AWS Glue
완전 관리형 ETL(추출, 변환, 로드) 서비스로서 다양한 데이터 소스 및 타겟간 데이터를 쉽게 이동
아키텍쳐
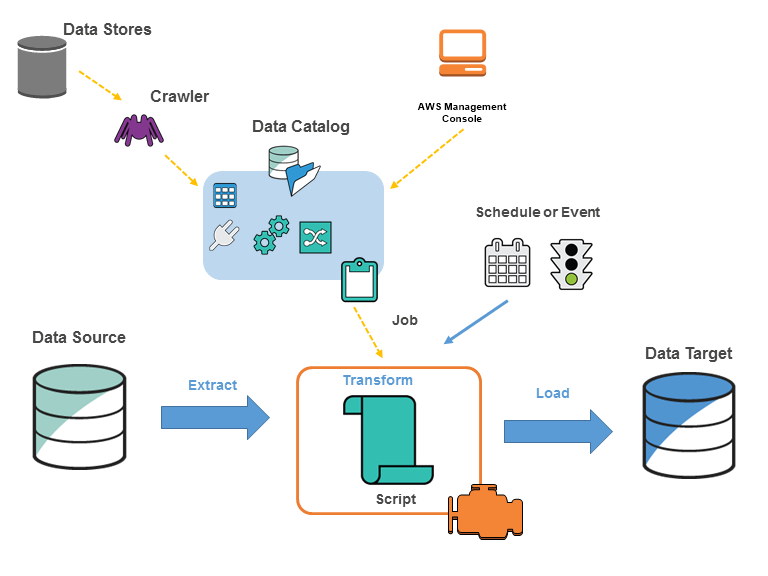
구성요소
- 데이터 카탈로그 : ETL 워크플로우를 위한 테이블 정의, 작업 정의 및 기타 제어 정보가 포함된 메타 데이터 저장소
- 크롤러 : 데이터 소스에 연결하고, 데이터 스키마를 추론하고 데이터 카탈로그에서 메타 데이터 테이블 정의를 만드는 프로그램
- ETL 작업 : 소스에서 데이터를 추출하고, Apache Spark 스크립트를 사용하여 데이터를 변환하고 타겟에 로드하는 비즈니스 로직
- 트리거 : 일정이나 이벤트를 기반으로 작업을 실행하는 메커니즘
Glue의 ETL 작업
- Crawler
- 데이터 소스에 접근
- 해당 데이터 파일의 구조를 파악
- Data Catalog에 테이블 정의서 생성
- ETL 작업(Job)
- Glue가 자동으로 Spark 기반의 Python 스크립트 생성
- 트리거
- 이 ETL 작업이 실행되는 조건을 설정할 수 있음
- 매일 9시에 실행(시간 기반), S3에 데이터 삽입 시 실행(이벤트 기반)Glue의 테이블/데이터베이스에는 실제 데이터가 없음
단지, 데이터의 메타 데이터를 생성할 뿐
실제 데이터는 외부 DB에 존재

배우는중입니다.