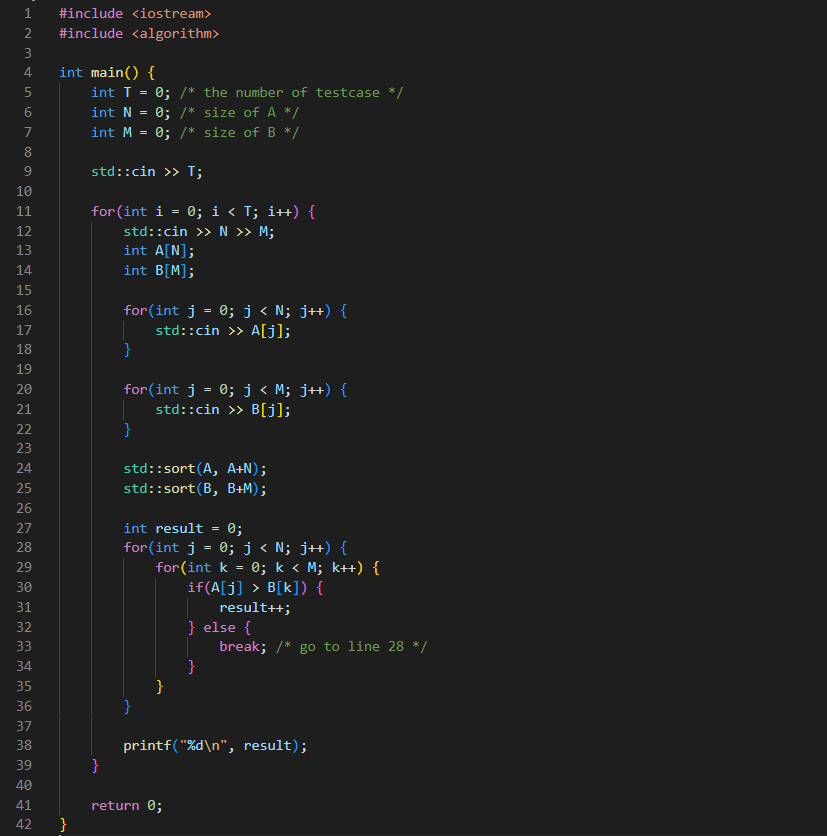
- 문제 (7795번) : 먹을 것인가 먹힐 것인가
- 두 개의 수 배열 A, B 를 입력받았을 때 [ A의 원소 > B의 원소 ] 를 만족하는 쌍의 개수 찾는 프로그램.
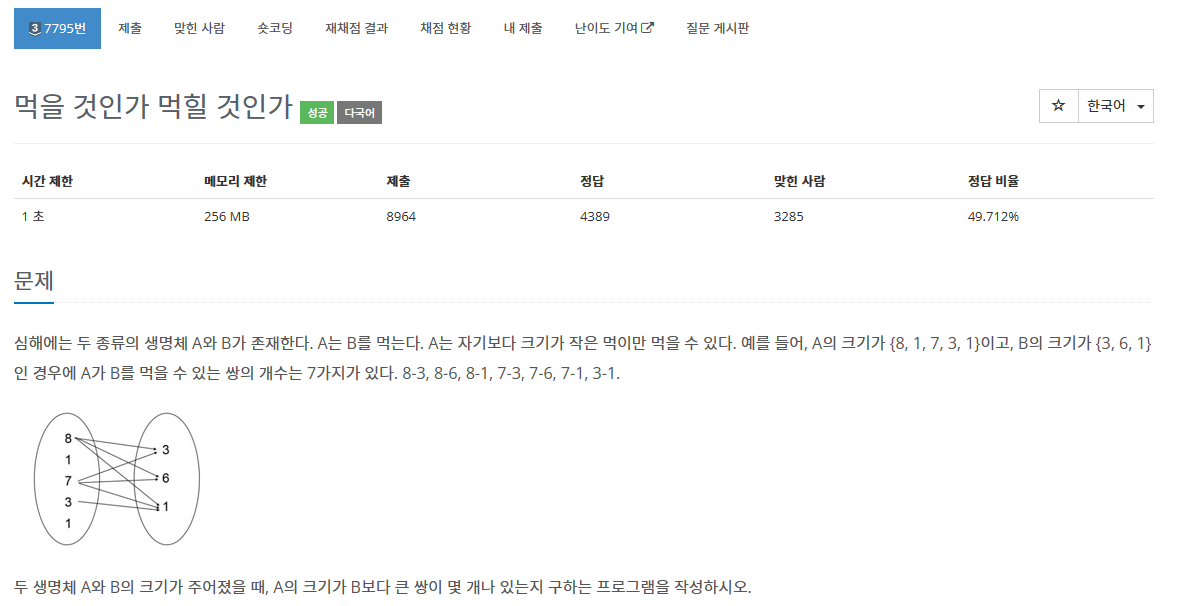
- 입력 및 출력
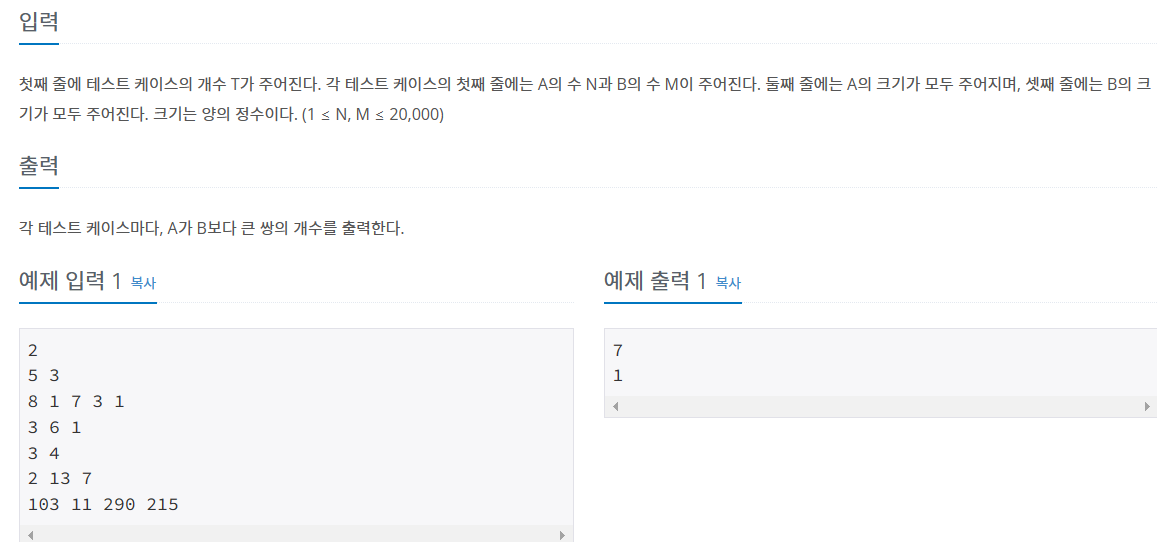
[ 입력 ]
- 첫째 줄에 testcase의 개수 T 입력
- 각 testcase의 첫째 줄에는 배열 A의 원소개수 N과 배열 B의 원소개수 M 입력
- 그 다음 줄에 배열 A의 원소 입력
- 그 다음 줄에 배열 B의 원소 입력
[ 입력 제한 ]
- 크기는 양의 정수
- 1 ≤ N , M ≤ 20,000
[ 출력 ]
- 각 testcase마다 [ A의 원소 > B의 원소 ] 를 만족하는 쌍의 개수 출력
- 문제 풀이
-
나는 이 문제를 입력받은 수열을 정렬한 후 탐색하며 [ A의 원소 > B의 원소 ] 를 만족하는 경우를 하나하나 구해주었다.
( 정렬을 하는 이유는 조건에 맞지 않으면 바로 break문으로 탈출가능하지만 정렬이 안되어있다면 배열의 모든 원소를 탐색해야한다.) -
배열 A와 B를 입력받은 후 algorithm header 에 있는 sort 함수로 두개의 배열을 정렬해주었다.
그 후 A를 기준으로 하나씩 다음으로 넘겨가며 [ A의 원소 > B의 원소 ] 인 경우를 result 변수에 하나씩 더해준다. -
A의 모든 원소를 탐색했다면 출력 후 다음 testcase로 넘어가 이와 같은 과정을 반복한다.
-
완전탐색으로 해결하게 되면 속도는 느리지만 쉽게 해결 가능하다.

-
이렇게 문제에도 적혀있듯이 이분탐색과 두 포인터로도 가능하니 한번 해보면 좋을 것 같은 문제이다. ( 완전탐색은 직관적으로 쉽게 풀 수 있음. )
-
다른 방법으로 풀면 완전 탐색으로 푼 것보다 복잡도가 좋게 나오지 않을까 예상한다. ( 아래는 완전탐색으로 푼 결과 )

- 최종 코드