들어가기 전에...
Apache Kafka는 빠르고 확장 가능한 작업을 위해 데이터 피드의 분산 스트리밍, 파이프 라이닝 및 재생을 위한 실시간 스트리밍 데이터를 처리하기 위한 목적으로 설계된 오픈 소스 분산형 게시-구독 메시징 플랫폼입니다.→ 데이터를 주고 받을 수 있는 플랫폼
왜 카프카 커넥트가 필요한가?
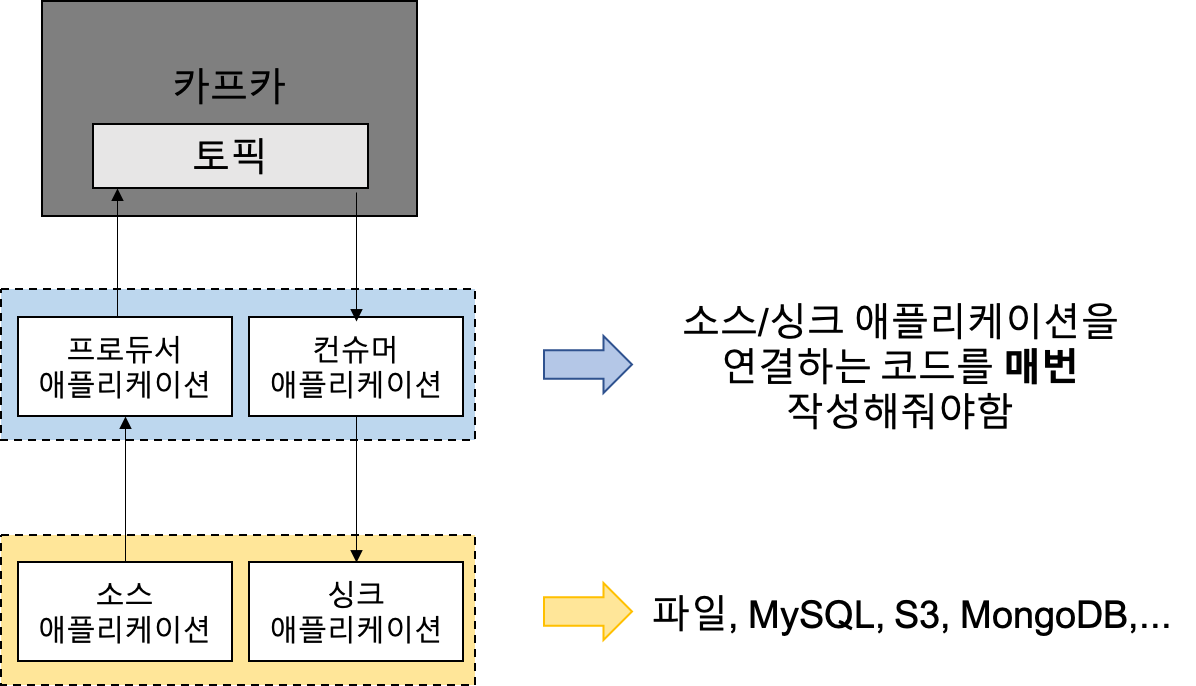
프로듀서 애플리케이션
: 소스 애플리케이션을 연동하여 Kafka의 특정 토픽에 메시지를 발행하는 애플리케이션
컨슈머 애플리케이션
: 싱크 애플리케이션을 연동하여 Kafka 토픽으로부터 데이터를 소비하여 싱크 애플리케이션이 데이터를 싱크할 수 있도록하는 애플리케이션
소스 애플리케이션
: 카프카에 보낼 데이터 소스를 제공하는 애플리케이션
싱크 애플리케이션
: 카프카에서 받은 데이터를 싱크하는 애플리케이션
→ MySQL, S3, MongoDB가 대표적인 소스/싱크 애플리케이션
Source connector
: A source connector, such as the Microsoft SQL Server Source connector, ingests entire databases and streams table updates to Kafka topics. It can also collect metrics from all of your application servers and store these in Kafka topics, making the data available for stream processing with low latency.
Sink connector
: A sink connector delivers data from Kafka topics into secondary indexes, such as Google BigQuery or batch systems like Amazon S3, for offline analysis.
(출처: https://docs.confluent.io/cloud/current/connectors/index.html#connect-to-external-systems-in-ccloud)
예시
: MySQL에서 카프카로 데이터를 보낼 때 and 카프카에서 데이터를 MySQL로 저장할 때
→ JDBC 커넥터를 사용하여 파이프라인을 생성할 수 있음
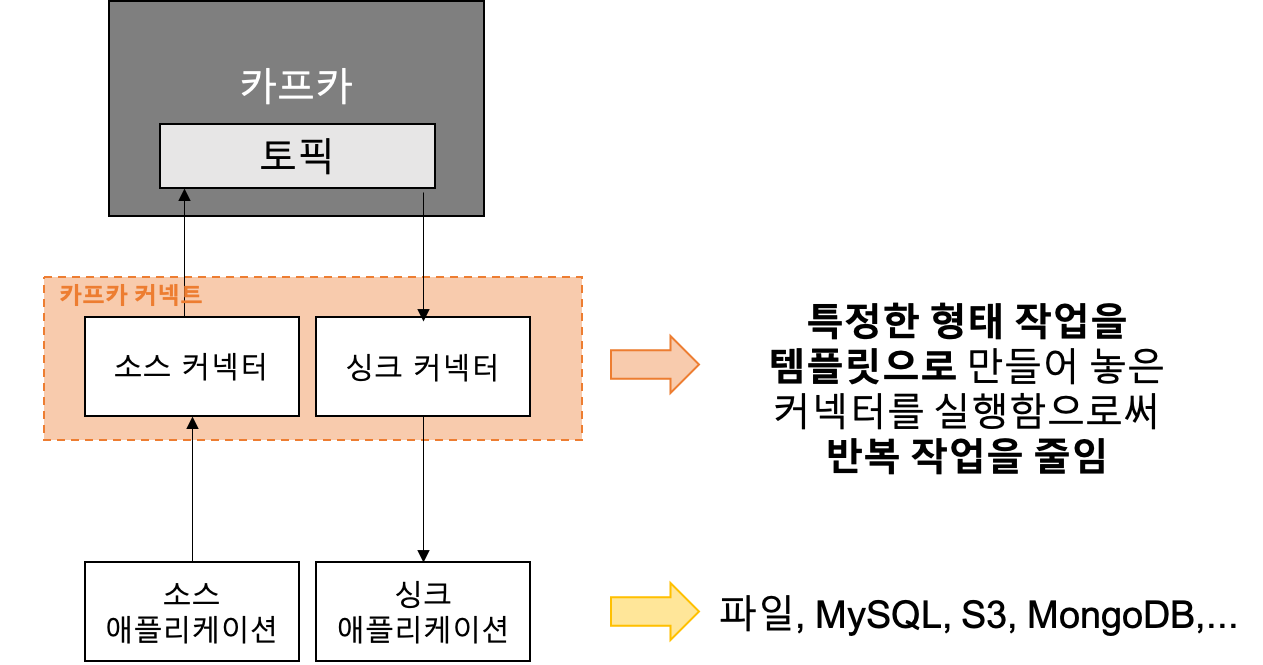
카프카 커넥트 플러그인
- 기본 플러그인
- 미러메이커2 커넥터, 싱크 커넥터, 파일 소스 커넥터 (카프카 2.6 기준)
- 오픈 소스 커넥터
- HDFS 커넥터, AWS S3 커넥터, JDBC 커넥터, 엘라스틱서치 커넥터 등
- 컨플루언트 허브에서 검색하여 사용할 수 있음
Fully-Managed Connector For Confluent Cloud (링크)
: Confluent Cloud offers pre-built, fully managed, Apache Kafka® Connectors that make it easy to instantly connect to popular data sources and sinks.
Self-Managed Connectors (링크)
: Confluent Hub client에서 설치하거나 직접 플러그인 파일을 다운로드 받아서 설치한 커넥터
카프카 커넥트 구성
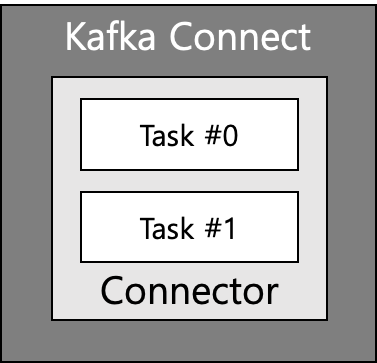
- 카프카 커넥트에 커넥터에 생성 명령을 내리면 커넥트는 내부에 커넥터와 태스크를 생성한다.
- 커넥터: 테스크를 관리
- 테스크: 커넥터에 종속되는 개념, 실질적인 데이터 처리를 함, 테스크 상태를 통해 정상적으로 데이터 처리가 이뤄졌는지 확인 가능
- 추가 옵션
- 컨버터 (converter): 데이터 처리 전 스키마 변경, JsonConverter, StringConverter, ByteArrayConverter 기본 제공, 커스텀 컨버터 지원
- 트랜스폼 (transform): 데이터 처리 시 각 메시지 단위로 간단하게 데이터 변환, Cast, Drop, ExtractField 등 기본 제공
- 예시) JsonConverter 사용할 때, 특정 키를 삭제하거나 추가할 수 있음
- https://docs.confluent.io/platform/current/connect/transforms/overview.html#single-message-transforms-for-cp
단일 모드
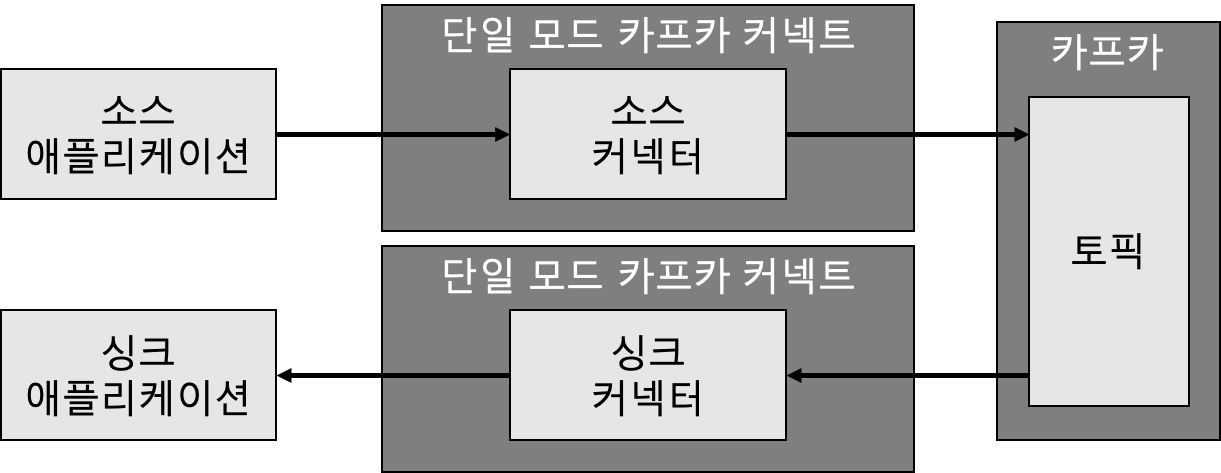
- 1개 프로세스만 실행
- 단일 장애점 (SPOF: Single Point of Failure)
- 주로 개발환경이나 중요도가 낮은 파이프라인을 운영할 때 사용
단일 모드 커넥트 설정
- connect-standalone.properties
- 단일 모드 커넥트를 참조하는 설정 파일
- https://kafka.apache.org/0102/generated/
# 카프카와 연동할 카프카 클러스터 호스트
# 2개 이상 연동할 경우 콤마(,)로 구분
bootstrap.servers=kafka:9092
# 데이터를 카프카에 저장하고 카프카에서 가져올 때 데이터를 변환하는데 사용
# JsonConverter, StringConverter, ByteArrayConverter 기본 제공
# 사용하지 않으려면 false로 설정
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
# 로컬 파일에 오프셋 저장
# 소스/싱크 커넥터가 데이터 처리 시점을 저장하기 위해 사용
# 예시) 파일 소스 커넥터: 특정 파일을 읽어 토픽에 저장할 때, 몇 번째 줄까지 읽었는지 저장
# 저장할 경로 및 처리 완료한 테스크의 오프셋 커밋 주기
# 데이터 처리하는데 중요한 정보임으로 접근에 유의
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
# 커넥터의 디렉터리 주소
# 여러개의 경우 콤마(,)로 구분
# 컨버터(converter)와 트랜스폼(transform)도 프러그인으로 추가 가능
plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins단일 모드 커넥트 실행하기
단일 모드 커넥트는 커넥트 설정 파일과 함께 커넥터 설정 파일을 정의하여 실행하여야 함
- 파일 소스 커넥터 설정 파일
# 커넥터 이름, 커넥트에서 유일해야 함
name=local-file-source
# 커넥터 클래스 명, 카프카 기본 제공 클래스인 FileStreamSource로 지정
connector.class=FileStreamSource
# 테스크 수, 다수의 파일을 읽어 토픽에 저장하고 싶으면 테스크 수를 늘려 병렬 처리하면 됨
tasks.max=1
# 읽을 파일 위치
file=test.txt
# 데이터를 저장할 토픽 이름
topic=connect-test- 단일 모드 커넥트 실행
$ ./bin/connect-standalone.sh ./config/connect-standalone.properties ./config/connect-file-source.properties분산모드 커넥트
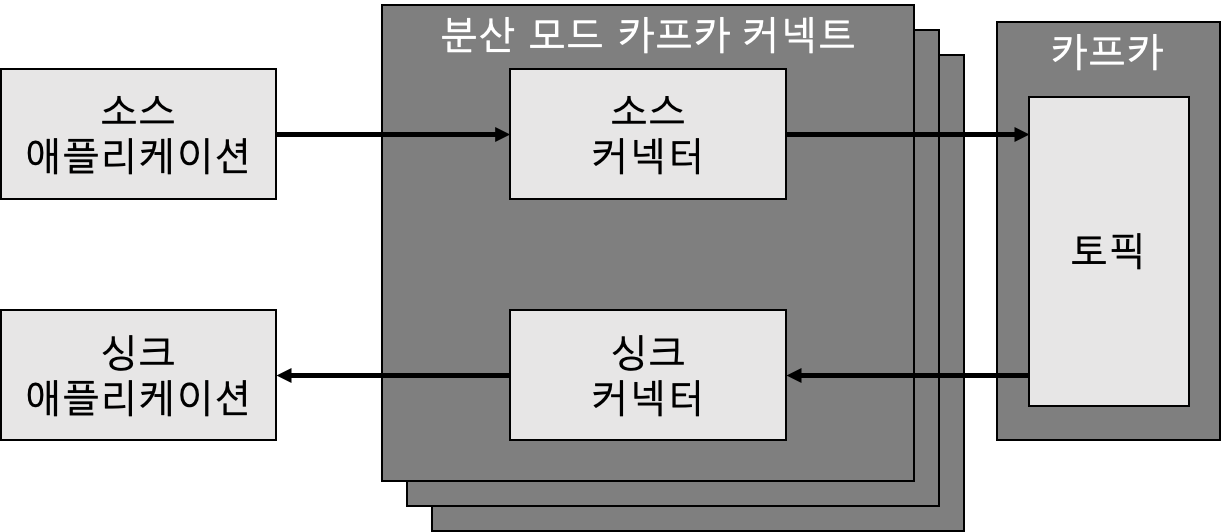
- 2대 이상의 서버에서 클러스터 형태로 운영
- 단일 모드 커넥트 대비 안전하게 운영할 수 있음
- 커넥트 이슈 발생 시에도 다른 커넥트가 지속적으로 처리할 수 있음
- 처리량의 변화에도 유연하게 대응
- 상용환경을 커넥트를 운영할 때 권장
분산 모드 커넥트 설정
- connect-distributed.properties
bootstrap.servers=kafka:9092
# 다수의 커넥트 프로세스들을 묶을 그룹 이름
# 같은 그룹으로 지정된 커넥트들에서 커넥터가 실행되면 커넥트들에 분산되어 실행됨
# 커넥트 중 한 대에서 이슈가 발생해도 다른 커넥트에서 커넥터가 안전하게 실행됨
group.id=connect-cluster
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
# 분산 모드 커넥트는 오프셋 정보를 내부 토픽(internal topic)에 저장
# 내부 토픽: https://docs.confluent.io/platform/current/streams/developer-guide/manage-topics.html#internal-topics
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1
config.storage.topic=connect-configs
config.storage.replication.factor=1
status.storage.topic=connect-status
status.storage.replication.factor=1
offset.flush.interval.ms=10000
plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins분산 모드 커넥트 실행
분산 모드 커넥트는 커넥트 설정 파일만 있으면 됨
커넥터는 커넥트가 실행된 후 REST API를 통해 생행/중단/변경 할 수 있음
- 실행
$ ./bin/connect-distributed.sh ./config/connect-distributed.properties- (상용) 2대 이상의 분리된 서버마다 1개의 분산모드 커넥트를 실행하는 것을 권장
- REST API 제공 (포트: 8083)
// 사용가능한 플러그인 리스트 조회
$ curl -X GET localhost:8083/connector-plugins
[{"class":"io.debezium.connector.db2.Db2Connector","type":"source","version":"1.8.1.Final"},{"class":"io.debezium.connector.mongodb.MongoDbConnector","type":"source","version":"1.8.1.Final"},...{"class":"org.apache.kafka.connect.mirror.MirrorSourceConnector","type":"source","version":"1"}]
// 파일 소스 커넥터 생성
$ curl -X POST -H "Content-Type: application/json" --data '{"name": "local-file-source", "config": {"connector.class":"FileStreamSourceConnector", "tasks.max":"1", "file":"/tmp/test.txt", "topic":"connect-test" }}' http://localhost:8083/connectors
{"name":"local-file-source","config":{"connector.class":"FileStreamSourceConnector","tasks.max":"1","file":"/tmp/test.txt","topic":"connect-test","name":"local-file-source"},"tasks":[],"type":"source"}
// 파일 소스 커넥터 실행 확인
$ curl -X GET localhost:8083/connectors/local-file-source/status
{"name":"local-file-source","connector":{"state":"RUNNING","worker_id":"172.22.0.4:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"172.22.0.4:8083"}],"type":"source"}
// 실행 중인 커넥터 (active connector) 리스트 확인
$ curl -X GET localhost:8083/connectors
["local-file-source","course-outbox-connector","user-outbox-connector","local-file-sink"]
//실행 중인 커넥터 (active connector) 리스트 삭제
$ curl -X DELETE localhost:8083/connectors/local-file-source
$ curl -X GET localhost:8083/connectors
["course-outbox-connector","user-outbox-connector","local-file-sink"]커스텀 소스 커넥터 만들기
구현
| 파일 | 설명 |
|---|---|
| SingleFileSourceConnector.java | 태스크를 실행하기 전 설정파일을 초기화하고 어떤 태스크 클래스를 사용할 것인지 정의 |
| SingleFileSourceTask.java | 실제 데이터를 처리하는 로직 |
| SingleFileSourceConnectorConfig.java | 커넥터 실행 시 받을 설정 값들을 정의 |
커넥터 추가
- gradle jar 명령으로 jar 생성
- 참조했던 디펜던시를 같이 빌드해야함 → 같이 빌드 안하면 커넥터 실행 시 참조하는 클래스를 찾기 못하고 ClassNotFoundException 발생
- 커넥트 플러그인 디렉토리에 넣음
- 넣은 후 커넥트 재시작해야 함 → 커넥트 실행 시 플러그인을 추가하기 때문
- SingleFileSourceConnector가 추가된 것을 확인할 수 있음
- ./config/connect-distributed.properties에서 plugin.path 지정
plugin.path=/usr/local/share/kafka/plugins- jar 넣음
root@711c0d21f307:/usr/local/share/kafka/plugins# pwd /usr/local/share/kafka/plugins root@711c0d21f307:/usr/local/share/kafka/plugins# ls CustomSourceConnector-0.0.1-SNAPSHOT.jar- 커넥트 재시작
root@711c0d21f307:/opt/kafka# ./bin/connect-distributed.sh ./config/connect-> distributed.properties- 커넥터 플러그인 리스트 확인 (SingleFileSourceConnector가 추가됨)
root@711c0d21f307:/usr/local/share/kafka/plugins# curl localhost:8083/connector-plugins/ [{"class":"com.example.SingleFileSourceConnector","type":"source","version":"1.0"},{"class":"org.apache.kafka.connect.file.FileStreamSinkConnector","type":"sink","version":"2.8.1"},{"class":"org.apache.kafka.connect.file.FileStreamSourceConnector","type":"source","version":"2.8.1"},{"class":"org.apache.kafka.connect.mirror.MirrorCheckpointConnector","type":"source","version":"1"},{"class":"org.apache.kafka.connect.mirror.MirrorHeartbeatConnector","type":"source","version":"1"},{"class":"org.apache.kafka.connect.mirror.MirrorSourceConnector","type":"source","version":"1"}]- 커넥터 생성
root@711c0d21f307:~# curl -X POST -H "Content-Type: application/json" --data '{"name": "custom-file-source", "config": {"connector.class": "com.example.SingleFileSourceConnector", "task.max": "1"}}' localhost:8083/connectors {"name":"custom-file-source","config":{"connector.class":"com.example.SingleFileSourceConnector","task.max":"1","name":"custom-file-source"},"tasks":[],"type":"source"} root@711c0d21f307:~# curl -X GET localhost:8083/connectors ["custom-file-source"]- 소스 파일 생성 - /tmp/kafka.txt
hi bye hello jimin- 토픽 메시지 확인
root@711c0d21f307:/opt/kafka/bin# ./kafka-console-consumer.sh --topic test --from-beginning --bootstrap-server localhost:9092 {"schema":{"type":"string","optional":false},"payload":"hi"} {"schema":{"type":"string","optional":false},"payload":"bye"} {"schema":{"type":"string","optional":false},"payload":"hello"} {"schema":{"type":"string","optional":false},"payload":"jimin"}
커스텀 싱크 커넥터 만들기
구현
| 파일 | 설명 |
|---|---|
| SingleFileSinkConnector.java | 태스크를 실행하기 전 설정파일을 초기화하고 어떤 태스크 클래스를 사용할 것인지 정의 |
| SingleFileSinkTask.java | 실제 데이터를 처리하는 로직 |
| SingleFileSinkConnectorConfig.java | 커넥터 실행 시 받을 설정 값들을 정의 |
커넥터 추가
- gradle jar 명령으로 jar 생성
- 참조했던 디펜던시를 같이 빌드해야함 → 같이 빌드 안하면 커넥터 실행 시 참조하는 클래스를 찾기 못하고 ClassNotFoundException 발생
- 커넥트 플러그인 디렉토리에 넣음
- 넣은 후 커넥트 재시작해야 함 → 커넥트 실행 시 플러그인을 추가하기 때문
추가 읽을 거리
