머신러닝 데이터 전처리에 활용할 수 있는 메타데이터 테이블 만들기 기술
column별 역할, 속성, 사용유무, 데이터타입을 표로 나타냄
데이터 핸들링, 전처리, 시각화에 활용
해당 기술 출처 - Kaggle - 운전자 보험 예측 금메달 EDA 커널
원본데이터는 모두 숫자로 이루어짐
컬럼명에 카테고리, binary등으로 속성이 표시되어있음
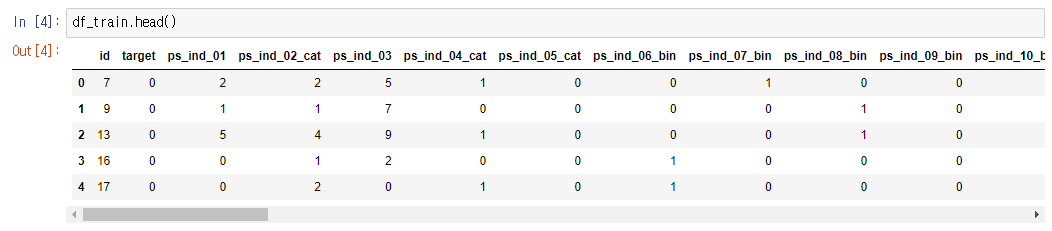
Python 코드
data = []
# 데이터 별 역할 지정
for f in df_train.columns:
if f == 'target':
role = 'target'
elif f == 'id':
role = 'id'
else:
role = 'input'
# 데이터 속성 지정
if 'bin' in f or f == 'target':
level = 'binary'
elif 'cat' in f or f == 'id':
level = 'nominal' # 명목 변수
elif df_train[f].dtype == float:
level = 'interval' # 간격 변수
elif df_train[f].dtype == 'int64':
level = 'ordinal' # 순서 변수
# True : 사용하는 변수
# False : 사용하지 않는 변수
keep = True
if f == 'id':
keep = False
dtype = df_train[f].dtype
f_dict = {
'varname':f,
'role':role,
'level':level,
'keep':keep,
'dtype':dtype
}
data.append(f_dict)
meta = pd.DataFrame(data, columns = ["varname","role","level","keep","dtype"])
meta.set_index("varname", inplace = True)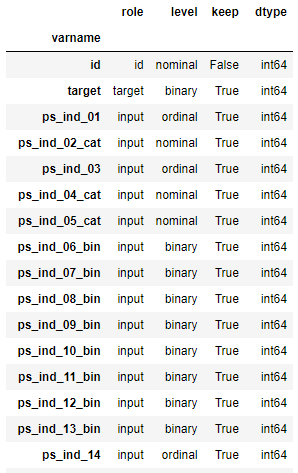
활용 예시
Interval = meta[(meta["level"] == "interval") & (meta["keep"])].index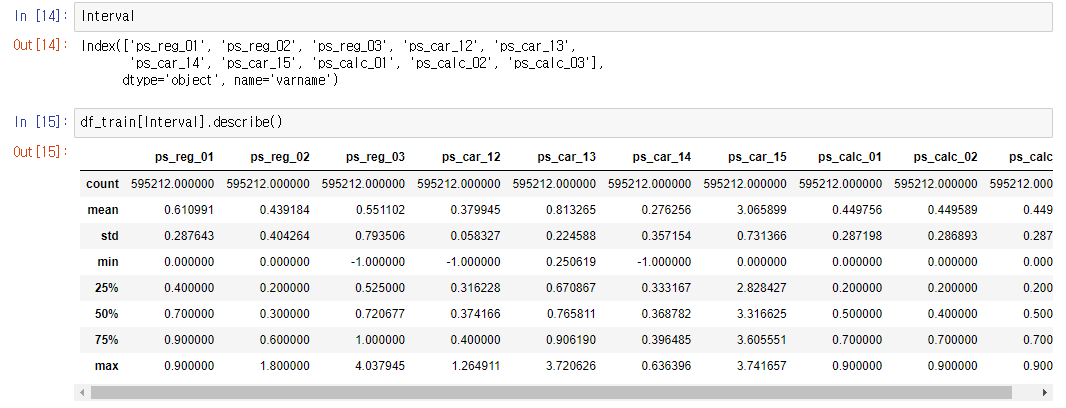
구분한 데이터 특성 별로 describe를 수행 -> 이상치, 결측치, 평균 등의 값을 파악하는데 용이하다.
