[OS 공룡책] Ch10. Main Memory
Operating System

Chapter 10: Main Memory
과제4 https://github.com/j-nary/Page_Replacement_Algorithm
Background
Virtual Memory
- 필요한 것만 할당, 최대공간은 필요할 때만 제공
- process가 필요할 때마다 조금씩 줌
- 동시에 실행시킬 수 있는 process 개수 증가 → 병렬성, 성능 향상
- 장점
- process 생성 속도 증가
- swap 시간 줄어듬
- 주소공간 아낄 수 있음
- OS가 할 일이 많아졌지만 성능은 기하급수적으로 증가
- 단점
- page fault 발생 시 성능 저하 → 필요한 정보가 memory 공간에 없을 때
- page fault 발생 시 성능 저하 → 필요한 정보가 memory 공간에 없을 때
- vfork() : 메모리 할당 안 해주고 fork 생성하는 것 → fork()보다 속도 훨씬 빠름
Virtual-address Space

- virtual memory의 일부만 physical memory에
- heap : 아래 → 위 / stack : 위 → 아래
- dynamic하게 할당되는 공간 대부분 사용 X
- dynamic하게 요구할 때만 할당
- memory mapping : valid bit 활용
-
메모리에 load 됐는지 여부 표시
-
frame number + valid bit
→ virtual memory를 지원하는 paging system
-
- 지원방법
- Demand paging : 실제 필요할 때 페이지 단위로 불러옴
- Demand segmentation : 실제 필요할 때 세그먼트 단위로 불러옴
Demand Paging
Demand Paging
- pager 필요
- 필요할 때마다 page 단위로 불러옴 (:= 스와퍼)
- paging : 디스크 → 메모리
- page 단위로 virtual address → physical address 매핑
- invalid reference → abort
- not-in-memory(page fault) → memory에 불러오기
- in-memory → MMU로 주소 변환 후 data 가져오기
- invalid 면 page fault handling 필요
Valid-Invalid Bit in Page Table
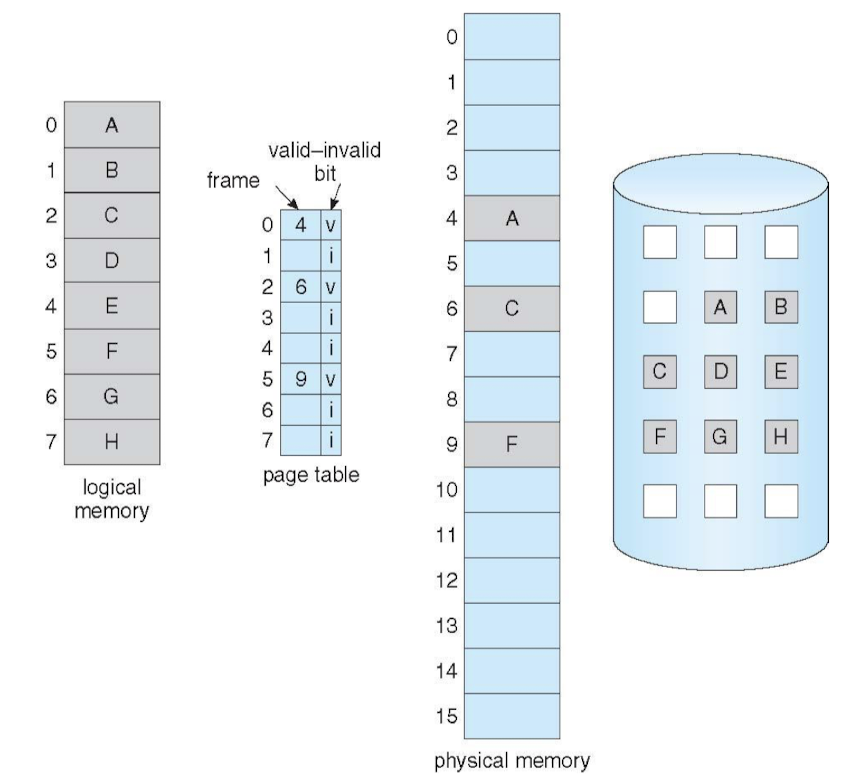
- 1 : 1 mapping → 프로세스 termination되면 메모리 해제 n : 1 mapping → termination 전에 새로운 프로세스에게 양보해줄 필요 발생 → swap space에 쫓아냄 : termination될 때까지 (File system에서 매번 가져오면 시간이 오래 걸리니까)
- v : in-memory
- i : not-in-memory → page fault
Page Fault
- table 탐색
- invalid이면 page fault
- free frame list 조회
- 어디가 비어있는지 확인
- disk operation을 통해 해당 frame에 load
- validation bit : v로 변경
- page fault로 인해 멈춘(wait) 프로세스 재개
- ready queue로 보냄
- page fault도 하나의 interrupt
Demand Paging
- pure demand paging
- demand paging의 최대 경우
- 프로세스 시작 시 메모리 공간 할당 0 → 시작부터 page fault
- 메모리는 가장 절약, but 성능 저하 → 보통 메모리 페이지 한 두개정도는 할당함
- locality of reference
- 실제 page fault가 생각만큼 많이 발생 X
- 100만번당 한 번 정도 발생 → 이 이상 발생하면 OS가 잘못하고 있는 것
Performane of Demand Paging
- Stages in Demand Paging
-
OS에 의한 trap
- page fault 발생 → trap
-
register, process state 저장
- context switching
-
page fault interrupt인지 확인
-
page reference 합법적 → page 위치 확인
-
free frame ← disk : read
- read 요청 완료될때까지 queue에서 wait
- device latency time 대기
- free frame으로 페이지 전송 시작
-
기다리는 동안 CPU 다른 사용자에게 할당
-
디스크 I/O 하위 시스템에서 interrupt 수신 : I/O 완료
-
다른 사용자의 register, process state 저장 : 새로 시작한 process 멈춤
-
disk에서 interrupt 발생했음을 확인
-
페이지 테이블 등의 테이블 수정
-
CPU가 이 프로세스에 다시 할당될 때까지 wait
-
register, process state, new page table 복원 → 중단된 명령 재시작
-
- memory → HDD,SSD
- Access
- 트랙 돌려서 해당 섹터가 내 밑에 오게 하는 데까지의 시간 = Access time
- HDD보다 SSD가 더 빠름
- 트랙 돌려서 해당 섹터가 내 밑에 오게 하는 데까지의 시간 = Access time
- Transfer
- 찾았으면 해당 data가 I/O bidge를 통해 읽어 들어와야 함
- bus의 bandwidth에 의해 결정 : bandwidth = 10, data = 100 → 10번 옮겨야함
- Access
Effective Access Time (EAT)
- 0 ≤ p = page fault rate ≤ 1
- EAT = (1 - p) x memory access
- p x (page fault overhead + swap page out + swap page in)
- Example>
- Memory access time = 200ns
- Page fault service time = 8ms = 8000000ns ( 1s = 1000ms = 1000,000,000ns )
- EAT = (1-p) 200 + p 8000000 = 200 + p * 7999800
- 40만번 중 한 번 page fault 발생 시 메모리 접근 속도 10% 느려짐
Demand Paging Optimizations
💡 1. virtual memory에 한 번 load된 process는 가급적 디스크의 파일 시스템을 거쳐 저장하는 게 아니라, swap space에 로딩했다가 완전히 swap space에서도 지워주는 것 2. copy-on-write- 디스크에서 읽어오면 swap space로 전송
- swap space
- 초창기 : 디스크에서 읽어오면 swap space로 바로 로딩 → 처음 프로세스 생성시 속도 느려짐, swap space 공간 낭비
- page in 은 disk로부터 (frame에 로딩) page out은 swap space로
- 초창기 : 디스크에서 읽어오면 swap space로 바로 로딩 → 처음 프로세스 생성시 속도 느려짐, swap space 공간 낭비
- memory
- anonymous memory
- 현재 프로세스가 실행하면서 생성 중인 메모리 → 날아가면 날아가버림
- file과 연결 X → 대부분 stack, heap에
- 현재 프로세스가 실행하면서 생성 중인 메모리 → 날아가면 날아가버림
- mapped memory
- file과 연결 O → 대부분 static, 전역변수에
- Dirty, Modified block : write만 하고 실제 디스크에 동기화시켜주지 않은 파일
- 보통은 디스크에 백업(안정성), swap space 쫓아냄(어쩔 수 없이 메모리 비워줘야하니까)
- valid-invalid bit 옆에 dirty bit → 이왕이면 clean한 process 쫓아냄
- anonymous memory
- Mobile system
- swap 영역 충분 X (메모리 공간 부족) → swapping 지원 X
- read-only space 버리기 → android : read-only중 우선순위 낮은 애들 먼저 버리기
- swap 영역 충분 X (메모리 공간 부족) → swapping 지원 X
Copy-on-Write
Copy-on-Write
- 메모리 관리 기법 중 하나
- 프로세스 생성 시 physical memory 할당 X
-
read : 같은 공간 동시에 읽는 것 허용
-
write : 필요한 프로세스에게 메모리 새롭게 복사해서 할당
→ 서로 다른 곳을 보게 됨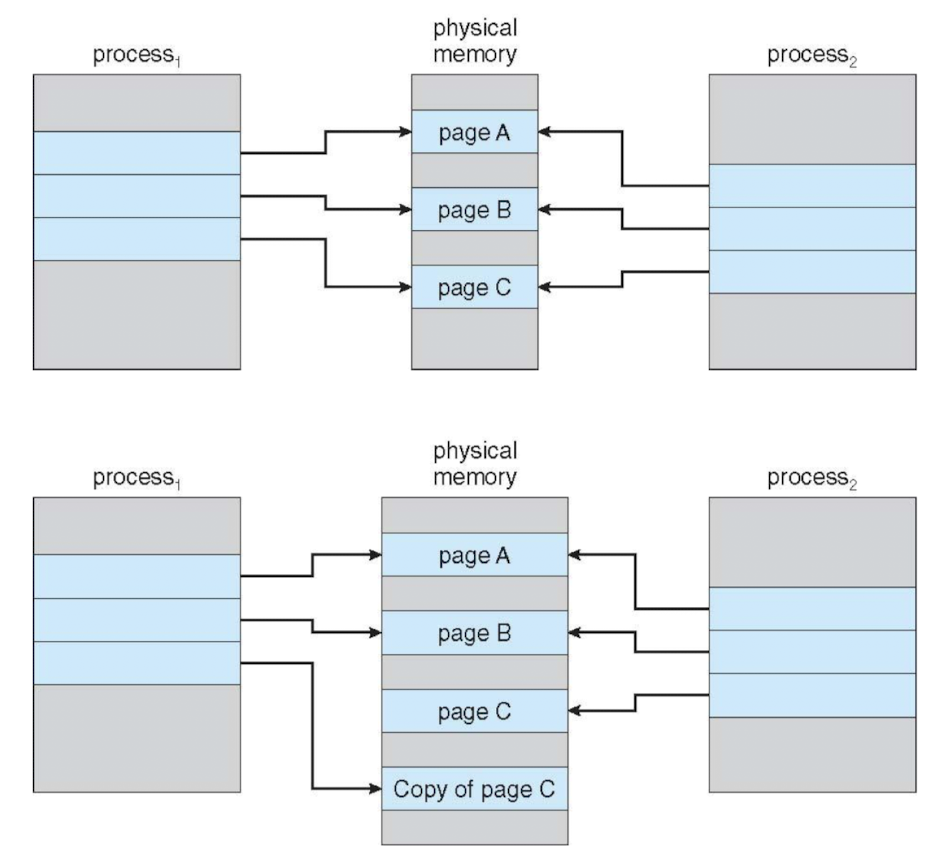
-
- zero-fill-on-demand pages
- pool : free pages 집합
- 프로세스 할당 전 메모리의 모든 비트 = 0
- 항상 free frame 유지해야함 → demand paging 발생 시 빠르게 free frame 할당 → free frame 충분 X : demand paging 지연, 성능 저하
- 현재 사용하지 않는 프레임을 미리 해제 → 사용 가능한 프레임 찾기 위한 시간 낭비 X
- vfork()
- fork() 시스템 호출의 변형
- 부모 프로세스 일시 중지
- 자식 프로세스 : 부모의 주소 공간 복사없이 사용 → exec() 호출 시 매우 효율적
- 공유 페이지 수정할 때만 페이지 복사본 생성 (COW 지원) → 불필요한 데이터 복사 방지, 성능 향상
virtual memory 주요사항
→ physical memory 부족하기 때문
- frame allocation
- frame을 몇 개 할당할 것인가
- over allocation 방지 → 각각의 프로세스에 최적의 개수의 frame 할당
- static
- page 몇 개 쓰는지 잘 예측해서 할당
- 안 좋음
- dynamic
- 돌아가는 상황 모니터링
- replacement 많이 발생하는 프로세스에 frame 많이 할당
- 이미 할당된 frame을 어떻게 회수할 것인가?
- page replacement
- 이미 할당된 frame을 어떻게 활용할 것인가
- page fault 최소화
- 실제로 사용ㅓ하지 않는 페이지 찾아서 page out
- modify bit 사용
- 페이지가 메모리와 디스크 간 이동할 때 발생하는 오버헤드 최소화
- 수정된 페이지만 디스크로
- 이미 할당된 frame을 어떻게 활용할 것인가
Page Replacement
Page Replacement Algorithm
-
page fault 발생
-
disk에서 요구된 page 위치 찾기
-
free frame 찾기
- free frame 없다면, page replacement algorithm 사용 → victim frame (쫓아낼 frame) 선택
- victim frame이 dirty라면, disk에 write하기 → page fault(페이지 전송) 2번 dirty가 아니라면, 버리기 → page fault(페이지 전송) 1번
- free frame 없다면, page replacement algorithm 사용 → victim frame (쫓아낼 frame) 선택
-
새로운 free frame에 page 할당
→ page, frame table 갱신
-
trap 발생했던 명령어 restart

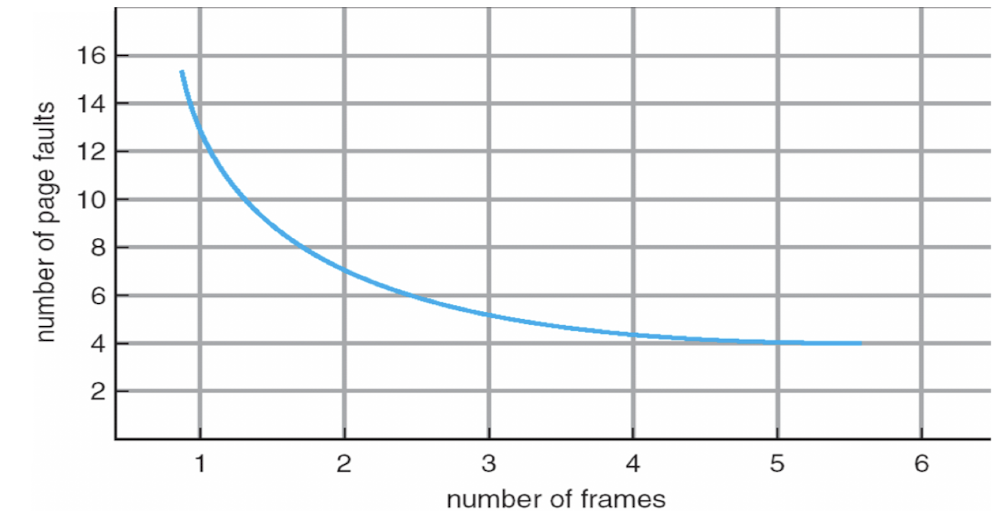
페이지 부재 횟수와 프레임 개수 그래프
-
page number
- 같은 page의 중복된 접근 : page fault 발생 X
- 이용 가능한 frame의 개수 → 알고리즘 성능
- reference string 예 : 7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1
-
6개 페이지에 대한 <1,4,1,6,1,6,1,6,1,6,1> 참조열
- frame 1개 : 매번 참조할 때마다 page fault (11번) → 연속으로 같은 page 참조하는 게 아니라면!
- frame 6개 : 처음 접근 시에만 page fault (3번) ← 1, 4, 6히트
- frame 1개 : 매번 참조할 때마다 page fault (11번) → 연속으로 같은 page 참조하는 게 아니라면!
First-In-First-Out (FIFO) Algorithm
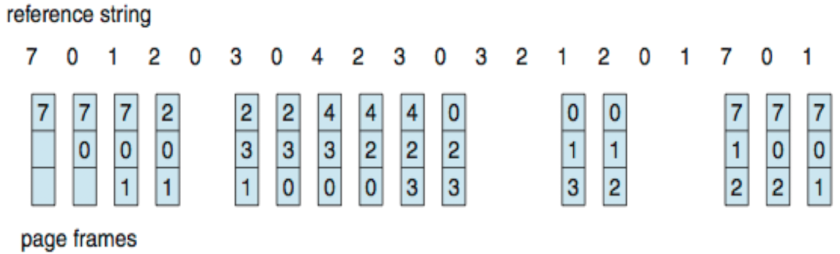
- Reference string : 7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1
- 3frame : 프로세스당 한 번에 메모리에 page 3개 존재 가능
- page fault : 15번 → 성능 최악, 구현 용이
- Belady’s Anomaly (Belady의 이상현상, 모순)
- frame을 더 할당했는데 page fault가 늘어나는 현상
- FIFO에서 발생
Optimal(Belady’s) Algorithm

- Shortest-Job-First 와 동일
- 앞으로 가장 오랫동안 사용 안 될 page 쫓아내기
- 이상적, 구현 X
- Belady’s Anomaly 발생 X
- page fault : 8번
Least Recently Used (LRU) Algorithm

- 가장 오랫동안 사용되지 않은 page 쫓아내기 → 실제로는 이렇게 구현 X
- Belady’s Anomaly 발생 X
- page fault : 12번 → FIFO보다 좋고 Optimal보단 안 좋음
LRU Algorithm Implementation
-
Counter implementation
- time period 동안 몇 번 read write 됐는지
- 쫓아낼 애를 고를 때 동작
-
Stack implementation
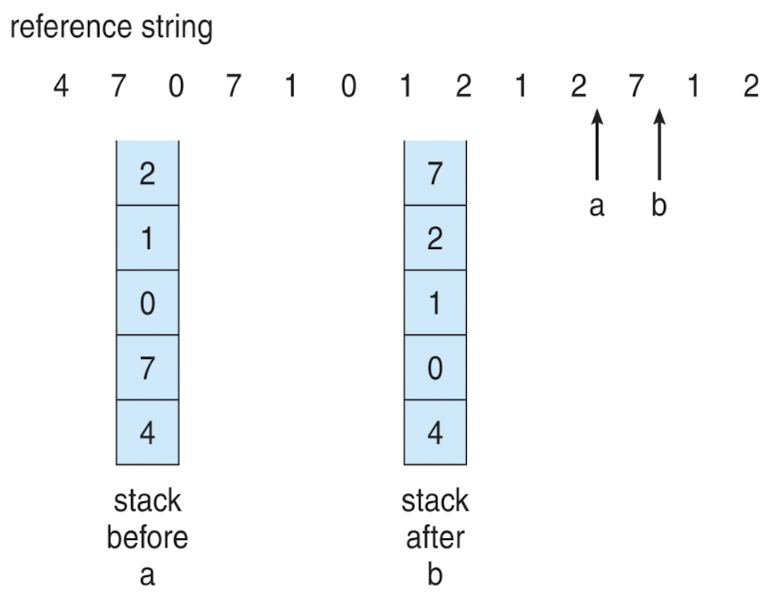
- top : 가장 오래된 page
- 업데이트할 때마다 동작 → expensive
- stack에 존재하는 것 읽었으면 가장 맨 위로
LRU Approximation Algorithms
-
LRU가 좋은 이유 : reference locality
→ 완벽한 LRU : 구현 어려움
-
reference bit
- 참조됐을 때 체크해놓는 비트
- dirty : write 작업 발생 시 1 → dirty = 1 이면 reference도 무조건 1
- 언제, 얼마나의 여부는 모르지만, 로딩된 다음에 참조됐는지 여부 알 수 있음 → 주기적으로 리셋 필요
-
Second-chance algorithm

- 최근에 참조가 많이 됐던 page에게 기회 한 번 더 주기
- One-handed clock algorithm : second-chance algorithm의 일종
- circular queue로 순회 → reference bit = 1이면 0으로 바꾸고 다음 page로 포인터 이동 → reference bit = 0이면 바로 쫓아내기
Enhanced Second-Chance Algorithm
- dirty bit, reference bit 둘 다 활용 → Two-handed clock algorithm
- (reference, modify)
- (0, 0) : 바로 replace
- (0, 1) : replace 전에 write out 필요
- (1, 0) : 곧 다시 사용될 가능성 높음
- (1, 1) : 곧 다시 사용될 가능성 높고 replace 전에 write out 필요
Counting Algorithm
- 참조할 때마다 계수를 하여 그 값을 판단하는 알고리즘 → 잘 사용 X : 높은 비용, 최적 알고리즘에 근사 X
- LFU (Least Frequently Used) Algorithm
- reference locality → 참조횟수가 가장 적은 페이지 교체
- 일시적인 시점에 집중적으로 사용되면 비효율적
- 구현방법 : 참조횟수를 일정 시간마다 오른쪽 쉬프트(영향력 감소)
- reference locality → 참조횟수가 가장 적은 페이지 교체
- MFU (Most Frequently Used) Algorithm
- fairness → 가장 적은 참조횟수를 가진 페이지가 앞으로 사용될 거라는 판단
- 당연히 잘 안 씀
- fairness → 가장 적은 참조횟수를 가진 페이지가 앞으로 사용될 거라는 판단
Page-Buffering Algorithm
- Page replacement algorithm과 병행
- vitim과 새로 들어올 page간 디스크와 메모리 사이 두 번 오고가야함 → 성능 안 좋음
- 가용 프레임 여러 개를 pool로 유지
- 디스크에서 쫓아내지 않고 free frame list에만 올려둠
- 다시 참조가 들어오면 disk가 아니라 데이터만 다시 read → valid bit만 v로 바꿔주기
- 남겨둔 여분 없어졌을 때만 진짜 replacement 실행
Allocation of Frames
Allocation of Frames
- 동시에 동작하는 여러 프로세스에게 제한된 가용 메모리를 효과적으로 할당할 수 있는 방법 고려 → 각 프로세스에게 할당되는 메모리 프레임 수 지정 필요
- Minimum보다는 많이
- frame 수 감소 → page fault 확률 증가
- 명령어 실행 끝나기 전에 page fault 발생 시 명령어 재실행 → 최악의 상황
- 프로세서의 명령어 집합 구조에 의해 결정
- Maximum보다는 적게
- 물리 메모리에 의해 결정
Allocation Algorithm
-
Equal allocation
- 남아있는 frame / process 개수
- 설계 용이
- 모든 process에게 동일하게 frame 할당
- 필요보다 많이 할당 : memory underutilization
- 필요보다 적게 할당 : 빈번한 page fault
-
Proportional allocation
- process size에 따라 frame 할당
-
로딩할 때 PCB 구조에 process size 정보 얻을 수 있음
-
프로세스 크기 / 전체 프로세스 크기의 합 비율로 할당

-
- process size와 동적으로 요구하는 메모리의 양이 항상 정밀하지는 X
- ex. 스트리밍 : prefetch가 더 중요, 안 쓰는 애들 빨리 버리는 게 나음
- proportional이 항상 좋지는 X
- 작은 메모리의 빈번한 read/write → 실제 frame이 많이 필요함
→ size보다는 process의 성격에 따라 우선순위를 주는 것이 더 효율적
- process size에 따라 frame 할당
-
Priority allocation
- proportional의 일종
- process 종류에 따라 frame 할당 → 우선순위 높으면 size만큼 할당
Global vs. Local Allocation
- Global replacement
- 동적으로 frame 개수 변경 → 다른 프로세스들이 사용 중인 공간 중 쫓아낼 것을 결정
- 리눅스, 윈도우, macOS 가 사용
- 특정 process에게 할당되는 frame 개수가 동적으로 변화
- 단점 : 수행 시간 예측 어려움
- 장점 : 전체적인 메모리 사용 면에서 효율적
- 동적으로 frame 개수 변경 → 다른 프로세스들이 사용 중인 공간 중 쫓아낼 것을 결정
- Local replacement
- 단점 : 메모리 비효율적 사용 → underutilization 발생
- 장점 : 모든 process에게 유사한 실행시간 보장
- ex. Real Time Process
Non-Uniform Memory Access
- UMA & NUMA
-
Uniform Memory Access
- access 시간 동일
-
Non Uniform Memory Access
- CPU와 memory의 물리적인 위치에 따른 access 시간 상이→ OS가 가까운 frame 할당해주면 좋음 - locality group - 메모리 범위 제한 - 제한된 범위 내에서만 스케줄링, frame 할당 - 특히 kernel process 의 경우→ UCA & NUCA (cache)
-
Thrashing
Thrashing ⭐️
-
OS가 메모리 할당 시 가장 피해야할 문제점
→ DVS(전압 동적으로 조절), DFS(cpu frequency 동적으로 조절)
-
스케줄링 시 CPU Utilization 고려
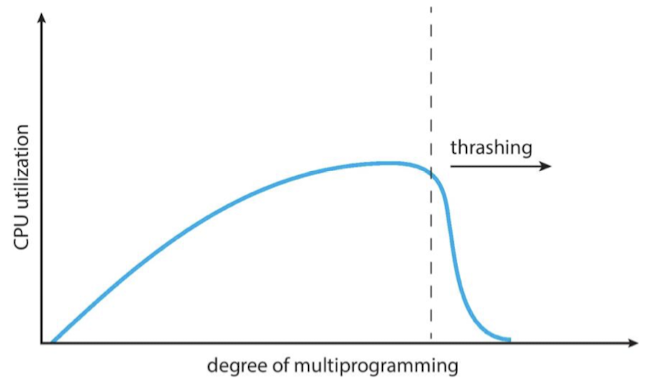
- 낮으면 : 돌아가는 process 늘려주기
- 계속 늘리다보면 갑자기 뚝 떨어짐 : thrashing 발생 → 어느 순간 메모리만 바쁘고 CPU는 노는 현상 : 돌아가는 process가 많다보니 계속되는 page fault → 돌아가는 process 늘려주려다 보면 메모리는 계속 바빠짐 (악순환)
-
CPU만 보고 스케줄링하면 안 됨
→ threshold(임계값) 초과하는지에 대한 모니터링 필요
Demand Paging and Thrashing
- Locality model
- process가 요구한 메모리를 frame에 다 할당하지 않아도 정상동작할 수 있었던 이유
- paging 뿐만 아니라 thrashing에도 영향을 미침
- thrashing 발생
- 돌아가고 있는 process들의 locality 합 > 가용 가능한 메모리
- 해야될 일의 양(Working-set)만큼만 → locality 보장
- 메모리 모니터링 기법
- Working-Set Model
- Page-Fault Frequency
Working-Set Model
-
Working-Set Model
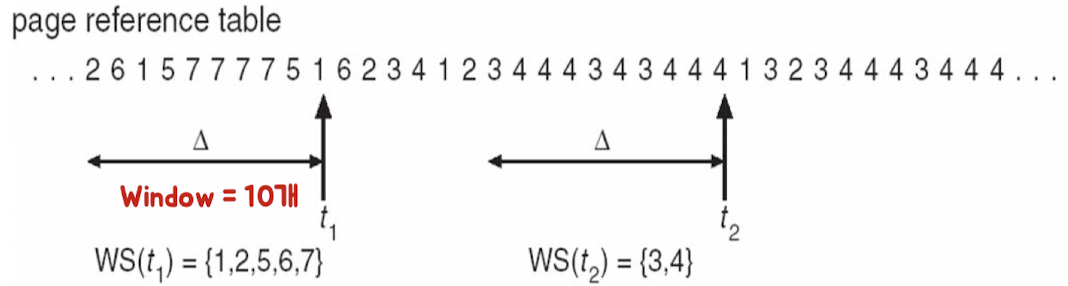
- 해당 페이지가 단위 시간동안 얼마만큼 참조되는지 동적으로 파악
- working-set window(time window) : 단위시간 (N개) → N개동안 참조되는 페이지 수 count
- 가용 가능 메모리 프레임보다 크면 thrashing 발생 예측
- 매 시간마다 계속 계산 : 구현 복잡, 어려움, 공간 낭비 → approximation 사용
-
approximation
- timer & reference bit
- delta : 모니터링 하고자하는 시간 간격
- ex. delta : 10000 cycle
-
page table 옆에 Reference bit(1bit) 할당
-
cycle마다 reference bit = 0 초기화
→ 페이지가 참조(로딩)됐을 때 reference bit = 1
-
cycle 지난 다음 reference bit = 1 인 page count
좀 더 정확하게 하려면
-
Reference : 2bit, time : 5000
→ 10000번동안 timer 2번 받음
-
첫 번째 타이머 : reference 1번 비트
-
두 번째 타이머 : reference 2번 비트
-
Page-Fault Frequency (PFF)
- Page fault 의 상한값, 하한값 지정
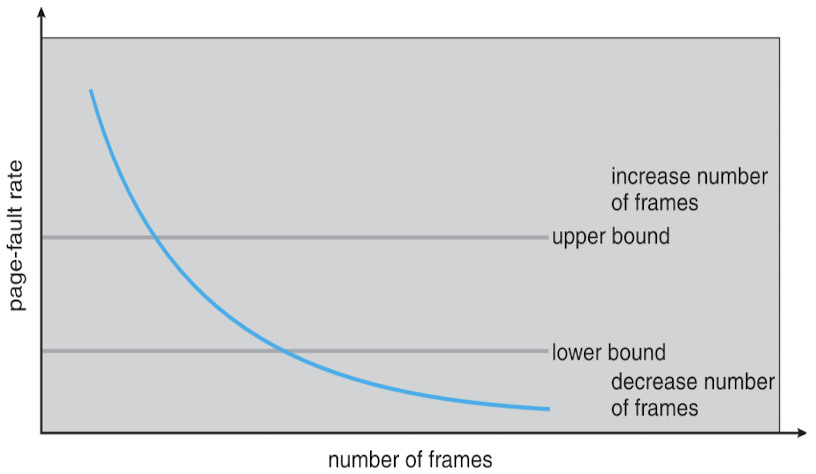
- page fault 확률 측정
- page fault 개수 / 전체 페이지 reference 횟수
- 타임 간격마다 측정
- 하한값보다 낮으면 → frame 남아돈다고 판단하고 frame 줄여줌
- 상한값보다 높으면 → frame 더 할당해줌 → thrashing 방지에 초점
→ 여기까지는 user process에게 메모리할당하는 것 관련된 개념
Allocating Kernel Memory
Allocating Kernel Memory
- 메모리 낮은 주소는 user에게 메모리 높은 주소는 kernel에게
- 메모리, I/O → 1:1 매핑 필요 → page 단위로 끊는 게 쓸모 X
- kernel : user에 비해 더 연속적인 공간이 필요
- kernel process 메모리 기법
-
Buddy System : 메모리 할당 기법
→ user proess처럼 페이지 하나 단위로 할당 X
-
Slab : 메모리 관리 기법
-
Buddy System
-
user : frame table → 2 * n 단위로 paging
kernel : buddy system → 2^n 단위로 paging
→ kernel은 더 연속적인 공간 필요
-
Buddy System Allocator
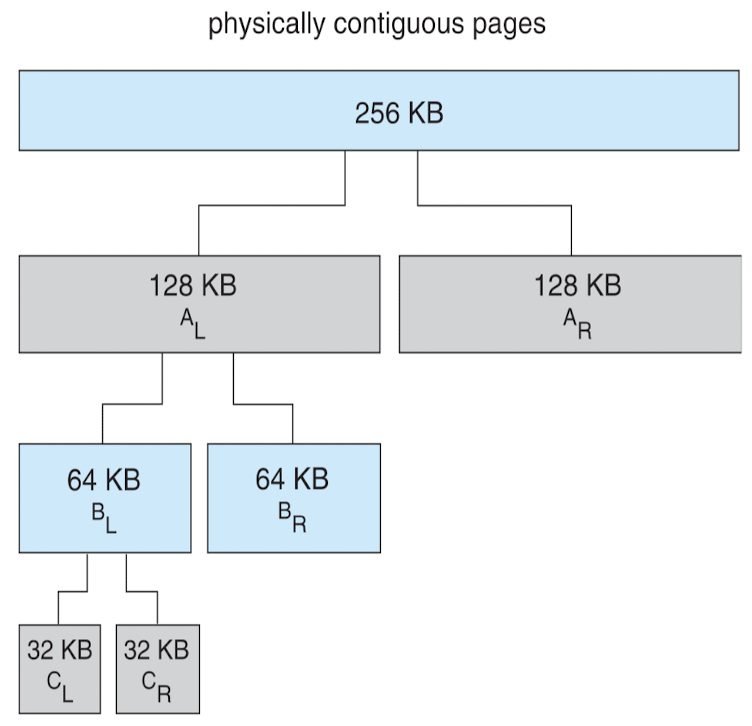
- 만족시키는 최소한의 크기를 buddy로 탐색
- 항상 한 방향으로 쪼갬 : 왼쪽이든 오른쪽이든
- internal fragmentation 으로 인한 메모리 낭비 발생 → 그래도 연속적인 공간을 손쉽게 모을 수 있음
Slab Allocator
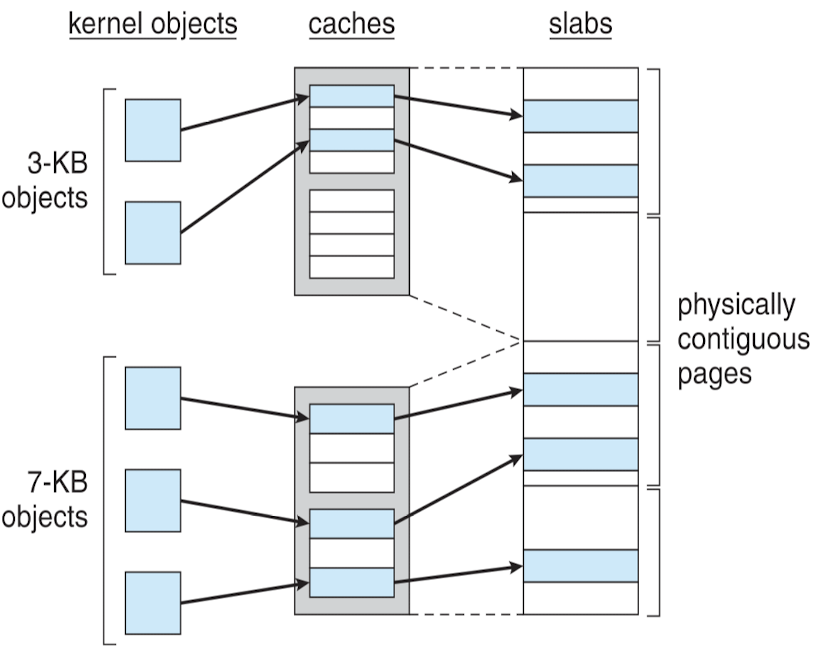
- Slab : 연속된 페이지 묶은 것, page보다 크게 !
- Caches
- 하나 이상의 slab 집합 → 하드웨어 X, 개념적 캐시
- kernel process에서 사용하는 자료구조를 전담하는 역할 → 성격이 비슷한 모든 PCB 한 군데에 모으겠다!
- 부족하면 slab 단위로 추가 → page보다 큰 단위 쉽게 할당
- 하나 이상의 slab 집합 → 하드웨어 X, 개념적 캐시
