
1. DVC란?
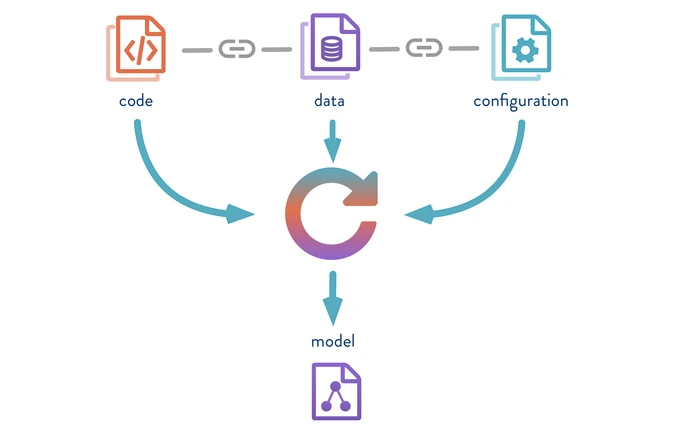
DVC는 Data Version Control 의 약자로, 머신러닝 프로젝트에서 모델과 데이터의 버전 관리를 위한 오픈 소스입니다. 머신러닝 파이프라인에서 데이터나 데이터 처리 방식, 모델 등이 바뀌는 일이 빈번하게 발생하는데, 이 과정에서 모델에 문제가 발생하게 되면 이전 버전의 모델을 가져와야 합니다. 이러한 작업을 효율적으로 할 수 있도록 버전 관리를 도와주는 도구가 DVC입니다.
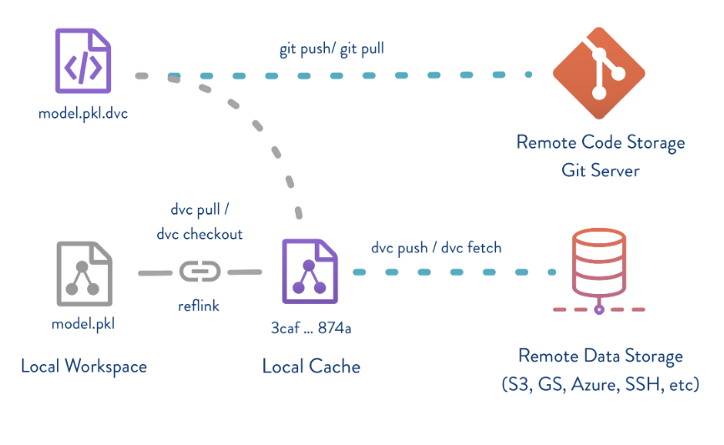
DVC 자체만으로 데이터의 버전 관리를 할 수 있는 것은 아닙니다. DVC는 데이터를 추적하는 데에 사용할 메타 데이터와 설정 파일을 생성하고, DVC에 의해 생성된 파일을 git이 추적하여 버전 관리를 진행합니다.
2. 설치 방법
brew 명령어를 통해 간단하게 설치할 수 있습니다.
$ brew install dvc설치에는 약 10분 내외의 시간이 소요됩니다. tracking을 위해서는 git이 추가적으로 설치되어있어야 합니다.
3. 기능
1) Data & Model Versioning
DVC에서는 모델 학습에 활용할 수 있는 다양한 데이터셋을 제공하는 repository가 있습니다. 본 실습에서는 해당 repository에서 데이터를 사용하도록 하겠습니다.
https://github.com/iterative/dataset-registry
DVC를 통해 데이터의 버전을 추적하기 위해서는 git 명령과 병행하여 사용하여야 합니다.
tracking하기 위한 데이터셋을 저장할 폴더를 생성하고, 해당 폴더 내부에서 git init 명령과 dvc init 명령을 실행합니다.

이제 DVC를 통해 관리할 예제 데이터셋을 가져오겠습니다.
$ dvc get [https://github.com/iterative/dataset-registry](https://github.com/iterative/dataset-registry) get-started/data.xml -o data/data.xml데이터를 가져왔다면, dvc add 명령을 통해 변경 내용을 추가합니다.
$ dvc add data/data.xml
git을 통해 해당 파일에 대한 변화를 추적하기 위해서는, 아래의 명령어를 추가적으로 입력합니다.
$ git add data/.gitignore data/data.xml.dvc
$ git commit -m "message"
dvc add 명령을 수행하면 .gitignore 파일과 .dvc 파일이 생성됩니다. .gitignore 파일을 통해 원본 파일을 버전 관리에서 제외시킵니다.

원본 데이터의 크기는 매우 클 수 있기 때문에 별도의 저장소를 통해 관리하고, 해당 데이터의 정보가 담긴 .dvc 파일을 관리하는 것이 dvc 기반 버전 관리의 핵심입니다.

.dvc 파일의 sub level에서 정의되는 field의 종류는 다음과 같습니다.
| Field | Description |
|---|---|
| path | 파일 / 디렉토리의 경로 |
| md5 | DVC 기반 tracking을 위한 해쉬값 |
| size | 파일 / 디렉토리의 용량 |
2) Storing and Sharing
DVC를 통해 관리되는 데이터나 모델을 dvc push 명령을 통해 원격 저장소에 안전하게 저장할 수 있습니다. DVC는 Amazon S3, Google Drive, Azure Blob Storage, HDFS와 같은 다양한 종류의 원격 저장소를 지원합니다.
- Google Drive
Google Drive에 데이터를 저장할 폴더를 생성하고, URL에서 /drive/folders/ 뒷부분의 문자열을 복사합니다.
$ dvc remote add -d <storage name> gdrive://<string>
원격 저장소가 연결이 된 것을 확인하실 수 있습니다. 저장소의 변경 사항은 .dvc/config 에 적용되므로 git commit 명령을 통해 변경 사항을 최신화합니다.

dvc push 명령을 통해 원격 저장소에 저장할 파일 및 폴더를 업로드합니다.
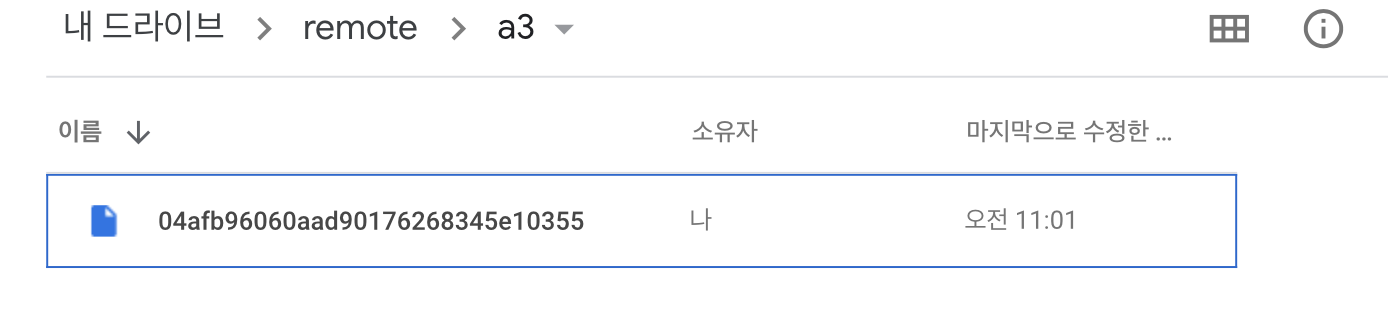
해당 파일이 원격 저장소에 정상적으로 업로드된 것을 확인할 수 있습니다.
- Amazon S3
먼저, AWS S3에 접속하여 버킷을 생성합니다.
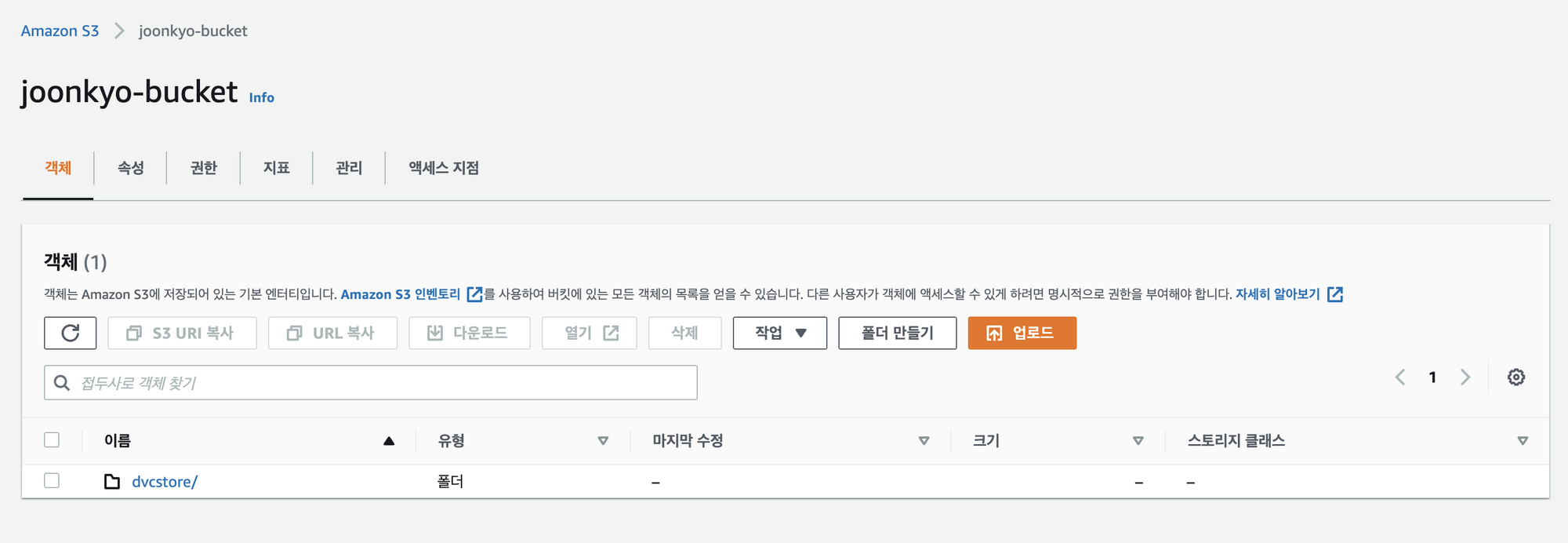
보안 자격 증명 탭에 들어갑니다.
액세스 키 탭에서 액세스 키가 존재하지 않다면 발급받습니다.
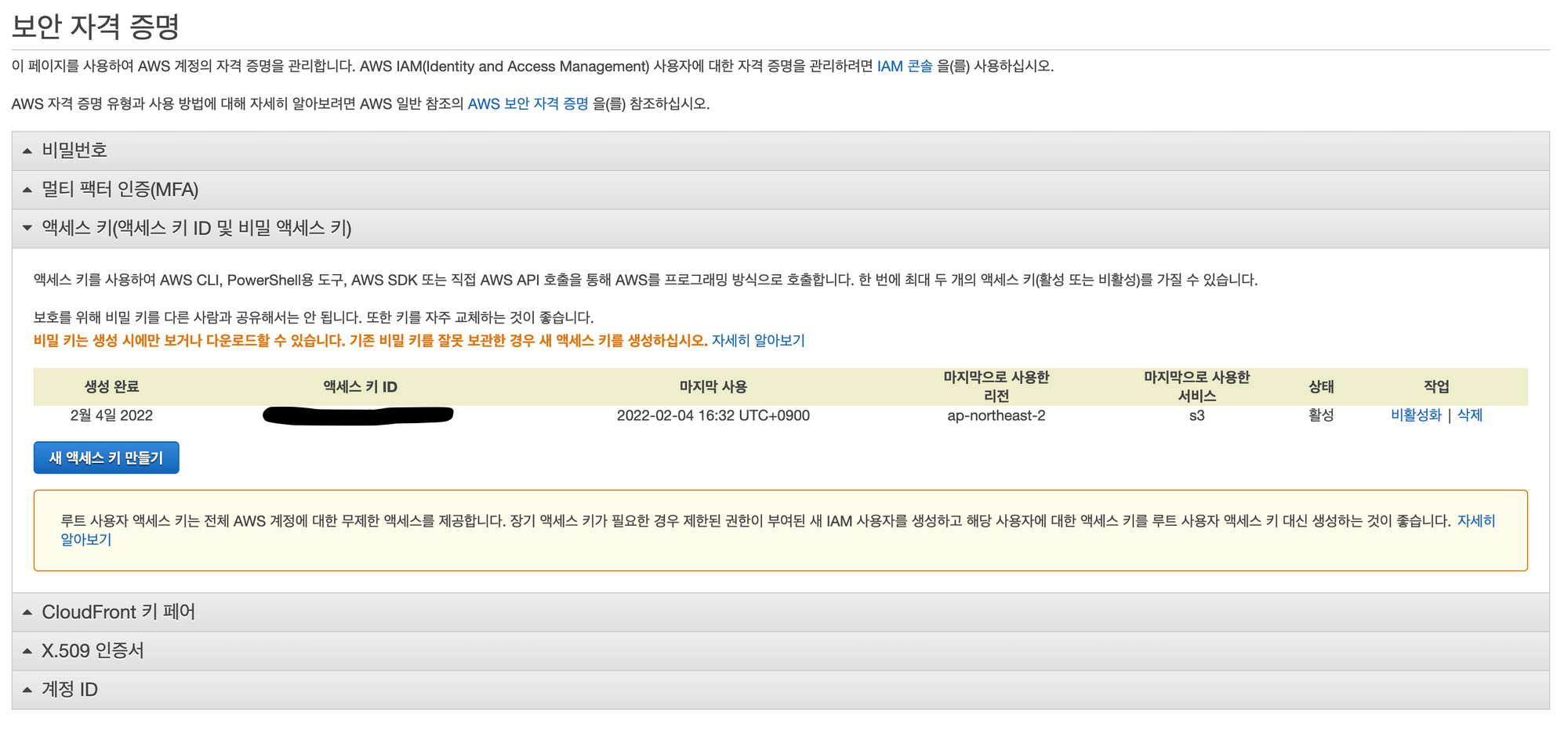
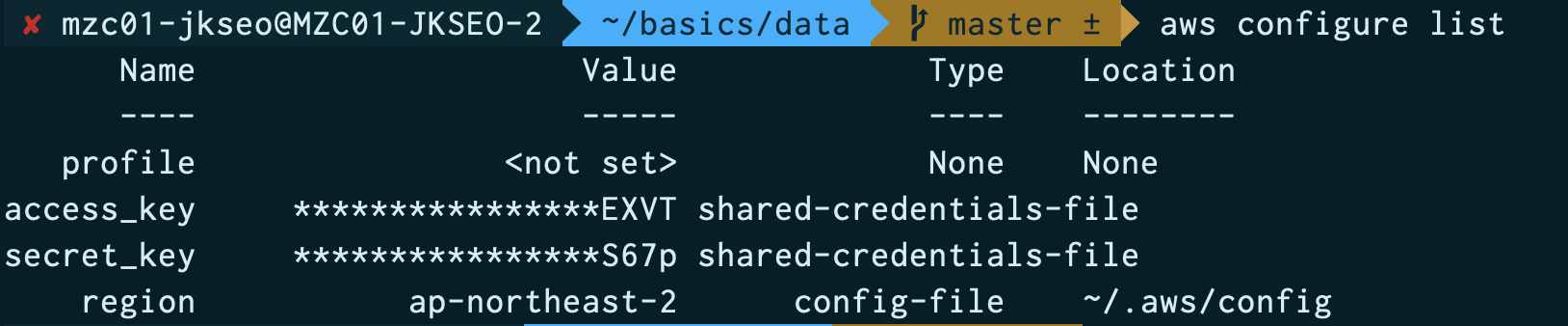
AWS CLI를 통해 방금 발급받은 access key와 secret key를 입력합니다.
$ aws configureconfiguration이 정상적으로 입력되었는지 확인합니다.
s3 버킷의 경로를 원격 저장소로 설정하고, ./dvc/config 변경 사항을 git에 추가한 후 commit합니다.
$ dvc remote add -d storage s3://joonkyo-bucket/dvcstore
$ git add .dvc/config
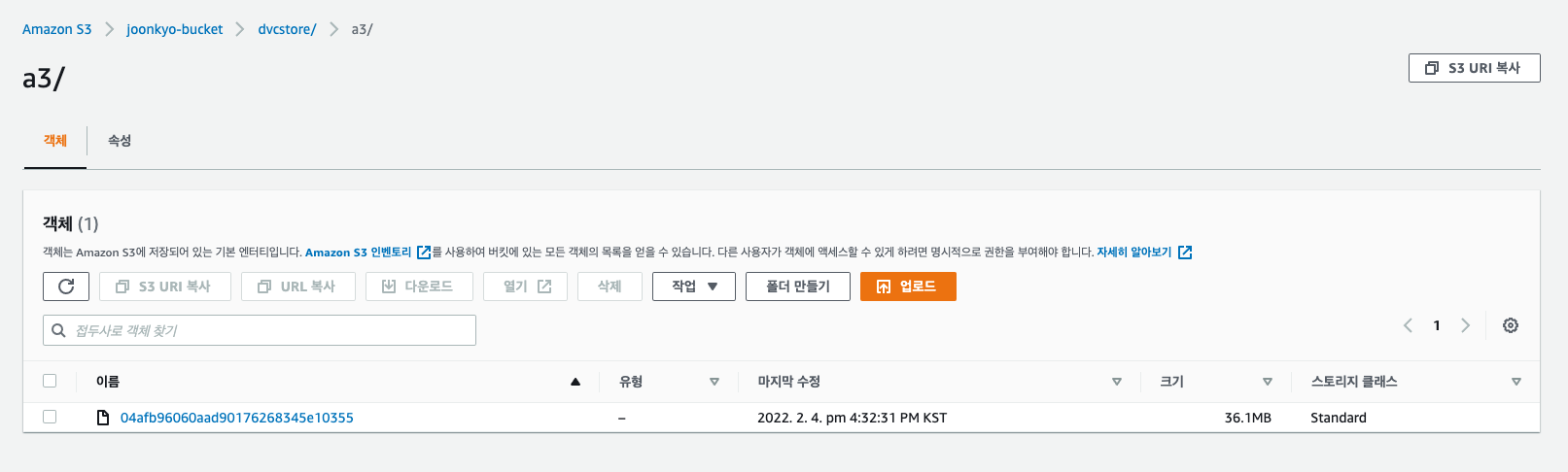
$ git commit -m "Configure remote storage" dvc push 를 통해 해당 저장소에 데이터를 push합니다.
s3 버킷을 확인하면 데이터가 정상적으로 push된 것을 확인할 수 있습니다.
3) Making changes
데이터에 대한 변경 사항이 발생했을 경우, 다음 과정을 통해 데이터의 버전을 업데이트할 수 있습니다.
$ dvc add data/data.xml
$ git commit data/data.xml.dvc -m "Dataset updates"
$ dvc push4) Switching between version
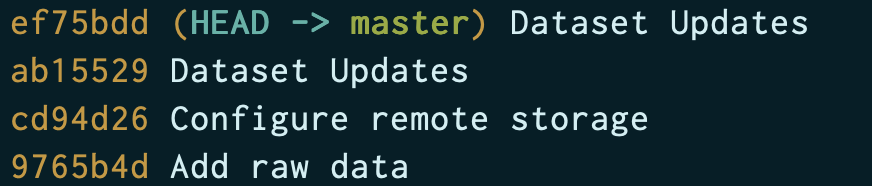
데이터를 변경한 이력이 있는 경우, 변경 이전의 데이터를 다시 불러올 수 있습니다. 다음 명령어를 통해 commit 내역을 조회합니다.
$ git log --onelinelog는 commit hash와 commit message로 이루어져 있으며, 다음 명령을 통해 과거의 데이터로 변경할 수 있습니다.
$ git checkout HEAD^<num> data/data.xml.dvc ## 첫번째 방법
$ git checkout <commit hash> ## 두번째 방법
$ dvc checkout git checkout 을 통해 .dvc 파일을 tracking하면서 특정 버전의 과거 데이터를 다시 가져올 수 있습니다.
5) Data & Model Access
- Python API
import dvc.api
with dvc.api.open(
'get-started/data.xml', ## 데이터 경로
repo='https://github.com/iterative/dataset-registry' ## github repo 경로
) as fd:
data = fd.read()
print(data)dvc 모듈 기반의 python API를 통해 file descriptor 형태로 데이터를 가져올 수 있습니다.
- Command
$ dvc get 4. 실습 예제
실습을 위해 git clone 명령을 통해 원격 저장소를 복제해옵니다.
$ git clone https://github.com/iterative/example-versioning.git
$ cd example-versioning$ python3 -m venv .env ## 가상환경 구축
$ source .env/bin/activate
$ pip install -r requirements.txt
## 데이터셋 다운로드
$ dvc get https://github.com/iterative/dataset-registry tutorials/versioning/data.zip
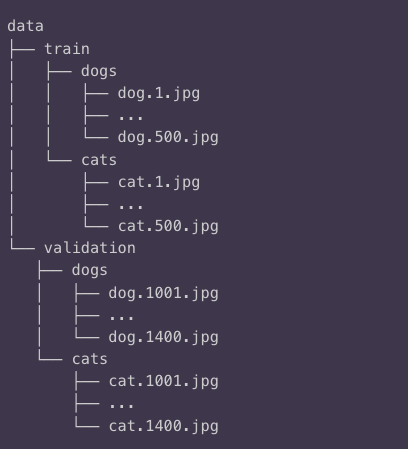
데이터는 다음과 같이 개와 고양이 사진에 대한 train, validation data로 구성되어 있습니다.
dvc add 명령을 통해 버전 관리할 데이터를 지정합니다.
$ dvc add data해당 데이터로 모델 학습을 진행합니다. train.py 에는 모델의 loss 변화를 기록한 metrics.csv, model의 weight를 저장하는 .h5 파일을 추출하는 기능이 추가되어 있습니다. metrics.csv 파일 내용은 아래와 같습니다.
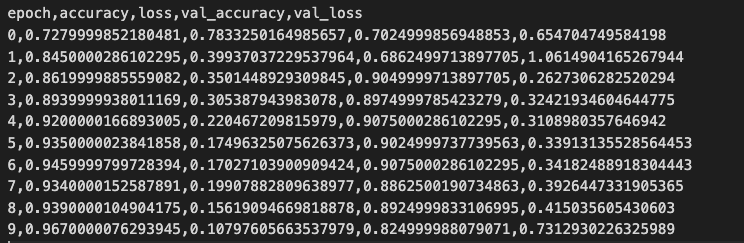
스크립트를 통해 모델을 학습시킵니다.
$ python train.py추출된 model.h5 을 버전 관리에 추가합니다.
$ dvc add model.h5git add 를 통해 .dvc 파일을 tracking합니다.
$ git add data.dvc model.h5.dvc metrics.csv .gitignoregit commit 을 진행한 뒤, git tag 를 통해 특정 커밋을 버전으로 저장하여 효율적으로 버전 관리를 할 수 있습니다.
$ git commit -m "First model, trained with 1000 images"
$ git tag -a "v1.0" -m "model v1.0, 1000 images"$ git show v1.0
#git tag push
git push --tagsgit show <version> 명령을 실행하면 특정 버전에 대한 태그 정보와 커밋에 관한 정보를 한눈에 확인할 수 있습니다.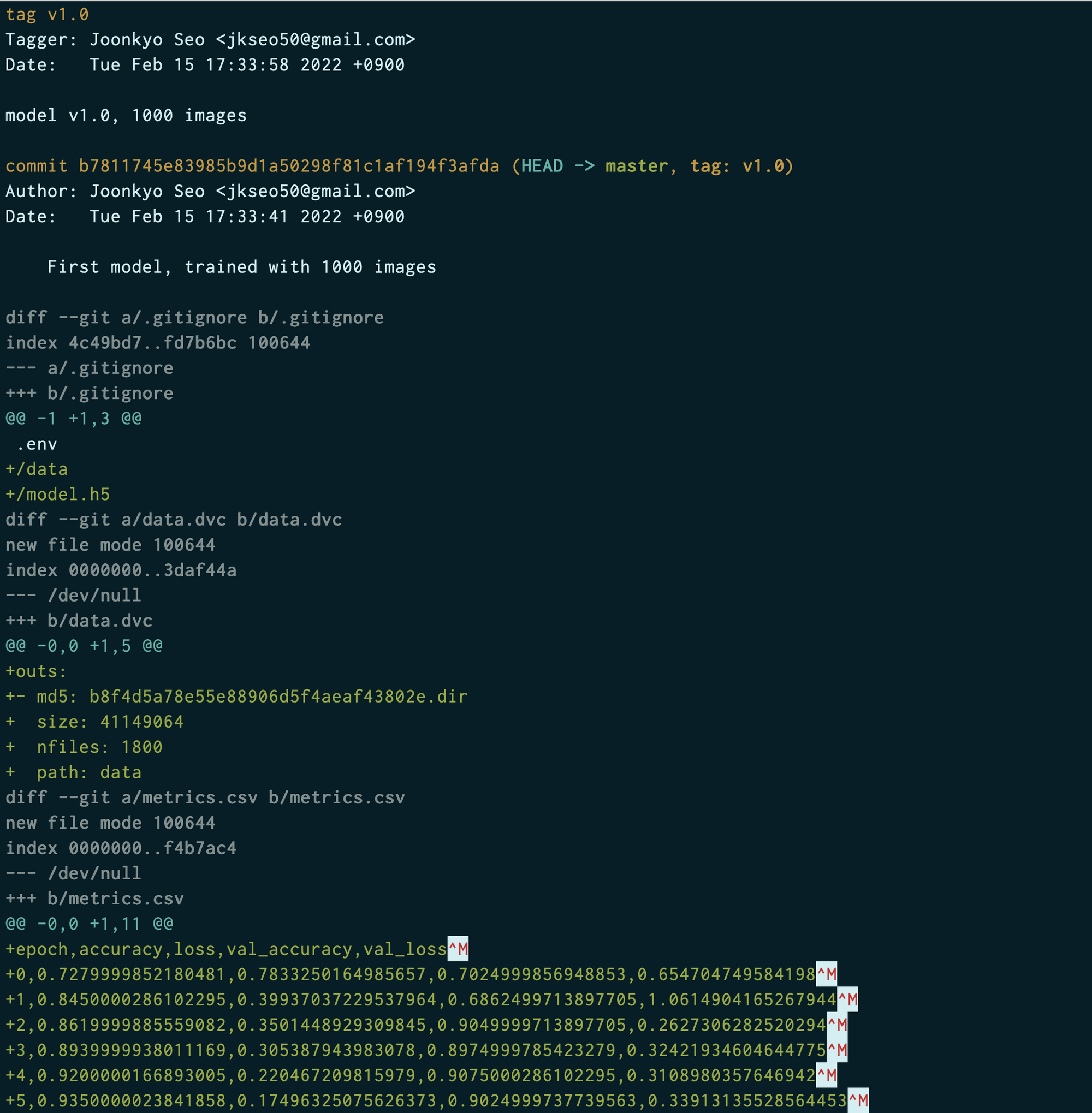
이제, 두번째 학습을 진행하기 위해 새로운 데이터셋을 다시 받아옵니다.
$ dvc get https://github.com/iterative/dataset-registry tutorials/versioning/new-labels.zip
$ unzip -q new-labels.zip
$ rm -f new-labels.zip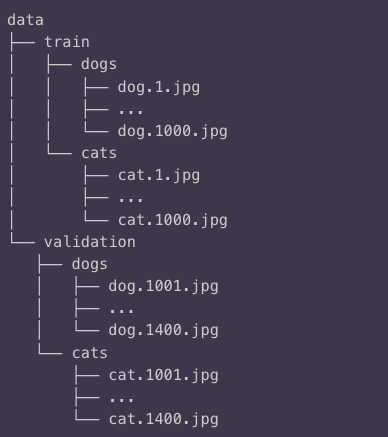
6 directories, 2800 files
이전과 마찬가지로 새로 생성된 데이터를 dvc add 로 추가하고 학습을 진행한 뒤, 생성된 weight 파일도 같이 추가합니다.
$ dvc add data
$ python train.py
$ dvc add model.h5두번째 학습에 대한 데이터, weight 파일의 버전을 지정합니다.
$ git add data.dvc model.h5.dvc metrics.csv
$ git commit -m "Second model, trained with 2000 images"
$ git tag -a "v2.0" -m "model v2.0, 2000 images"git show v2.0 으로 버전 내용을 확인합니다.
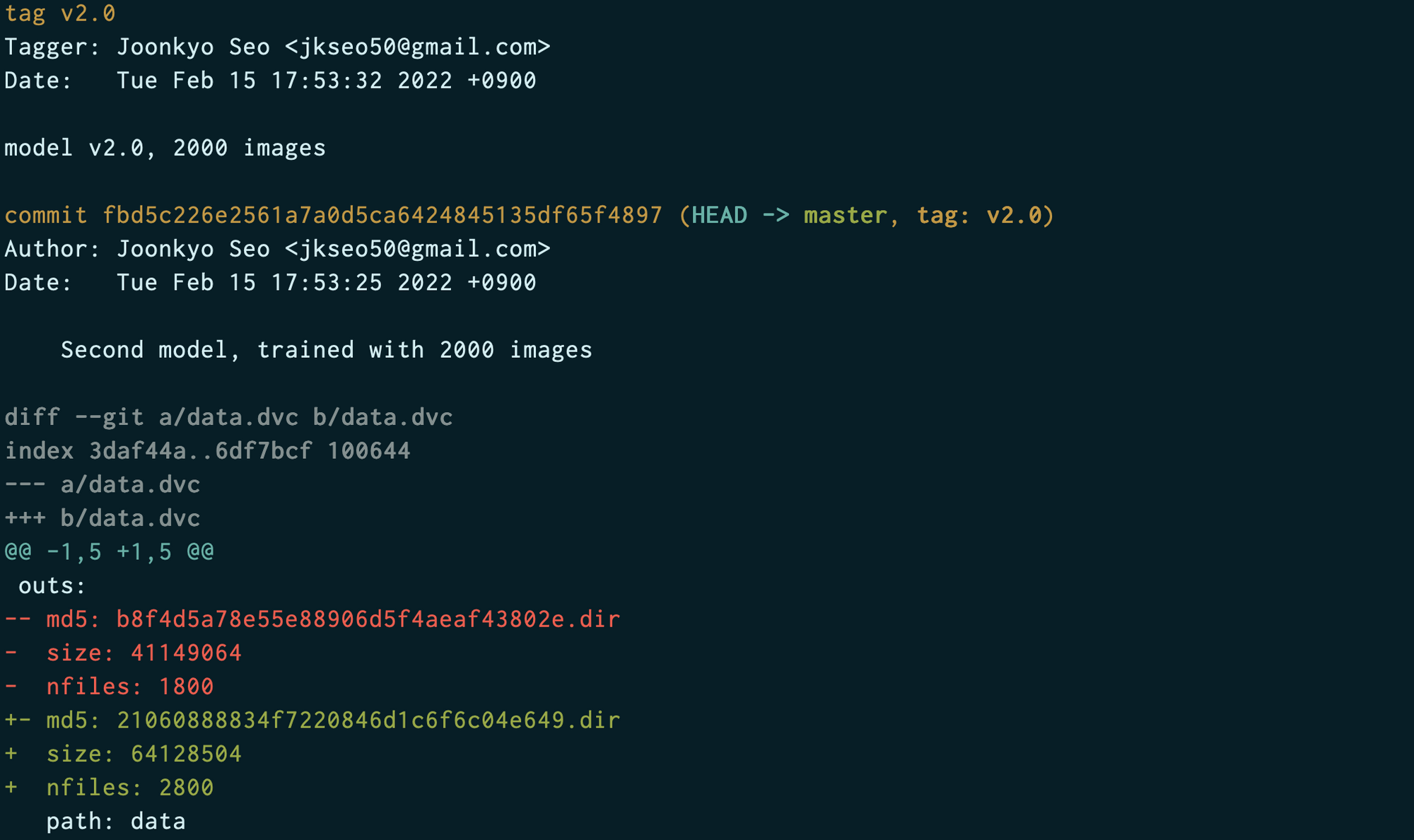
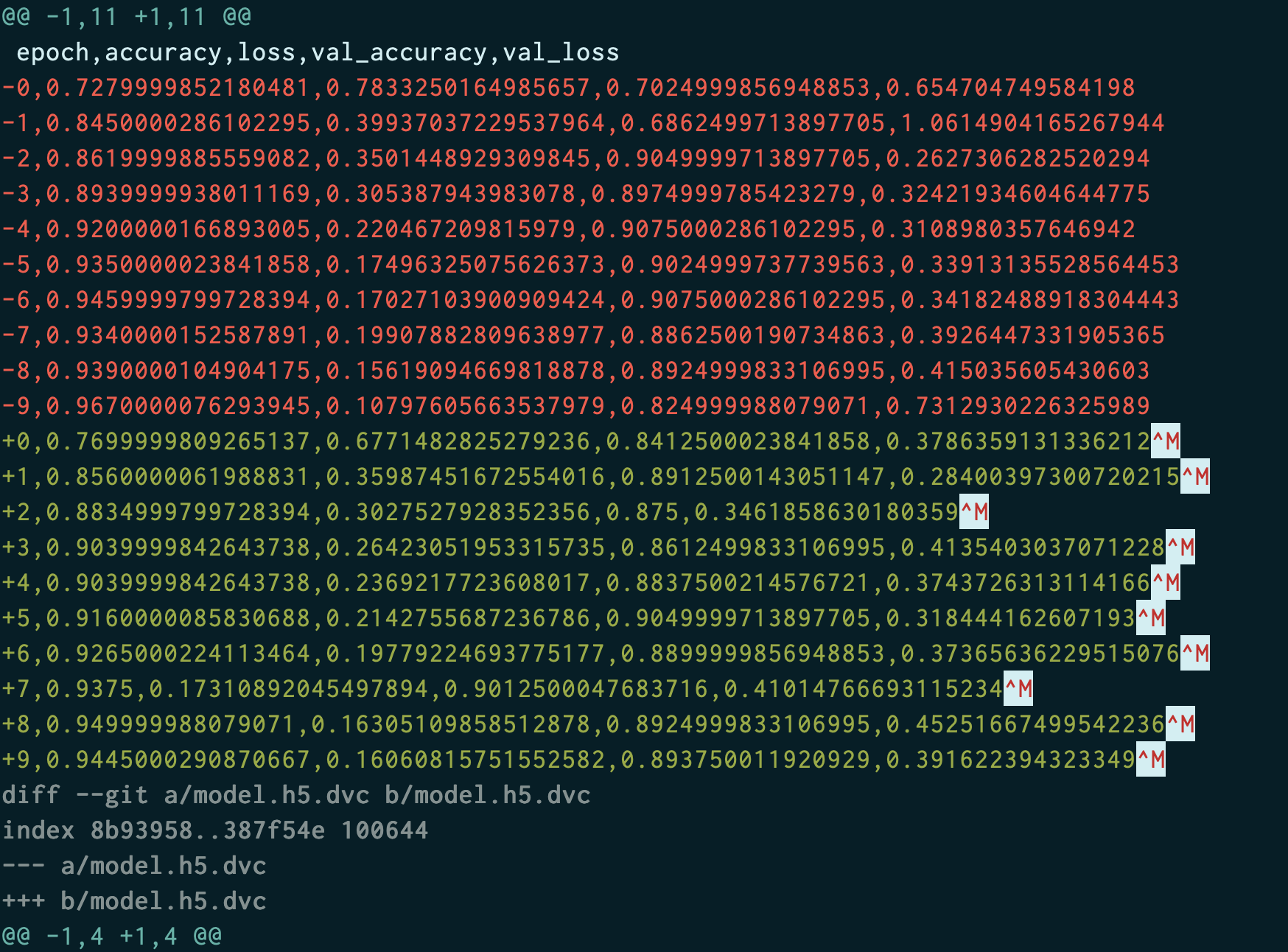
metrics.csv 파일에 대한 변경사항을 추가적으로 확인할 수 있습니다.
또한, git checkout , dvc checkout 명령을 통해 과거의 특정 버전으로 돌아갈 수 있습니다.
$ git checkout v1.0
$ dvc checkout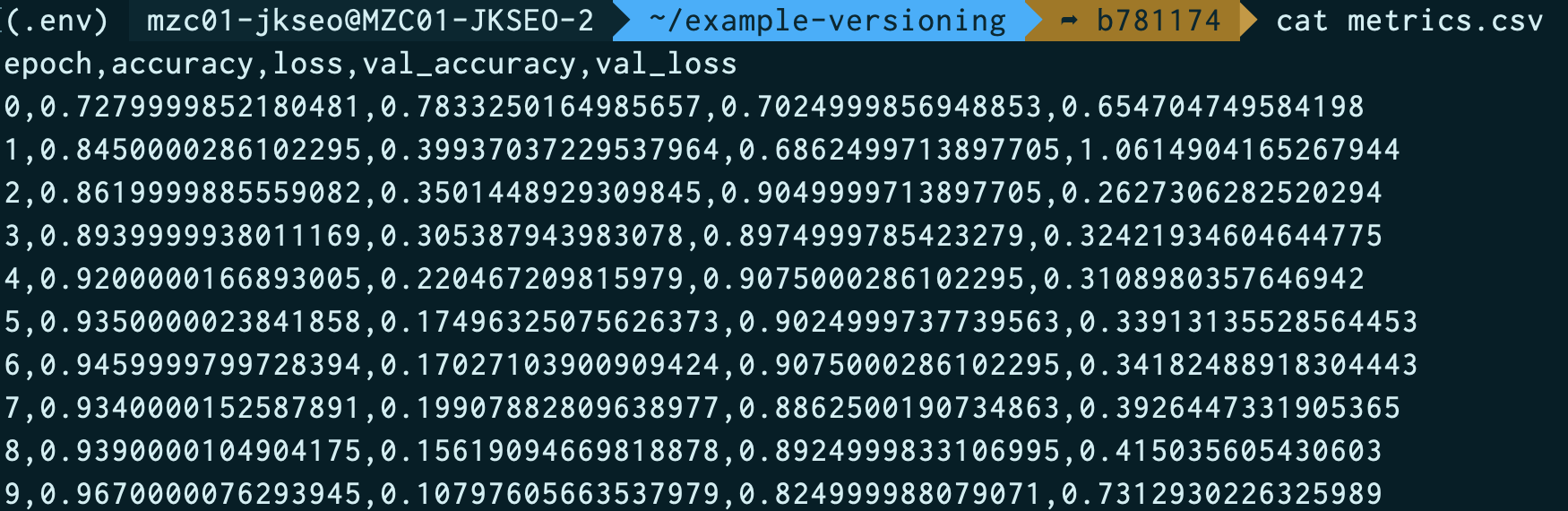 위와 같이 v1.0의
위와 같이 v1.0의 metrics.csv가 복원된 것을 확인할 수 있습니다.
