
#02. Numpy
NumPy
- Numerical Python
- 숫자로 이루어진 배열을 다루기 위한 전문 도구
- Python의 list와 비교한 장점
- 규모가 커질수록 저장 및 처리에 훨씬 효율적
- 다양한 데이터 처리 library에서 사용 : Pandas, SciPy
숫자로 구성된 배열
- 시계열 자료 : 의료 혈압 데이터, 주식
- 디지털 이미지 처리 및 분석
NumPy 배열
- 생성
import numpy as np arr = [1, 4, 2, 5, 3] n_arr = np.array(arr) #배열 생성 print(arr) > [1, 4, 2, 5, 3] #리스트 <class 'list'> print(n_arr) > [1 4 2 5 3] #넘파이 배열 <class 'numpy.ndarray'> - 특징
- 배열의 모든 요소가 같은 타입
- 일치하지 않을 경우 → 가능한 상위 타입
n_arr = np.array([3.14, 2, 5, 3]) >> [3.14 2. 5. 3.] //실수로 취급n_arr = np.array(['3.14', 2., 5, 3]) >> ['3.14' '2.' '5' '3'] //문자열이 더 상위 타입 - 데이터 타입 명시적 설정
arr = [1, 4, 2, 5, 3] n_arr = np.array(arr, dtype = 'float32') >> [1. 4. 2. 5. 3.] # dtype에 맞춰서 casting - 상위타입도 parsing 가능
+) 실수는 등호비교하면 문제가 생길 수 있음. → 차이가 입실론보다 작은 것으로 비교해야 한다.arr = ['3.14', 2., 5, 3] n_arr = np.array(arr, dtype = 'float32') >> [3.1400001 2. 5. 3.] # 정밀도가 조금 떨어지는 문제 발생 n_arr = np.array(arr, type = 'float64') >> [3.14 2. 5. 3.]
NumPy 배열 속성
- Rank
- 차원의 수 : n_arr.ndim
- Shape
-
배열의 모양 : 각 차원 별로 원소가 몇 개인지 tuple 형태로 반환
n_arr = np.array([1, 4, 2, 5, 3]) print(n_arr.shape) >> (5,) -
len()으로 차원의 수 산출 가능 : len(n_arr.shape) == n_arr.ndim
-
- size
print(n_arr.size) >> 5
NumPy 배열의 값 접근
- 첨자 사용 : n_arr[1]
- 슬라이싱
- 배열명 [start:stop:step]
- 값 지정 X → 기본값 0:차원의크기:1
- 0부터 시작해서 step만큼 건너뛰기
NumPy의 2차원 배열
-
선언
nums = np.array([[1, 4, 2], [7, 5, 3]]) >> [[1 4 2] [7 5 3]] -
2차원 배열에서의 속성
print(nums.ndim) >> 2 print(nums.shape) >> (2, 3) //대괄호 하나씩 깠을 때의 원소 개수 print(len(nums.shape)) >> 2 print(nums.size) >> 6 -
접근
print(nums[0, 2]) >> 2 print(nums[0][2]) >> 2 nums = np.array([[1, 4, 2], [7, 5, 3]]) print(nums[0:1,]), print(nums[0:1,:]) >> [[1 4 2]] # 2차원 배열 <- 슬라이싱 print(nums[:, 1:2]) >> [[4] [5]] print(nums[1, 1:]) >> [5 3] # 1차원 배열 <- 인덱싱 -
실습
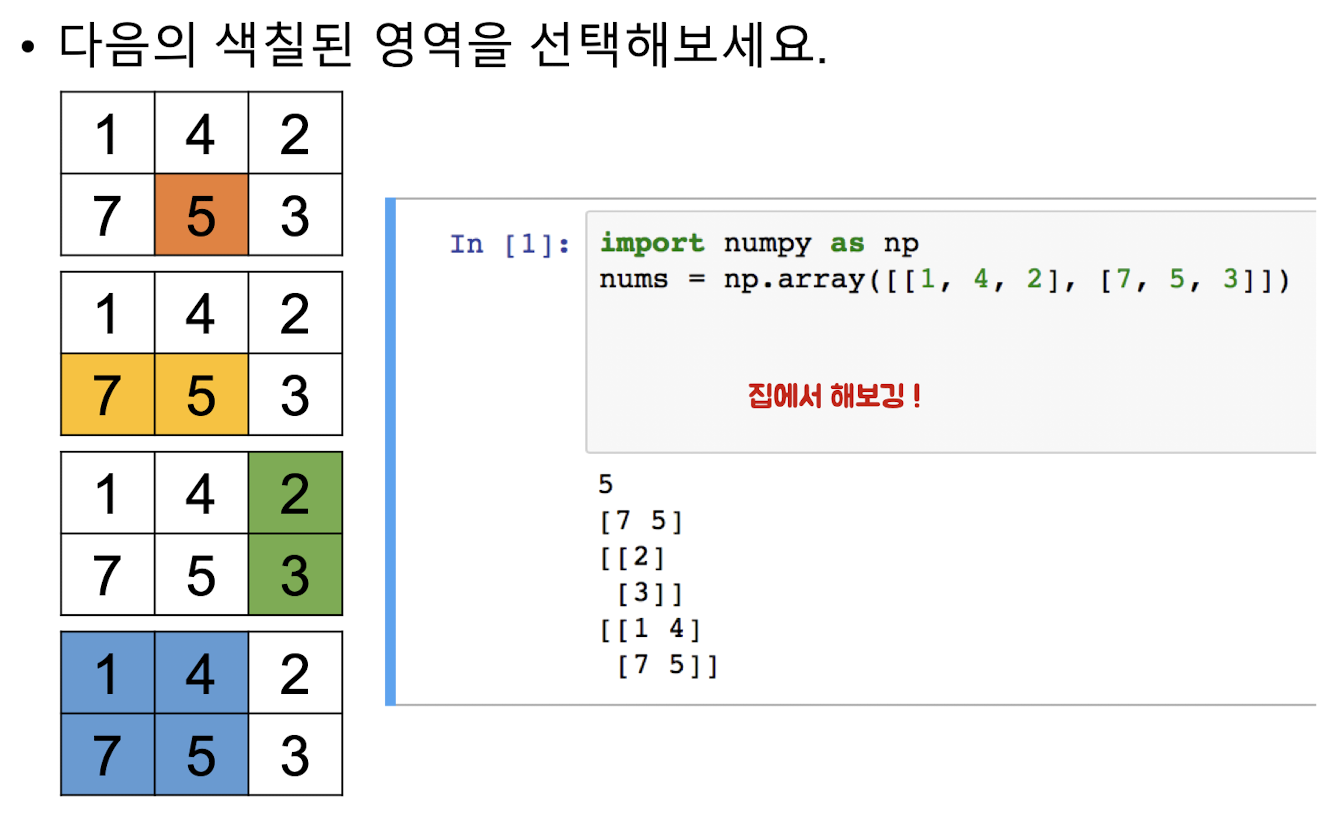

NumPy의 0차원 배열
- Scalar값 하나만 들어가면 NumPy 배열도 존재한다.
nums = np.array(3) print(nums) >> 3 print(nums.ndim) >> 0 print(nums.shape) >> () - 왜 필요한 지 다음 시간에
NumPy 배열 사용 시 주의사항
- 검색/슬라이싱 결과는 참조만 할당
-
독립적으로 사용할 경우 : copy() 함수 사용
ref = nums[1:4] # 원본 반영 cpy = nums[1:4].copy() # 원본 보존, shallow copy print(ref) print(cpy) >> [4 2 5] nums[2] = 10 print(ref) >> [4 10 5] print(cpy) >> [4 2 5]
-
NumPy의 내장 함수를 사용한 배열 초기화
- zeros(shape)
-
모든 값 0인 배열 생성
np.zeros((2,2)) >> [[0. 0.] [0. 0.]]
-
- ones(shape)
- 모든 값이 1인 배열 생성
- full(shape, value)
- 모든 값이 value로 초기화된 배열 생성
- eye(size, k=n)
-
size * size 단위행렬 생성 후 k만큼 이동
→ A x I = Anp.eye(3, k = 1) >> [[0. 1. 0.] [0. 0. 1.] [0. 0. 0.]]
-
- identity(size)
- size * size인 단위행렬 생성
- random.random(shape)
-
0~1 사이 임의의 숫자로 초기화된 배열 생성
np.random.random((2, 2)) >> [[0.41206994 0.76012219] [0.85312486 0.24023191]] -
정규분포를 따르는 난수 : random.normal(shape)
-
[low, high) 사이의 정수형 난수 : random.randint(low, high, shape)
-
- linspace(start, stop, num=?, endpoint=?, retstep=?)
-
start부터 stop까지 num으로 지정된 요소의 수만큼 배열 생성
-
endpoint : 끝값 포함할 지 여부 True/False
-
retstep : 생성한 배열과 함께 step의 크기 return할지 여부 True/False
np.linspace(0, 1, num=5, endpoint=True, retstep=True) >>(array([0. , 0.25, 0.5 , 0.75, 1. ]), 0.25)
-
- arange(start, stop, step, dtype=?)
-
start부터 stop까지 stop 포함하지 않도록 step 단위로 배열 값 생성
-
dtype : 자료형 지정
arange(1, 3, 1) >> [1, 2]
-
행열 전환과 형태 변형
- reshape(shape)
-
내장함수를 이용하여 배열 생성 후 reshape으로 형태 변형
-
기존 배열과 새로운 배열의 아이템 수는 동일해야 함
nums2 = nums.reshape(1, 6) # 원본 반영 X print(nums2) >> [[1 4 2 7 5 3]]
-
- 전치 Transpose
-
nums.T
-
(2, 4) → (4, 2) 로 변형
print(nums) >> [[1 4 2] [7 5 3]] print(nums.T) >> [[1 7] [4 5] [2 3]]
-
- swapaxes(axis_1, axis_2)
- 전치 연산의 일반화된 형태
- swapaxes(0, 1) == T
NumPy 배열의 연결
- concatenate
- 겉포장 하나만 깐다음에 다 붙여서 그 후 전체에 겉포장 하나 씌움
np.concatenate([x, y, z]) >> [1 2 3 3 2 1 4 5 6]grid = np.array([[1, 2, 3], [4, 5, 6]]) np.concatenate([grid, grid]) >> [[1 2 3] [4 5 6] [1 2 3] [4 5 6]] - 가로로 붙이고 싶을 경우 → 축 안 맞으면 runtime error
np.concatenate([grid, gird], axis = 1) >> [[1 2 3 1 2 3] [4 5 6 4 5 6]]
- 겉포장 하나만 깐다음에 다 붙여서 그 후 전체에 겉포장 하나 씌움
- vstack
- 수직 방향으로 결합
- hstack
- 수평 방향으로 결합
NumPy 배열의 분할
- split()
-
np.split(배열명, 분할 지점의 리스트)
grid = np.arange(16).reshape((4, 4)) upper, lower = np.split(grid, [2]) print(upper) >> [[0 1 2 3] [4 5 6 7]] print(lower) >> [[ 8 9 10 11] [12 13 14 15]]
-
- hsplit()
- vsplit()
- dsplit() : depth split
2023.09.14
NumPy 배열 연산
- 유니버셜 함수 UFuncs
- 벡터화 연산 : 배열의 각 요소에 연산 수행
narr = np.array(arr) print((narr - 32) * 5 / 9) - 기본 산술 연산자 활용 가능
- 벡터화 연산 : 배열의 각 요소에 연산 수행
- 기타 유니버셜 함수들
- abs() : 절댓값 함수
- np.absolute() : 복소수도 연산 가능
- 사칙연산 : add(), multiply(), negative(), exp(), log(), sqrt()
- 삼각함수 : sin(), cos(), hypot()
- 비트단위 : bitwise_and(), left_shift
- maximum(), minimum(), min(), max()
a = np.array([0, -1, 2]) b = np.array([-2, 7, 3]) print(np.maximum(a, b)) print(np.maximum(a, 8)) >> [8 8 8] print(np.minimum(a, b)) >> [-2 -1 2] print(np.max(a)) >> 2 print(np.min(b)) >> -2 - sum() : 원소 전체의 합계 구하기, numpy의 경우 다차원 배열도 가능
- 집계함수 : mean(), std(), var(), median(), percentile(), …
grid = np.array([[1,2,3], [4,6,2]]) np.mean(grid) >> 3.0 np.mean(grid, axis = 0) >> [2.5 4. 2.5]
브로드캐스팅
-
두 배열의 차원이 같은 경우 각 요소 단위로 연산 수행
-
둘 중 하나가 스칼라 값인 경우 배열로 확장, 복제 후 처리
a = np.array([0, 1, 2]) print(a + 5) >> [5, 6, 7] -
브로드캐스팅 규칙
-
두 배열의 차원 수 다르면 → 더 작은 수의 차원을 가진 배열 형상의 앞쪽을 1로 채운다.

(3, ) + () → (3, ) + (1) → (3,) + (3,)
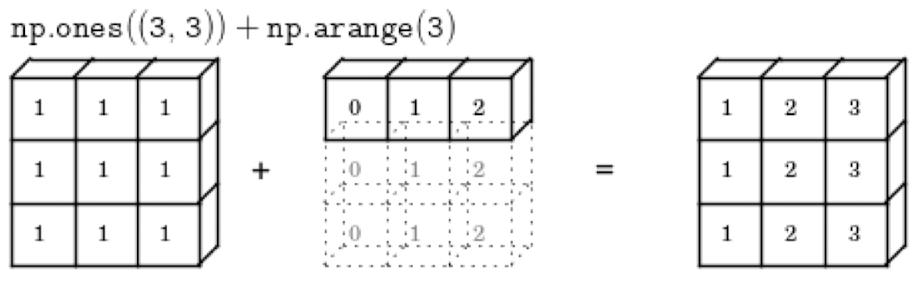
(3, 3) + (3, ) → (3, 3) + (1, 3) → (3, 3) + (3, 3)
-
두 배열의 형상이 어떤 차원에서도 일치X → 해당 차원의 형상이 1인 배열이 다른 형상과 일치하도록
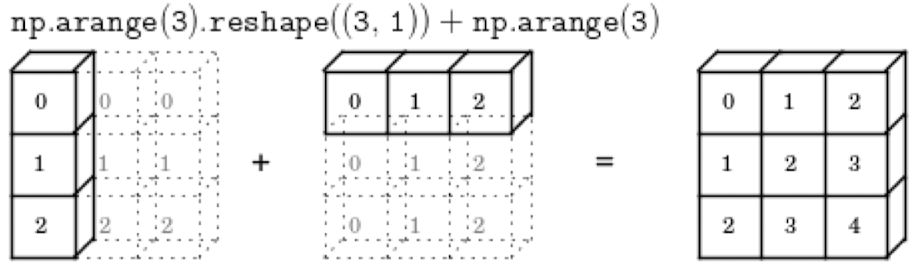
(3, 1) + (3,) → (3, 1) + (1, 3) → (3, 3) + (1, 3) → (3, 3) + (3, 3)
-
임의의 차원에서 크기 일치X , 1도 아니라면 → 오류 발생
(3, 2) + (3, ) → (3, 2) + (1, 3) → (3, 2) + (3, 3)
-
Boolean 배열
- 6보다 작은 값이 몇 개인지 찾기
-
True : 1, False : 0
-
count_nonzero() : True들의ㅂ 합계
rng = np.random.RandomState(0) # seed값 설정 x = rng.randint(10, size=(3, 4)) print(np.count_nonzero(x < 6)) # True 개수 print(np.sum(x < 6)) >> 8x = np.array([[1, 2, 3], [4, 5, 6]]) print(np.sum(x < 3, axis = 1)) >> [2, 0]
-
- any() : 하나라도 참이 있는지 확인
- all() : 모든 값이 참인지 확인
print(np.any((x >= 3) & (x < 6))) # True print(np.all((x >= 3) & (x < 6))) # False - 비트단위 연산자 활용
print(np.sum((x >= 3) & (x < 6)) >> 6 - 마스킹 연산
-
조건에 맞는 값들만 선택하고자 할 때
-
만족하는 값들을 1차원 배열 형태로 출력
print(x[x < 5]) >> [1 2 3 4]
-
