩
: 패킷 스위치(라우터)는 네트워크 계층 필드값에 근거하여 포워딩 결정
라우터 = 네트워크 계층(3계층) 장치
- 스위칭
: 링크 계층 프레임의 필드값에 근거하여 포워딩을 결정하는 링크 계층 스위치
스위치 = 링크 계층(2계층) 장치 - Key
- 포워딩과 라우팅의 중요한 차이점
- 네트워크 계층의 서비스와 라우터의 입력 링크에서 적절한 출력 링크로 패킷을 실제로 전달하는 기능
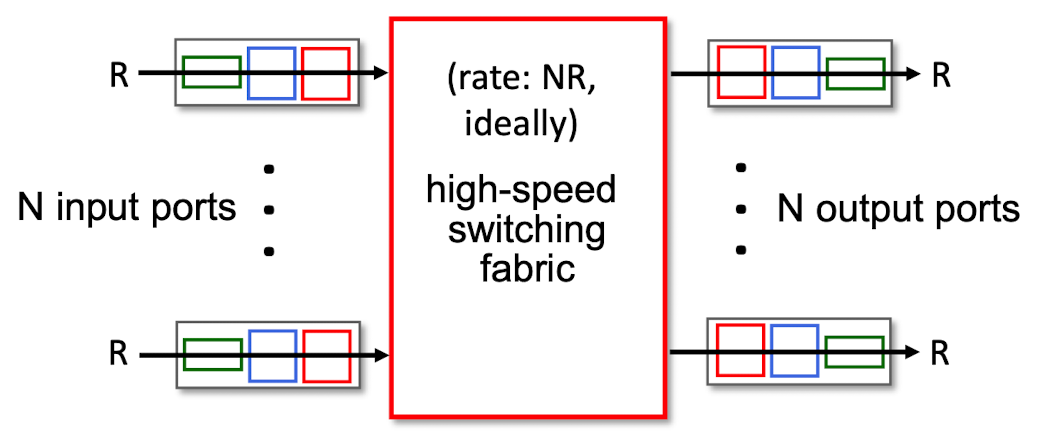
[라우터 architecture 개요]
1. 입력 포트
1) 🟩 초록색 박스
- 라우터로 들어오는 입력 링크 -> 물리 계층 기능
2) 🟦 파란색 박스
- 들어오는 링크의 반대편에 있는 링크 계층과 상호 운용 -> 링크 계층 기능
3) 🟥 빨간색 박스
- 입력 포트에서 검색 기능 수행⭐️
- 포워딩 테이블 참조 -> 도착된 패킷이 스위치 구조를 통해 라우터 출력 포트 결정
- 제어패킷(라우팅 프로토콜 정보 전달)은 입력 포트에서 라우팅 프로세서로 전달
- 데이터그램이 스위치 구조 포워딩 속도보다 더 빨리 도착하면 input port queuing 발생
1-1 포워딩
1) destination-based forwarding 목적지 기반 포워딩
: 오직 최종 목적지 IP 주소만을 기반으로 포워딩
2) generalized forwarding 일반화된 포워딩
: 헤더 필드값의 많은 요소들이 포워딩에 관여
2. 스위치 구조
- 라우터의 입력 포트와 출력 포트 연결
- 라우터 내부에 포함되어 있음.
- 네트워크 라우터의 내부 네트워크
- ex. 원형 교차로
3. 출력 포트
- 스위치 구조에서 수신한 패킷 저장
- 필요한 링크 계층 및 물리 계층 기능 수행 -> 출력 링크로 패킷 전송
- 일반적으로 동일한 링크의 입력 포트와 한 쌍
4. 라우팅 프로세서
1) 제어 평면 기능 수행
- 기존 라우터 : 라우팅 프로토콜 실행, 라우팅 테이블과 연결된 링크 상태 정보 유지 관리, 포워딩 테이블 계산
- SDN 라우터 : 원격 컨트롤러와 통신, 포워딩 테이블 엔트리 수신, 라우터의 입력 포트에 해당 엔트리 설치
2) 네트워크 관리 기능 수행
4.2.1 입력 포트 처리 및 목적지 기반 전송
- 라우터
포워딩 테이블로 도착 패킷이 스위치 구조를 통해 전달되는 출력 포트를 검색- 포워딩 테이블
- 라우팅 프로세서에서 계산, 갱신, 원격 SDN 컨트롤러에서 수신
- 라우팅 프로세서에서 입력 라인 카드로 복사 (섀도 복사본)
-> 패킷 단위로 중앙 집중식 라우팅 프로세서 호출 X, 병목 현상 방지
[32bit IP주소의 경우]
모든 가능한 목적지 주소마다 하나의 엔트리가 필요
40억 개 이상의 가능한 주소 필요 -> 불가능
[4개의 엔트리를 갖는 포워딩 테이블]
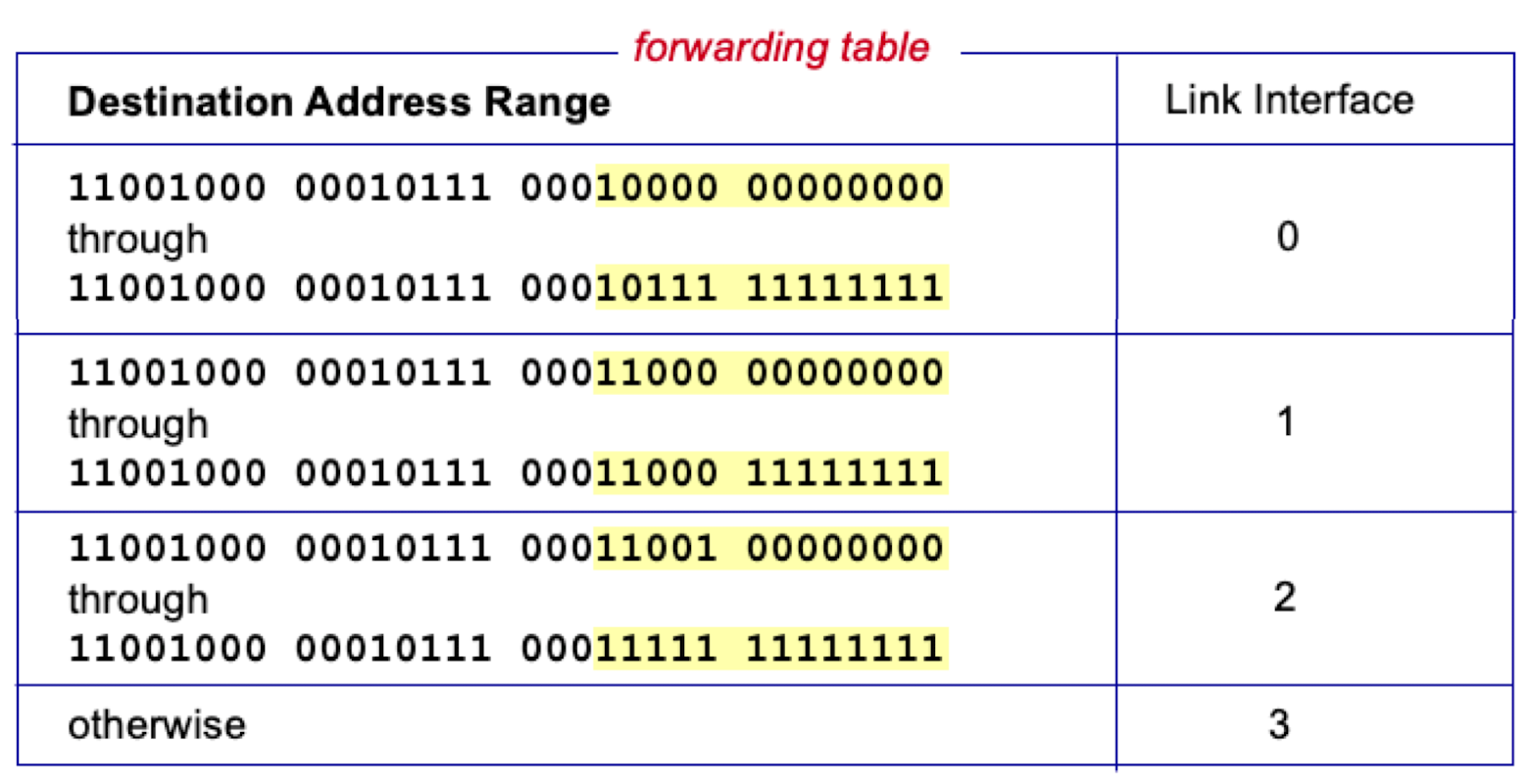
- 라우터
: 목적지 주소의 프리픽스(주소 앞 21자리)를 테이블의 엔트리와 매치
-> 0, 1, 2와 매치되지 않는다면 고정 인터페이스 3으로 전송- 최장 프리픽스 매치 규칙 (Longest Prefix Matching Rule)
- 다수의 매치 -> 가장 긴 매치 엔트리에 매치
- 기가바이트 전송률에서 검색은 나노초 단위로 수행되어야 함.
-> 단순 선형 검색 이의외 기술이 필요- TCAM
- 종종 최장 프리픽스 매치에 사용
- 메모리에 제공된 32bit IP주소 : 일정 시간 동안 해당 주소에 대한 포워딩 테이블 엔트리의 내용을 반환
- 테이블 크기에 관계없이 한 클럭 주기로 주소 검색
- Cisco Catalyst : 최대 1백만 개의 라우팅 테이블 엔트리 수용
[입력 포트 처리]
1) 가장 중요한 '검색' : 출력포트 결정
2) 물리 및 링크 계층 처리
3) 패킷의 버전 번호, 체크섬, TTL필드 확인 후 두 필드 다시 사용
4) 네트워크 관리에서 사용되는 카운터(수신된 IP데이터그램 수) 갱신
4.2.2 스위칭
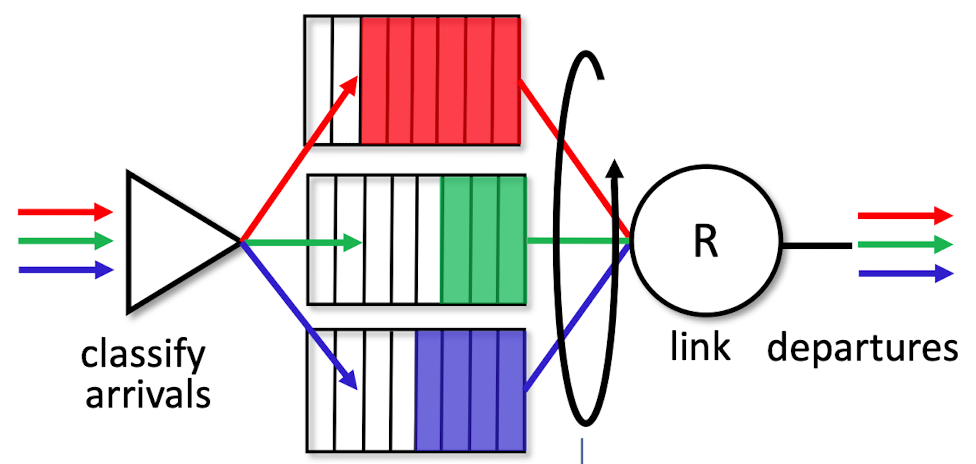
- 패킷의 출력포트가 결정되면 패킷을 스위치 구조로 전송.
- What is " 패킷의 차단, 큐잉, 스케줄링 " ?
[스위치 구조 Switching fabrics]
- 입력 링크에서 적절한 출력 링크로 패킷 전송
- 패킷이 입력포트에서 출력포트로 실제로 스위칭(포워딩)되는 구조를 통과
- 라우터의 핵심
- 스위칭 속도 : 패킷을 입력에서 출력으로 전송할 수 있는 속도
종종 입력/출력 라인 속도의 배수로 측정됨.
[스위칭의 세 가지 타입]
1) 메모리를 통한 교환
- CPU(라우팅 프로세서)를 직접 제어하던 가장 단순한 초기의 라우터
- 시스템 메모리에 복사된 패킷
- 메모리 대역폭에 의해 제한된 속도
- 공유 시스템 버스 -> 두 패킷 동시 전달 불가
ㅤ
2) 버스를 통한 교환
- 입력 포트는 라우팅 프로세서의 개입없이 공유 버스를 통해 직접 출력 포트로 패킷 전송
- 모든 출력 포트에 패킷 수신 -> 레이블과 매치되는 포트만 패킷 유지
- 버스 대역폭에 의해 제한된 전환 속도
-> 모든 패킷이 하나의 버스를 건너가야 함. 한 번의 하나의 패킷만 통과 가능.
- 종종 작은 지역 및 기업 네트워크에서 작동하는 라우터에서 사용하기에 충분
-> 32Gbps 버스, Cisco 5600 : 액세스 라우터에 충분한 속도
ㅤ
3) 상호연결 네트워크를 통한 교환
- 공유 버스의 대역폭 제한 극복
🔹 크로스바 스위치
- N개의 입력포트를 N개의 출력 포트에 연결하는 2N버스로 구성된 상호 연결 네트워크
- 수직 버스는 수평 버스와 교차점에서 교차, 스위치 구조 컨트롤러에 의해 언제든지 열거나 닫을 수 있음.
-> 여러 패킷 병렬 전달 가능
- 서로 다른 입력 포트에서 나오는 패킷이 동일한 출력 포트로 보내지는 경우 차단.
🔹다단게(multistage) 스위치
- 좀 더 정교한 상호연결 네트워크
- 각기 다른 입력 포트의 패킷이 동일한 출력 포트를 향해 동시 전달 가능
- 데이터그램을 고정된 길이의 셀로 분할
- K개의 작은 청크로 분해 -> 출력 포트에서 원래의 패킷으로 재조합
4.2.3 출력 포트 처리
출력 포트의 메모리에 저장된 패킷을 가져와서 출력 링크를 통해 전송
전송을 위한 패킷 선택(스케줄링), 큐 제거, 필요한 링크 계층 및 물리 계층 전송 기능 수행
4.2.4 어디에서 큐잉이 일어날까?
- 큐의 위치와 범위 : 트래픽 로드, 스위치 구조의 상대 속도 및 라인 속도에 따라서 달라진다.
- 큐가 커지면
- 라우터의 메모리가 소모
- 도착하는 패킷을 저장할 수 있는 메모리가 없을 경우 패킷 손실 발생 - 입력 및 출력 라인의 속도(전송률) : 초당 R(line) 패킷
- 스위치 구조 전송률 R(switch) : 패킷이 입력포트에서 출력포트로 이동할 수 있는 속도
- R(switch) > R(line)*N
- 입력 포트에서 발생하는 큐잉 무시
- 다음 배치 작업이 도착하기 전에 스위치 구조를 통해 삭제 가능
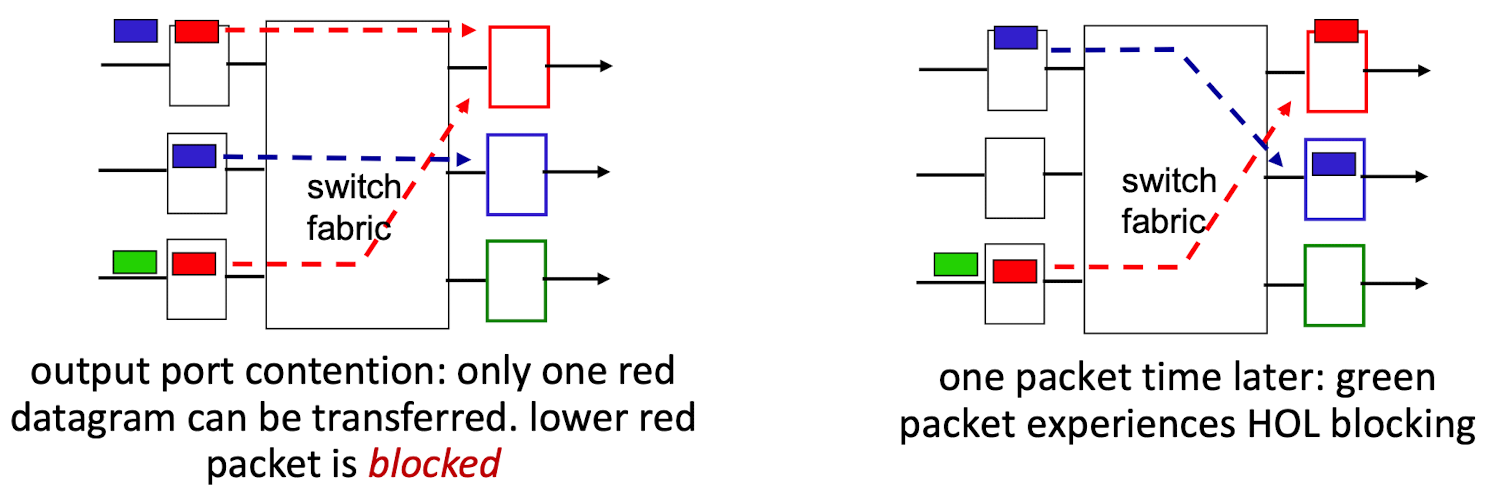
[입력 큐잉]
- HOL(head-of-the-line) 차단(블로킹)
- 빨간박스 둘이 충돌 -> 하단 빨간 박스 대기
- 초록박스가 사용할 출력 포트가 사용 중이지 않아도 앞에 빨간박스의 대기 때문에 초록박스가 기다려야하는 현상
- 패킷 손실이 증가
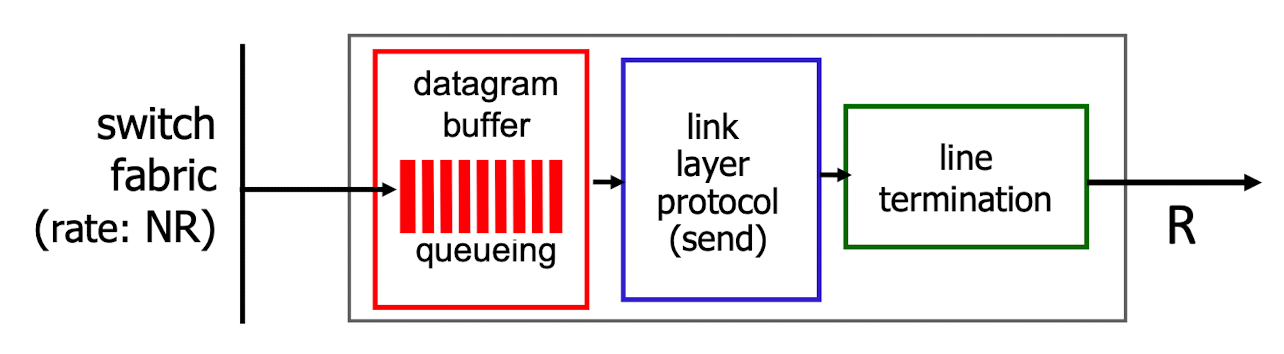
[출력 큐잉]
- Buffering
- 스위치를 통한 도착 속도가 출력 라인 속도를 초과할 경우 발생
- 출력 포트 버퍼 오버플로로 인한 대기열(지연) 및 손실
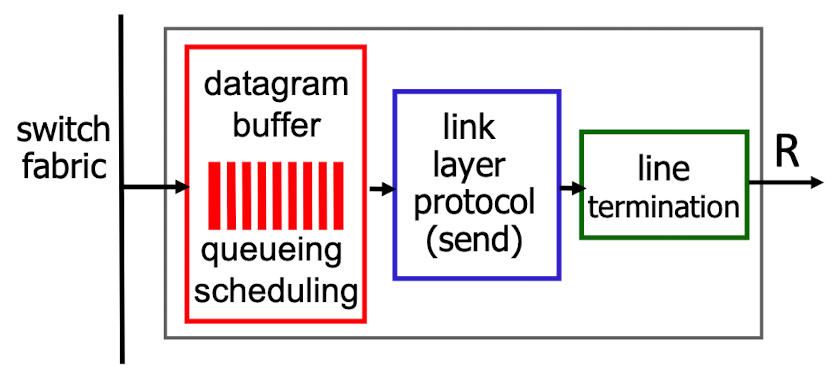
[Buffer 관리]
- Drop-tail 정책
- 들어오는 패킷을 저장할 메모리가 충분하지 않을 때 도착한 패킷을 삭제
- 이미 대기 중인 하나 이상의 패킷을 제거하여 새로 도착한 패킷을 저장하기 위한 공간 확보 필요
- 정체, 버퍼 부족으로 인해 데이터그램 손실 가능- Sheduling discipline
- 전송을 위해 대기중인 데이터그램 중에서 선택
- 우선순위 스케줄링 : 최고의 성능, 네트워크의 중립성- 신호 정체로 표시할 패킷 : ECN, RED
[How much buffering?]
- 링크 용량 C
- 버퍼링의 양 B = RTT(250msec)
- 필요한 버퍼의 양 = RTT * C
- 많은 수의 독립적인 TCP 흐름 N
- 많은 수의 독립적인 TCP 흐름이 링크를 통과할 때 필요한 버퍼링 =
- 과도한 버퍼링 : 큐잉 지연 증가
-> 링크는 충분히 꽉 차게 유지하되, 더 꽉 차게 유지하지 않는다. (양날의 검)
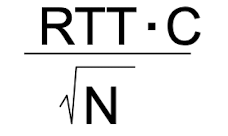
4.2.5 패킷 스케줄링
- 링크에서 다음으로 보낼 패킷 결정
- Fist Come, First Served
- Priority
- Round robin
- Weighted fair queueing
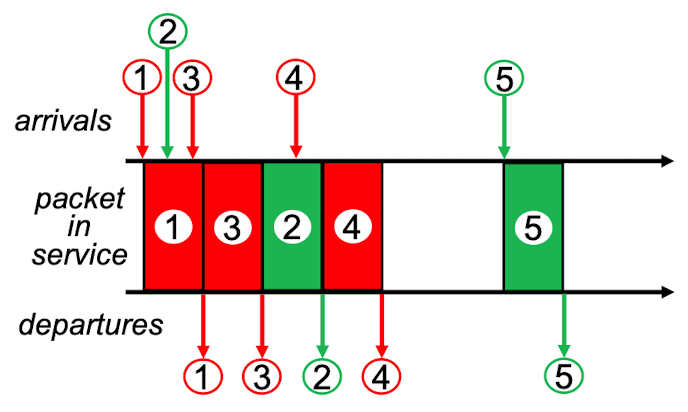
[FCFS]
- FIFO (First In, First Out) 방식
- 출력 링크 큐에 도착한 순서와 동일한 순서로 출력 링크에서 전송할 패킷 선택
[Priority]
- 출력 링크에 도착한 패킷은 큐에 도착하면 우선순위 클래스로 분류
- 가장 높은 우선순위 클래스에서 패킷을 전송
- 우선순위 동일 -> FCFS 방식으로 수행
- 비선점 우선순위 큐잉 : 패킷 2의 전송 중에 우선 순위가 더 높은 패킷 4가 도착하더라도, 패킷의 전송이 시작되면 중단하지 않으므로 패킷 4는 전송을 위해 대기.
[Round Robin]
- 우선순위 큐잉과 같이 클래스로 분류
- 클래스 간 엄격한 서비스 우선순위가 존재 X
- 클래스 간에 서비스를 번갈아서 제공
: 클래스1 -> 클래스2 -> 클래스3 -> 클래스1 -> ...- 작업 보존 큐잉 : 유휴 상태 허용 X, 다음 클래스 즉시 검사
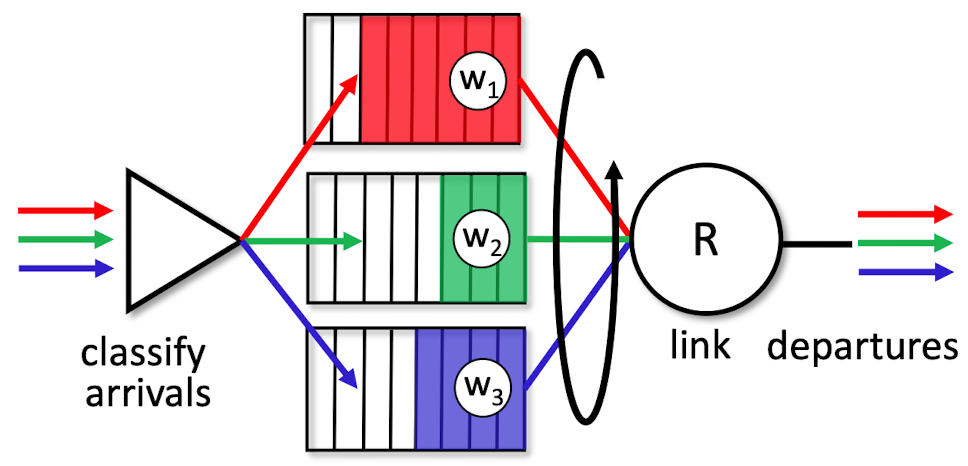
[WFQ(Weighted Fair Queuing) 규칙]
- Round Robin의 일반화된 형태
- RR과의 차이점 : 각 클래스마다 다른 양의 서비스 시간을 부여
- 각 클래스 i 는 가중치(W(i)) 할당 받음
- 전송할 클래스 i패킷이 있는 동안에 클래스 i가 보장받는 서비스 시간 =
- 최소 대역폭 보장
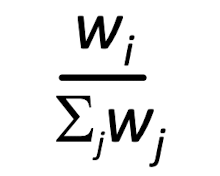
[네트워크 중립성 Network Neutrality]🔺
- ISP
-트래픽의 '클래스'를 정확히 구성하는 것의 정의
- 리소르를 공유/할당하는 방법
- 패킷 스케줄링, 버퍼 관리가 매커니즘
- 잠재적으로 데이터그램의 출발지 IP 주소를 사용하여 다른 회사로부터 전송되는 데이터그램보다 데이터그램에 우선순위를 제공
- 특정 회사 또는 국가에서 출발지 IP주소를 가진 트래픽 차단
- 국가마다 네트워크 중립성에 대한 취급이 다름.- 세 가지 명료하고 밝은 기준 규칙
1) No Blocking
: 서비스는 합당한 네트워크 관리에 따라 합법적인 콘텐츠, 애플리케이션, 서비스, 비서비스 장치 차단X
2) No Throttling
: 합당한 네트워크 관리에 따라 해를 끼치지 않는 장치의 사용으로 합법적인 인터넷 트래픽을 손상, 저하X
3) No Paid Prioritization
: 유료 우선순위에 관여X
유료 우선순위 지정은 트래픽 형성, 우선 트래픽 관리와 같은 기술 사용
4.3 인터넷 프로토콜(IP):IPv4, 주소체계, IPv6등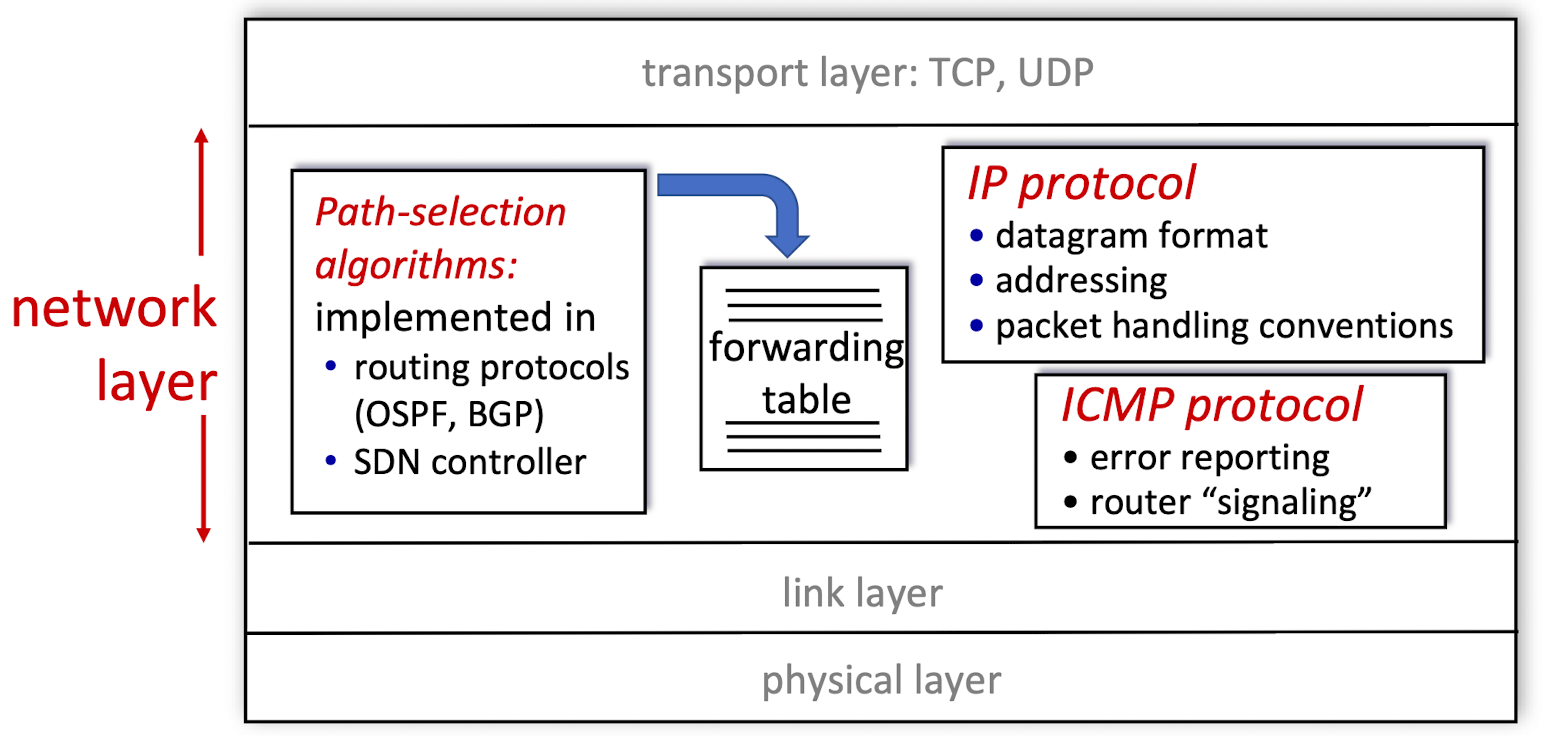
- IP
- IPv4 [RFC 791]
- IPv6 [RFC 2460, RFC 4291]
4.3.1 IPv4 데이터그램 포맷
- 데이터그램 : 네트워크 계층 패킷
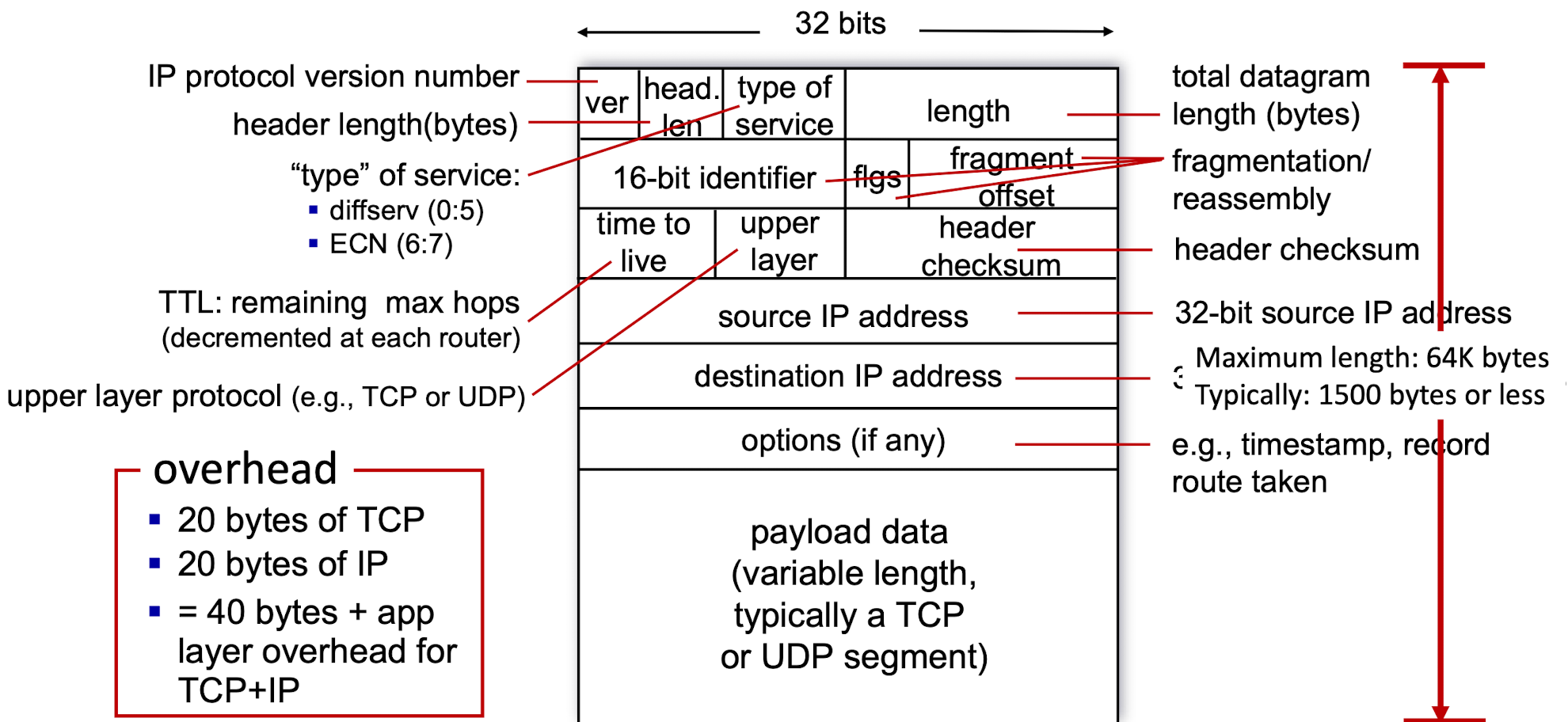
- 버전 번호
- 4bit
- IP 프로토콜 버전 명시
- 라우터 : 버전 번호 확인하여 데이터그램의 나머지 부분 어떻게 해석할 지 결정 - 헤더 길이
- 헤더에 가변 길이의 옵션 포함
- 4bit
- IP 데이터그램에서 실제 페이로드가 시작하는 곳을 결정
- 대부분의 IPv4 데이터그램 헤더는 20바이트 - 서비스 타입(TOS)
- 각기 다른 유형의 IP 데이터그램을 구별
- TOS 비트 중 2개는 명시적 혼잡 알림에 사용
- ex. 실시간 데이터그램(전화통신 앱)과 비실시간 트래픽(FTP) 구분에 유용 - 데이터그램 길이
- 바이트로 계산한 IP 데이터그램의 전체 길이 (헤더 + 데이터)
- 16bit - 식별자, 플래스, 단편화 오프셋
- IP 단편화 관련
- 큰 IP 데이터그램 -> 여러 개의 작은 IP 데이터그램으로 분할 - TTL(time-to-live)
- 데이터그램의 무한 순환(라우팅 루프) 방지
- 라우터가 데이터그램을 처리할 때마다 감소
- TTL = 0 : 라우터가 데이터그램 폐기 - 프로토콜
- IP 데이터그램이 최종 목적지에 도착했을 때만 사용
- 데이터 부분이 전달될 목적지의 트랜스포트 계층의 특정 프로토콜을 명시
- ex. TCP, UDP 사용할 것을 명시
- 프로토콜 번호의 역할 = 트랜스포트 계층 세그먼트에서 포트 번호 필드의 역할 - 헤더 체크섬
- 라우터가 수신한 IP 데이터그램의 비트 오류 탐지에 도움
- 헤더에서 각 2바이트를 수로 처리 후 1의 보수를 합산
- 수신한 헤더 체크섬 == 데이터그램 헤더의 체크섬 : 오류X - 출발지와 목적지 IP 주소
- 출발지가 데이터그램 생성 시, 각 필드에 출발지, 목적지 주소 삽입
- DNS 검색을 통해 목적지 주소 결정 - 옵션
- IP헤더 확장
- 헤더 옵션 필드에 정보 포함X -> 오버헤드 해결
- 데이터그램 헤더가 가변길이로 데이터 필드 시작점을 초기에 결정 불가능
- 옵션 : 문제 복잡하게 만듬.
- 옵션 처리 유무 -> 라우터에서 IP데이터그램 처리하는 데 필요한 시간 좌우 - 데이터 페이로드
- 데이터그램이 존재하는 이유이자 가장 중요한 마지막 필드
- 목적지에 전달하기 위해 트랜스포트 계층 세그먼트를 포함
[IP 데이터그램 길이]
IP 데이터그램 : 20바이트의 헤더 (옵션 없다고 가정)
TCP : 20바이트의 헤더
-> 데이터그램은 총 40바이트의 헤더를 전송
4.3.2 IPv4 주소체계
[인터페이스]
- 호스트 IP가 데이터그램을 보낼 때, 네트워크와 연결되는 하나의 링크를 통해 데이터링크를 보낸다.
- 인터페이스 = 호스트/라우터와 링크 사이의 경계
- 호스트는 하나 또는 두개의 인터페이스 (ex. 유선 이더넷, 무선)
- 라우터는 여러 개의 인터페이스
- IP주소는 인터페이스와 관련
[IP주소]
- 32bit (4byte)
- 2^32개 (약 40억 개)의 주소 사용 가능- 십진 표기법
- 모든 호스트와 라우터의 각 인터페이스는 고유한 IP주소를 가짐.
- 인터페이스의 연결
- 3개의 인터페이스를 갖는 하나의 라우터, 라우터에 의해 연결된 7개의 호스트
- 라우터와 호스트는 IP 주소의 왼쪽 24bit가 동일
- 왼쪽 3개의 호스트 : 이더넷 스위치에 의해 연결된 이더넷 인터페이스
- 아래 2개의 호스트 : 무선 와이파이 인터페이스

[서브넷]
- 3개의 서브넷으로 구성된 네트워크
- 서브넷 : 간섭 라우터를 통과하지 않고 물리적으로 서로 연결할 수 있는 장치 인터페이스
- IP주소 구조
- 서브넷 part : 동일한 서브넷의 장치에 공통 상위 비트 존재
- 호스트 part : 나머지 하위 비트- 서브넷 마스크
- 223.1.1.0/24 에서 '/24' 부분
- 왼쪽 24bit가 서브넷 주소임을 의미- 서브넷을 정의하려면?
1) 호스트나 라우터에서 각 인터페이스를 분리하고 고립된 네트워크 만든다.
2) 이 고립된 네트워크의 종단점 = 인터페이스의 끝
-> 고립된 네트워크 각각이 서브넷이 됨.
-> 라우터끼리 연결하는 것도 하나의 서브넷이다.

[CIDR (Classless InterDomain Routing, 사이다)]
- 인터넷 주소 할당 방식
- 서브넷 주소체계 표기를 일반화
- a.b.c.d/x
- 위 형태의 한 엔트리만으로 기관 목적이로 패킷을 전달하는 데에 충분
- 포워딩 테이블의 크기 감소
- 최상위 x개의 bits = prefix, 네트워크 프리픽스
- 나머지 (32-x)개의 bits : 기관 내부의 같은 프리픽스를 갖는 모든 장비 구별
[DHCP : 주소의 호스트 부분을 얻는 방법]
- IP주소를 얻는 방법
- 주소의 호스트 부분을 얻는 방법
- 주소의 네트워크(서브넷) 부분을 얻는 방법- 호스트 IP 주소 얻는 방법
1) 구성 파일의 sysadmin -> 하드 코딩
2) DHCP : Dynamic Host Configuration Protocol -> 동적으로 가져옴.- DHCP 목적
- 호스트가 네트워크에 '가입'할 때 네트워크 서버에서 IP주소를 동적으로 가져옴. "plug and play"
- 사용 중인 주소 임의로 갱신 가능
- 주소 재사용 가능 (연결/켜짐 상태에서만 주소 유지)
- DHCP서버가 DHCP 제공
- 네트워크에 들어오는 모바일 사용자 지원- DHCP는 클라이언트-서버 프로토콜
- 클라이언트 : 일반적으로 IP 주소를 포함하며 네트워크 설정을 위한 정보를 얻고자 새롭게 도착한 호스트
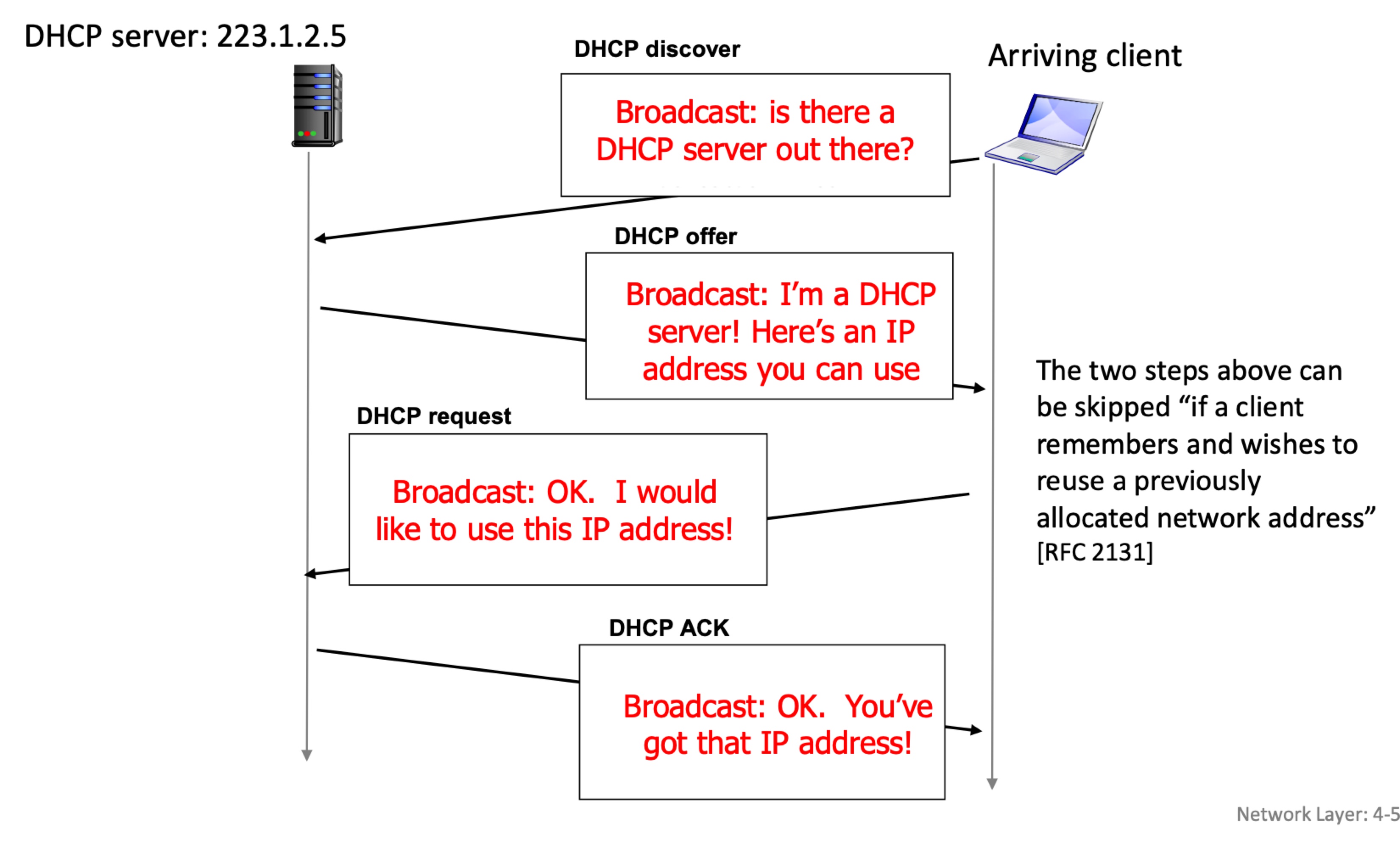
- DHCP 서버 : 라우터와 함께 위치함. 라우터가 릴레이 역할을 하기 때문에 해당 라우터에 연결된 모든 서브넷에 제공할 수 있음.- DHCP 프로토콜 4단계
1) DHCP 서버 발견 [옵션]
- 255.255.255.255 : 브로드캐스트 주소
- transaction ID : 서버의 응답이 나의 것인지 확인하는 용도.
2) DHCP 서버 제공 [옵션]
- lifetime : IP주소 사용할 수 있는 기간
3) DHCP 요청 : 호스트 요청 IP 주소 [필수]
- 네트워크 주소를 이전에 할당받아 재사용할 때 앞에 두 과정 생략 가능
- 해당 주소 사용한다는 요청
4) DHCP ACK : DHCP 서버가 주소를 전송 [필수]
- 그러라는 대답- IP주소 외의 다른 설정 정보 3가지
1) 클라이언트의 first-hop 라우터의 주소
: first-hop 라우터 = 가장 처음 만나는 라우터
먼 거리의 통신을 할 때 필요
2) DNS 서버의 이름과 IP주소
3) 네트워크 마스크 (네트워크, 호스트 부분 표시)- cmd 예제
- 서브넷 마스크 : DHCP 서버가 나한테 준 것이라는 의미
- 기본 게이트웨이 : first-hop 라우터를 의미
- DNS : DHCP 서버거 나한테 준 정보
-> IP주소 + 위 3가지 정보가 있어야 통신 가능- DHCP 예제(request, ack 부분)
- 노트북 연결하면 DHCP를 사용하여 IP주소, first-hop 라우터의 주소, DNS 서버의 주소를 얻는다.
- UDP에 캡슐화된 DHCP 요청 메시지, IP에 캡슐화된 메시지, 이더넷에 캡슐화된 메시지
- DHCP 서버를 실행하는 라우터에서 수신된 LAN의 이더넷 프레임 브로드캐스트 (dest:FFFFFFFFFFFF 모두 1로 채워보내기)
- demux된 이더넷이 demux된 IP로, demux된 UPD가 demux된 DHCP로 설정
- DCP 서버 : 클라이언트의 주소, 클라이언트를 위한 first-hop 라우터의 IP주소, DNS 서버의 이름 및 IP주소를 포함하는 DHCP ACK 공식화
- 캡슐화된 DHCP 서버 응답이 클라이언트로 전달, 클라이언트에서 DHCP까지 demux됨
- 클라이언트는 IP주소, DNS 서버의 이름 및 IP주소, first-hop 라우터의 IP주소를 알게 됨.
[ISP: 주소의 서브넷 부분을 얻는 방법]
- 공급자 ISP의 주소 공간 중 할당된 부분을 가져온다.
-> 그러면 ISP가 주소공간을 8개의 block으로 할당할 수 있다- 2^(32-서브넷부분)개의 호스트 관리 가능
- 이 많은 호스트들 다 사용 불가 -> 8개 회사에 쪼개서 각각 하나씩 나눠줌.
- 네트워크 주소(20bit) 뒤에 추가로 3bit 더해서 내부적으로 쪼개줌.- Hierarchical addressing
- 경로 집약 : 여러 네트워크를 알리기 위해 하나의 네트워크 프리픽스를 사용
- 최장 프리픽스 매치 -> 더 길고 상세한 주소 점유자를 알리는 곳에 라우팅- ISP가 주소 블록을 얻는 방법
- ICANN : IP주소 공간을 관리하고 ISP와 다른 조직에 주소 블록을 할당하는 최상위 국제기관, 비영리 단체
- IP주소 할당과 DNS 루트 서버 관리
- 5개의 RRs(Regional Registries)를 관리- 32bit IP주소의 부족
- 임시 방편으로 NAT라는 기술 사용 중 (근본적인 해결책X)
- IPv6 : 128bit

4.3.3 네트워크 주소 변환(NAT)

[NAT (Network Address Translation)]
- SOHO (Small Office, Home Office)의 확산
- 모든 IP 장치를 수용할 수 있는 주소 범위 할당
- 네트워크 주소 변환으로 해결
- 외부에 관한 한 로컬 네트워크의 모든 장치는 하나의 IPv4 주소만 공유
- 로컬 네트워크로 나가는 모든 데이터그램은 동일한 소스 NAT IP 주소 138.76.29.7를 가짐. -> 소스 포트 번호는 다름.
- 이 네트워크에서 source/destination에 있는 데이터그램은 source, destination에 대해 10.0.0/24 주소를 가짐.
- 로컬 네트워크의 모든 장치에는 로컬 네트워크에서만 사용할 수 있는 사설 IP주소공간에 32bit 주소가 존재
[NAT 장점]
- 모든 장치에 대해 공급자 ISP에서 하나의 IP 주소만 필요
- 외부에 알리지 않고 로컬 네트워크의 호스트 주소 변경 가능
- 로컬 네트워크에서 장치의 주소를 변경하지 않고 ISP 변경 가능
- 보안 : 로컬 네트워크 내부의 장치는 직접 주소 지정X, 볼 수 X
[NAT 역할]
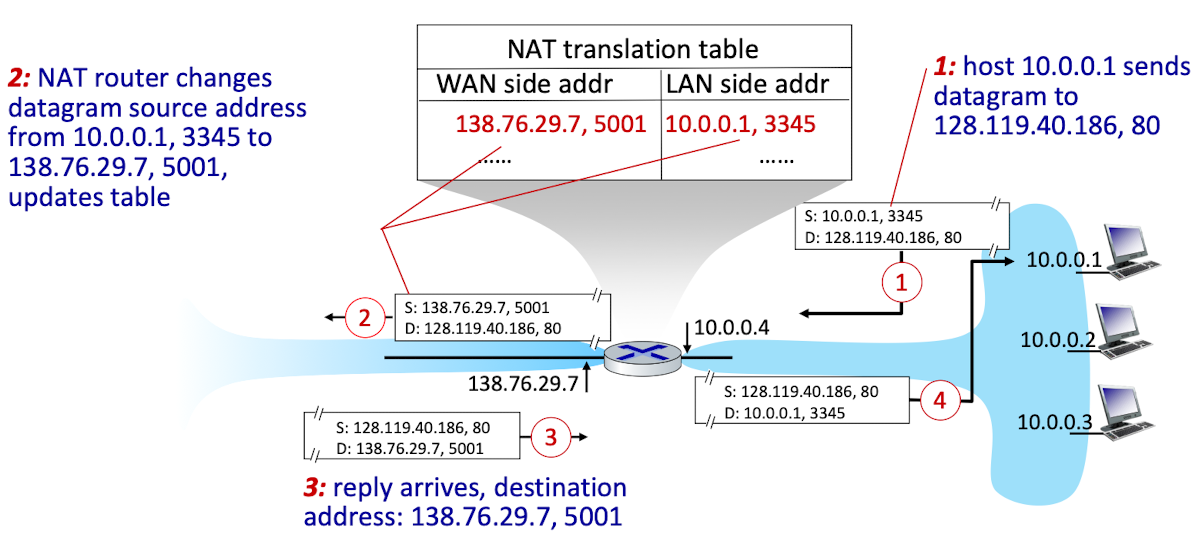
NAT라우터는 투명하게 구현되어야 한다. (나의 본질은 모르게 서로서로 알아서)
- 나가는 datagrams 헤더 변경
: 내부에서 사용하는 IP 포트 번호 대신 라우터 IP 주소와 새로운 포트 번호를 설정
(Source IP address, port #) -> (NAT IP address, new port #)- NAT 변환 테이블 기억
- 수신 데이터그램의 대상 필드에서 NAT테이블에 저장된 해당 필드로 변경
: (NAT IP address, new port #) -> (Source IP address, port #)
[NAT 논란]
- 라우터는 3계층에서 처리해야 한다.
- 주소 부족은 IPv6에서 해결되어야 한다.
- end-to-end 규칙 위반 : 네트워크 계층 장치에 의한 포트 번호 조작)
- NAT traversal : 클라이언트가 NAT 뒤에 있는 서버에 연결하려는 경우는?
- 나가기전에는 테이블에 내 정보가 안 쓰여짐
- 서버는 처음부터 접속을 받아야하는데, 처음부터 내가 받으려고 할 때 문제가 발생- 그럼에도 NAT는 가정용 및 기관용 망, 4G/5G 셀룰러 망에 광범위하게 사용.
4.3.4 IPv6
- 32bit 주소 공간 할당
- 간소화된 40byte 고정된 헤더 길이 -> 빠른 프로세싱/포워딩
- "flows"라는 개념 채택 : 패킷 단위가 아닌, 하나하나 어떤 서비스의 흐름들끼리 디테일한 제어 가능
- IPv4보다 심플한 구조
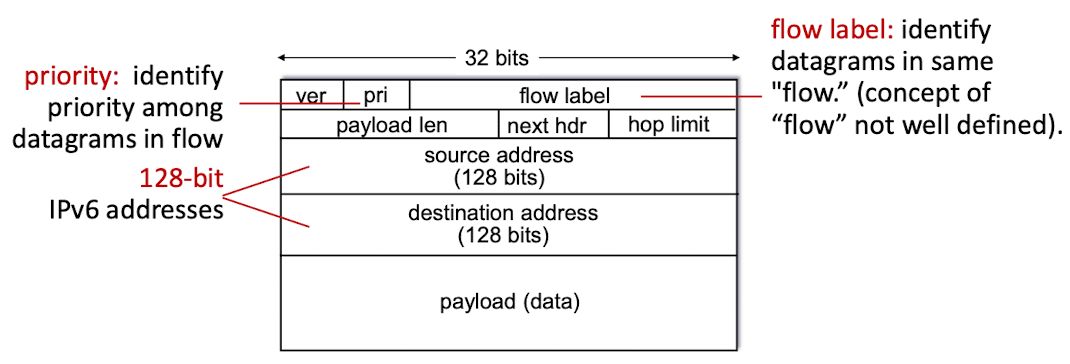
[IPv6 데이터그램 포맷]
- 버전
- 4bit
- IP 버전 번호 인식- priority
- flows에서 데이터그램 사이에 우선순위 식별- 플로우 레이블
- 20bit
- 흐름 인식
- 플로우 별로 디테일한 제어- 페이로드 길이
- 16bit
- IPv6 데이터그램에서 고정 길이 40byte 패킷 헤더 뒤에 나오는 바이트 길이
- 부호없는 정수
- 옵션들 모두 처리하도록 설계
- 헤더 고정 -> 시작점 따로 명시 불필요- 다음 헤더
- 자신의 페이로드가 어떤 것인지 구분
- 데이터그램의 내용이 전달될 프로토콜(ex. TCP, UDP) 구분
- IPv4에도 있던 것- 홉 제한
- 라우터가 데이터그램을 전달할 때마다 1씩 감소
- 홉 제한 수가 0보다 작아지면 라우터는 데이터그램을 버림
[IPv4와의 비교]
- No checksum
- IP패킷의 빠른 처리
- IPv4 헤더 체크섬은 모든 라우터마다 수행 (비용 Up!)- No 단편화/재결합 (fragmentation/reassembly)
- 출발지와 목적지만이 수행
- 너무 커서 라우터가 출력링크로 전달 불가하다면 -> 데이터그램 폐기 (ICMP오류 메시지를 전송)
- 단편화/재결합은 시간 Up! 라우터에서 기능 삭제하고 종단에서 수행
- IP 전달 속도 Up!- No options
- 더 이상 표준 IP 헤더 필드X
- '다음 헤더' 중 하나가 될 수 있음. (사라진 것은 X)
- 옵션이 없기에 헤더가 고정 길이의 40byte IP 헤더를 갖게 됨.
[IPv4 -> IPv6]
- flag day : 모든 장비 종료하고 업그레이드 하는 날 설정 (불가능!)
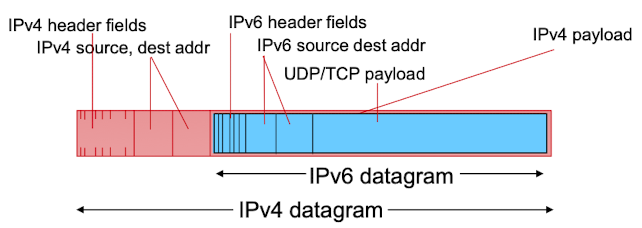
- 터널링
- IPv4와 IPv6가 과도기 단계에서 조화롭게 사용하는 방법
- 터널 : 두 IPv6 라우터 사이에 있는 IPv4 라우터들
- 듀얼 스텝 : IPv4, IPv6도 인지
- 둘 중 하나만 인지하는 경우 : IPv4 헤더 안에 페이로드로 IPv6를 담고 2계층 헤더를 씌움.
-> IPv4로 인식하도록 눈속임해주는 역할
4.4 일반화된 포워딩 및 소프트웨어 기반 네트워크(SDN)
4.4.1 매치
4.4.2 액션
[일반화된 포워딩 : 매치 플러스 액션]
- 프로토콜 스택의 다른 계층에서 다른 프로토콜과 관련된 여러 헤더 필드에 대해 '매치'를 수행할 수 있는 일반적인 방법
: IP가 같은 애들을 찾아서 (Match) 특정 포트 번호를 정해서 보내줌 (Action)- 포워딩
1) 목적지 기반 포워딩
- 매치 기준을 목적지 IP에만 두는 것
2) 일반화된 포워딩
- 목적지 IP외에 다른 헤더의 필드들을 기준으로 두고 포워딩에 이용하는 것
- 많은 액션이 가능해짐.- 액션
- 하나 이상의 출력 포트로 패킷 전달
- 인터페이스에서 나가는 패킷을 로드 밸런싱
- 헤더값 다시 작성
- 의도적으로 패킷 차단/삭제
- 특수 서버로 패킷 전송- 매치 플러스 액션 테이블은 원격 컨트롤러를 통해 계산, 설치, 갱신
[플로우 테이블의 추상화]
- flow : 헤더의 여러 가지 필드 중에서 기준으로 잡는 것
- flow table : 일반화된 포워딩에서의 포워딩 테이블
- 일반화된 포워딩
- match : 패킷 헤더 필드에서 동일한 것을 찾기
- actions : match했다면 그에 맞는 동작 명시
ex. 버리기, 전달하기, 수정하기, 컨트롤러에게 전송하기 등
- priority : 중복된 매치가 발생한다면 구별할 수 있는 우선순위
cf. 목적지 기반 포워딩에서는 최장 프리픽스 매치를 사용
- counters : 플로우 테이블 엔트리와 마지막으로 갱신된 테이블 엔트리 이후에 매치된 다수의 패킷
-> 라우팅 테이블로만 되어있던 기존의 포워딩보다 높아진 자유도, 유연한 프로그래밍- "Network programmability"의 간단한 형태
- 패킷당 프로세싱 가능
[오픈플로우 Openflow]
- SDN (Software Defined Network)
- 라우터의 가장 중요한 두 가지 기능 분리
- 포워딩, 라우팅
- 이 중 컨트롤을 분리해서 원격에 있는 리모트 컨트롤러가 동작하게 하는 구조- OpenFlow
- 리모트 컨트롤러와 SDN 사이의 통신에 사용되는 프로토콜
- 매치 플러스 액션 포워딩의 개념화
- 컨트롤러, SDN 혁명의 개념을 개척한 가시적인 표준
- 명확하고 간결한 방식으로 SDN 개념 및 기능 도입
- 다양한 헤더에 있는 필드들을 이용해서 라우팅 사용 가능 -> 유연한 처리

4.4.3 매치 플러스 액션 작업의 OpenFlow 예
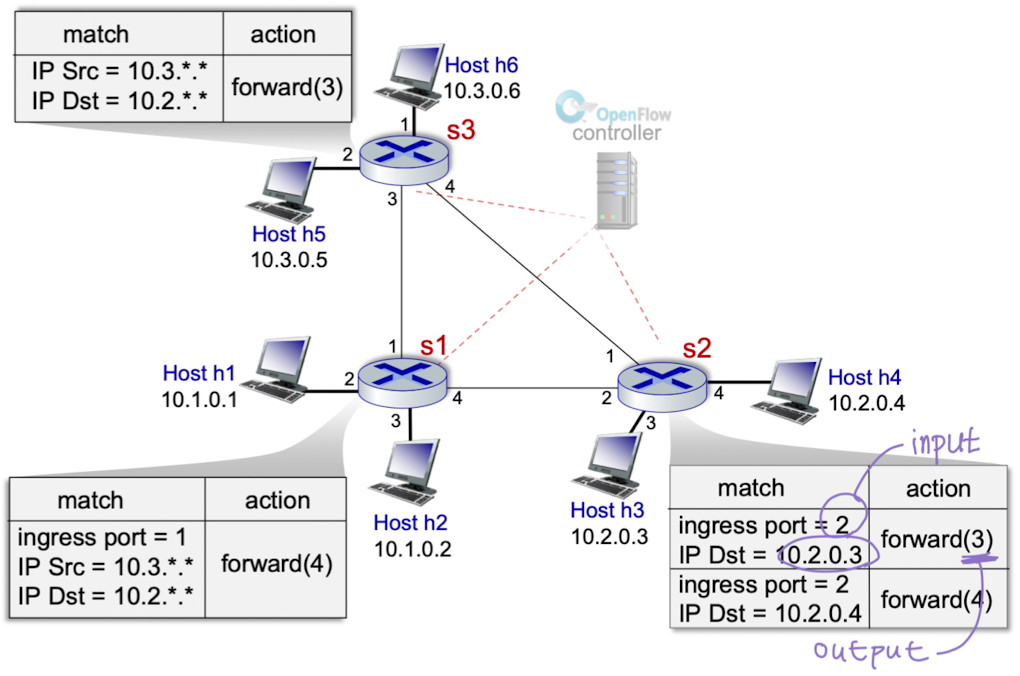 컨트롤러가 테이블 내용 작성해서 내려주면 된다.
컨트롤러가 테이블 내용 작성해서 내려주면 된다.
- 간단한 포워딩
- 로드 밸런싱
- 방화벽
- NAT
- Router
- Switch
4.5 미들박스
- 미들박스
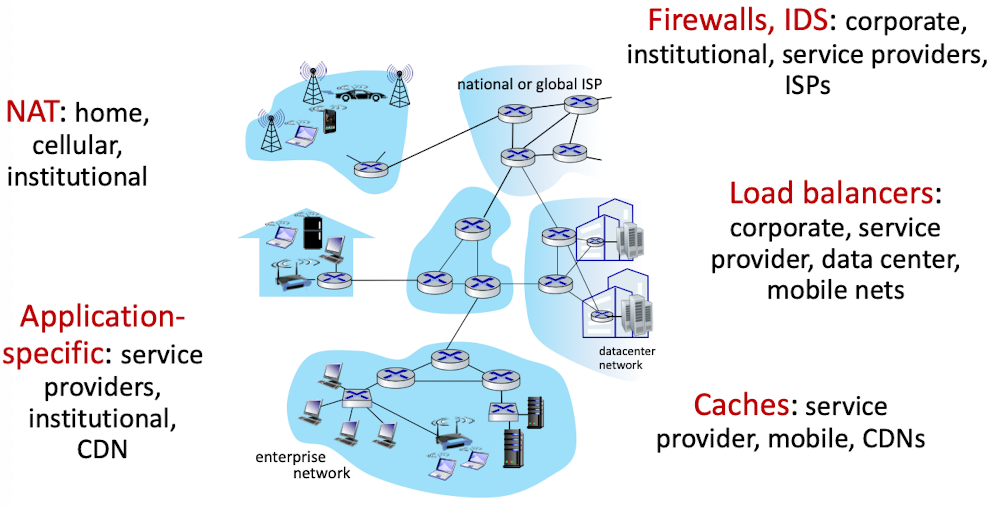 - 소스 호스트와 목적지 호스트 사이의 데이터 경로에서 IP 라우터의 주된 기능 이외의 기능을 수행하는 모든 중개 장치
- 소스 호스트와 목적지 호스트 사이의 데이터 경로에서 IP 라우터의 주된 기능 이외의 기능을 수행하는 모든 중개 장치
- 라우터의 주된 기능 : 포워딩, 라우팅 - 미들박스 유형
- NAT 변환 : NAT 박스는 사설 네트워크 주소 체계를 구현하여 데이터그램 헤더 IP주소 및 포트 번호를 다시 작성
- 보안 서비스 : 방화벽은 헤더 필드값을 기준으로 트래픽 차단, DPI같은 추가 처리를 위해 패킷 리다이렉션
침입 탐지 시스템(IDS)는 미리 결정된 패턴 탐지 후 패킷 필터링
- 성능 향상 : 압축과 같은 서비스 수행
원하는 서비스를 제공할 수 있는 서버 집합 중 하나에 대한 서비스 요청의 로드 밸런싱을 하는 주체 - 미들박스 특징
- 초기 : 독점 (폐쇄) 하드웨어 솔루션
-> 개방형 API를 구현하는 화이트박스 하드웨어로 이동
- 매치 플러스 액션을 통한 프로그래밍 가능한 로컬 액션들.
- 소프트웨어의 혁신/ 차별화를 향한 움직임
- SDN : 프라이빗/퍼블릭 클라우드에서 자주 사용되는 중앙 집중시 제어 및 구성 관리
- 네트워크 기능 가상화(NFV) : 화이트 박스 네트워킹, 컴퓨팅, 저장을 통한 프로그래밍 가능한 서비스들.
[IP 모래시계]
- 초창기 IP 모래시계
- 위, 아래 계층이 독자적이고 많은 프로토콜로 구성되어있음
- IP 계층은 단 하나의 유일한 프로토콜 -> "thin waist"
- IP : 인터넷 기반의 통신을 하고자 하는 모든 디바에스에 탑재되어야하는 중요한 프로토콜- 중반기 IP 모래시계
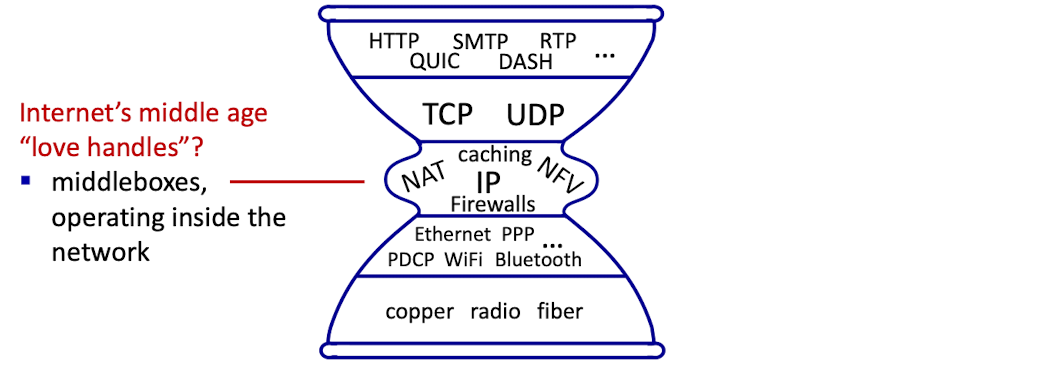
[인터넷의 아키텍처 원리]
- RFC1958
- 인류가 구축한 가장 크고 복잡한 공학 시스템의 개발을 이끈 구조적 원칙이 실재로 존재한다면 위와 같은 원칙이 정말로 최소임을 시사함.
- " 커뮤니티는 연결성을 지향하고 도구는 인터넷 프로토콜이며 지능은 네트워크에 숨겨진 것이 아닌 종단 간이다."- 세 가지 기본 신념
1) 간단한 연결
2) IP프로토콜 : 좁은 허리
3) 네트워크 종단의 지능, 복잡성
