10일차는
리눅스에서 파일과 문자열을 다루는 명령어들을 학습하였다.
1. cat
2. cut
3. paste
4. grep
5. sort
6. sed
7. awk
1. cat
- 명령어 + 파일명을 적으면 내용이 출력되는 명령어
참고
| (파이프라인) : 왼쪽의 명령어를 이어서 오른쪽 명령어로 작업 (선행프로세스의 output을 후행프로세스의 input으로 사용)
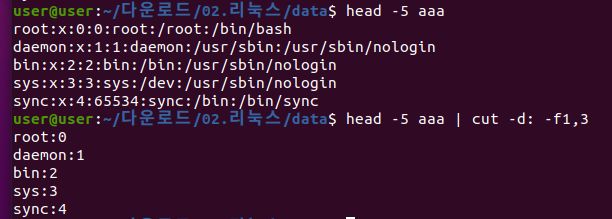
2. cut
- file 이나 표준 입력으로 받은 문자열을 잘라서 새로운 문자열을 만드는 명령어
- 장점 : 속도가 빠름. 버퍼를 거치지 않고 그냥 출력
다음 두개의 명령어에 대한 출력 차이가 없다. (원본 순서)
- cut -d “ ” -f1,3 data.txt
- cut -d “ ” -f3,1 data.txt
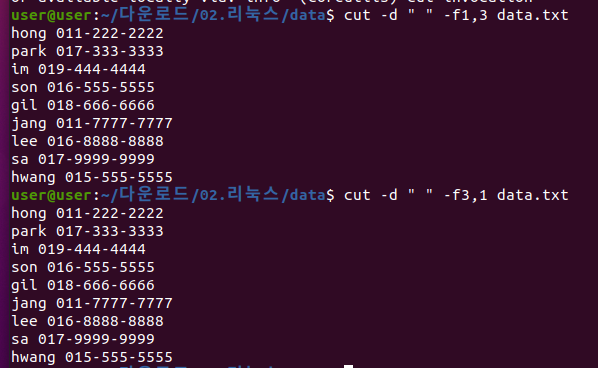
- 단점 : 필드를 구분하는 공백이 일정하지 않을 때는 사용하기 힘들다.(첫 필드를 잘라내는 것에는 좋음)
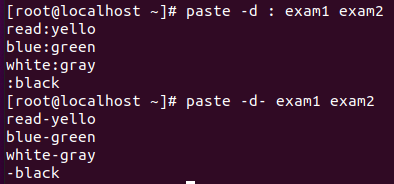
3. paste
- 텍스트 파일을 수평적으로 join, merge 하는 명령어
옵션
- -d : 구분자 지정
- -s : 수직으로 값을 읽어 수평으로 출력
- paste-cut 활용 예제

4. grep
- 파일 내 특정 문자열을 찾는 명령어
- grep 명령어 자체가 파일을 열 수 있음 (예 - grep 011 data.txt)
옵션
- -i : 대소문자를 구분하지 않고 검색
- -l : 해당 패턴이 포함된 파일을 찾을 때 사용 (아래 예제의 2>는 리눅스 리다이렉션을 참고)
- -c : 일치하는 행의 수를 출력
- -v : 제외하고 출력
- grep+cut+정규표현식 활용 예제



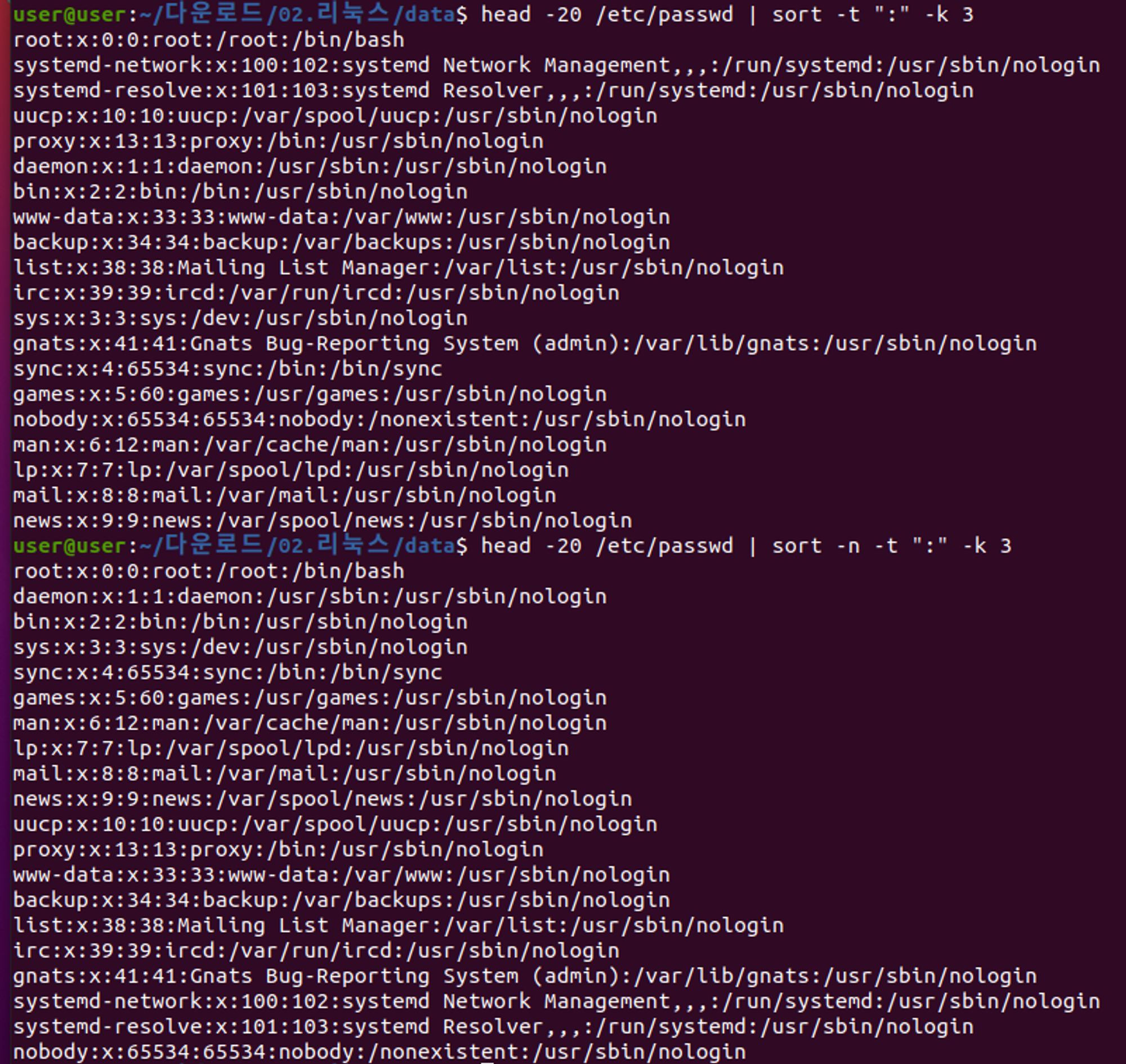
5. sort
- 문자열을 정렬하는 명령어
- sort는 공백을 무시하는 기능이 있다.
옵션
- -r : 내림차순 (기본은 오름차순)
- -t : 필드 구분자
- -k : 몇번째 필드를 지정할지 선택
- -n : 숫자로 sort할 때 이 옵션 적용. 숫자를 숫자로 인식(기본은 문자열로 인식)
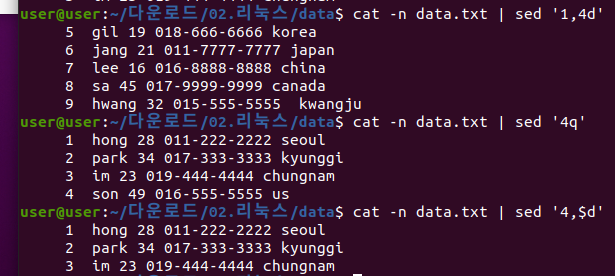
6. sed
- 문자열을 치환하거나 삭제할 때 사용하는 명령어(stream editor)
- sed는 원본을 건드리지 않음
- 기본 문법 : sed '주소범위'
옵션
- p : 출력
- d : 앞에 명시된 범위를 제거하고 출력
- q : 앞에 명시된 범위까지 출력
- ,(콤마) : 주소 범위를 지정
- /단어/ : 단어 포함 여부
- /^단어/ : 단어로 시작하는 행
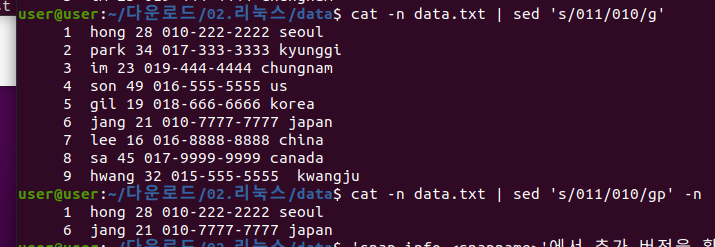
- 's/단어1/단어2/g' : 단어1을 단어2로 치환하는 명령어
- -n : sed로 작업한 부분만 출력
- -e : sed를 여러개 나열 가능
- -f : e대신 한번에 여러 옵션을 적용 할 수 있음.

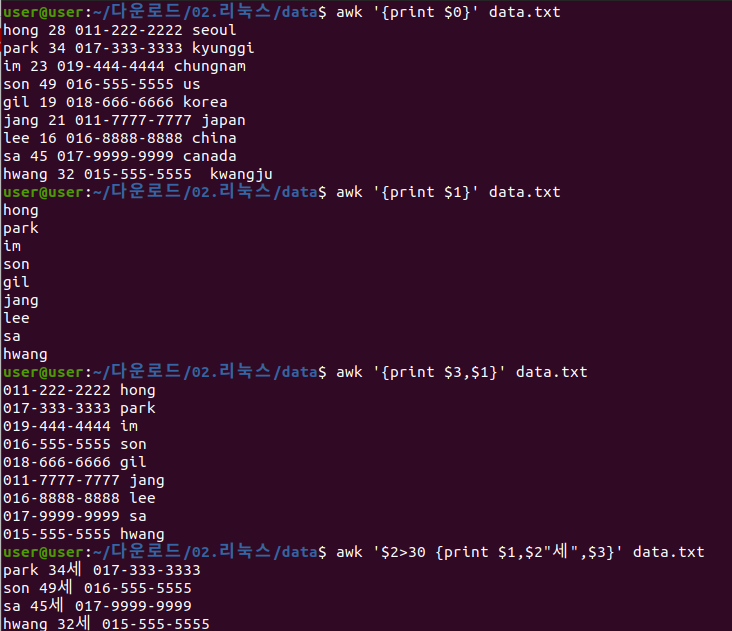
7. awk
- 특정 패턴으로 필드를 조작하고 검색
예시
- awk '{print $0}' data.txt > 전체 열
- awk '{print $1}' data.txt > 첫번째 열 …
- awk '{print $3,$1}' data.txt > 세번째, 첫번째 열… 여러개 순서 정해서
- awk '$2 > 30 {print $1,$2"세",$3}' data.txt > 나이(2번째 열)이 30보다 크고 ‘세’라는 단위를 추가하여 출력
실습
- uid가 1000이상인 계정 중에서 로그인 권한이 있는 계정을 필터링 (끝에 bash가 포함되어있는 것)

(참고) 명령어에 명령어 넣기 : 백틱(`) 사용 또는 괄호 앞에 $ 표기

