https://towardsdatascience.com/tabnet-e1b979907694
를 읽고 흥미로워서 번역한 글입니다.
XGBoost와 같은 gradient boosting model은 테이블 데이터에서 큰 성능을 보이고 있다. 그러나 2019년 구글의 TabNet은 이러한 트리기반 모델의 성능을 능가하고 있다. 특히 피쳐 전처리를 할 필요가 전혀 없고 built-in 설명가능성이 있다는 점에서 매우 흥미롭다.
TabNet 이란?
Overview
- 원본 테이블데이터를 인풋으로 하고, 어떠한 전처리를 하지 않아도 된다. gradient descent 기반 최적화를 통해 학습한다
- sequential attention을 사용해서 각 decision step마다 어떤 피쳐를 선택할지 고르게 된다. 이를 통해 interpretability 와 더 좋은 학습을 할 수 있다. learning capaity를 가장 유의미한 피쳐에 쏟아붓기 때문. (learning capacity는 학습 리소스로 이해했다)
- 피쳐 셀렉션은 instance-wise하다. -> 학습데이터의 각 행이 다를 수 있다는 말이다.
- 피쳐 셀렉션과 추론에서 하나의 딥러닝 아키텍처를 사용한다 => soft feature selection이라 한다
- 위의 구조를 통해 두가지 interpretability(해석능력)을 가지게 된다
- local interpretability: 피쳐 중요도를 시각화할 수 있고 하나의 행에서 그들이 어떻게 combine되어있는 지를 알 수 있다
- glocal interpretability: 각 피쳐가 학습된 모델에 얼마만큼 contribution(영향도/기여도 정도로 받아들이면 될것같음)을 가지고 있는 지 알 수 있다
key points
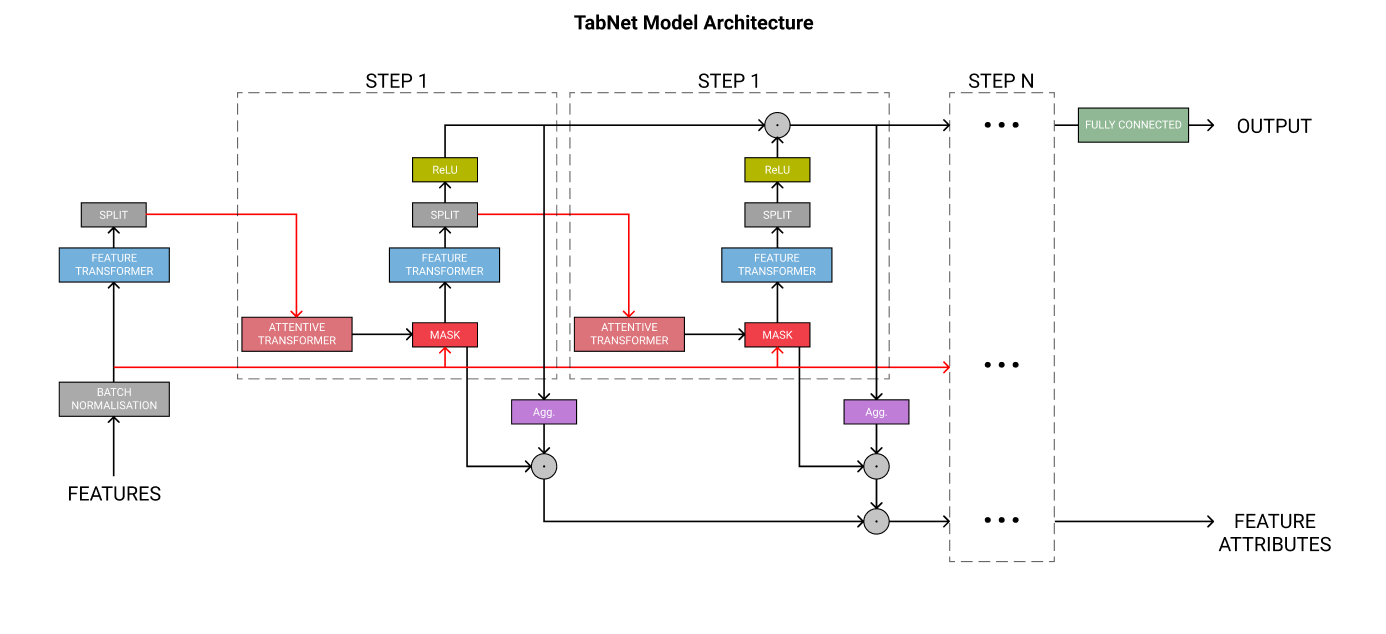
기본 구조
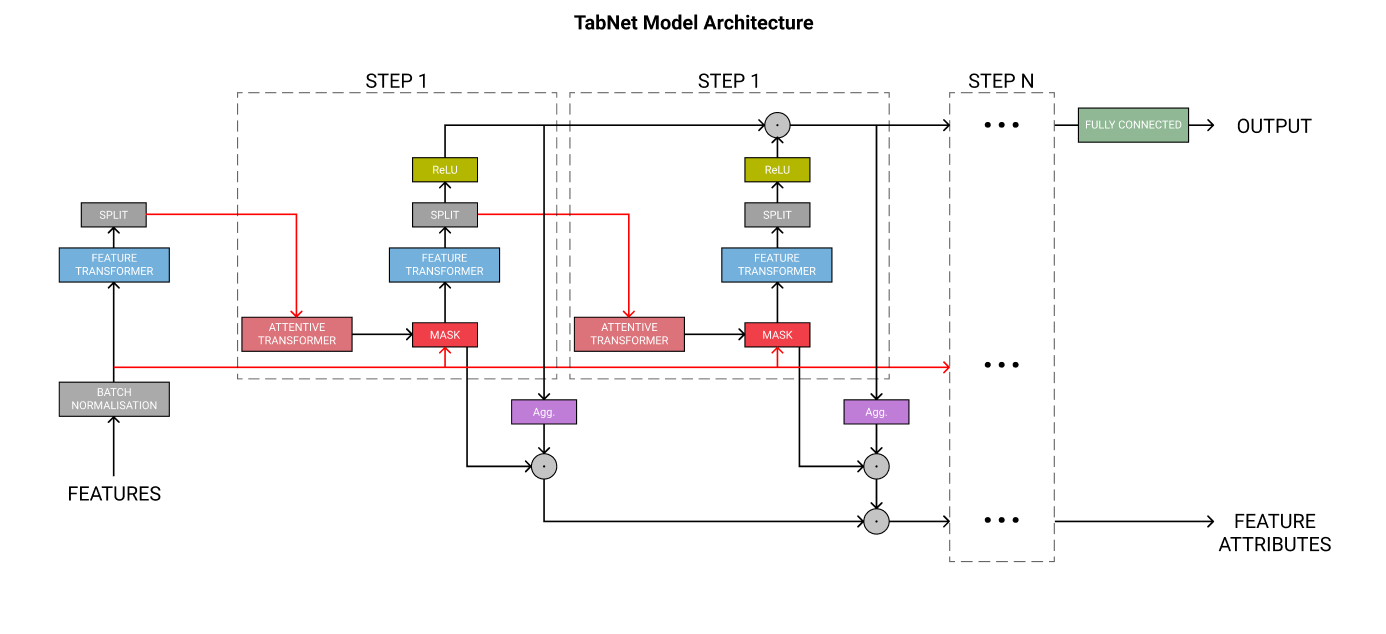
steps
-
각 스텝은 구성요소의 블록이다.
-
스텝의 수는 하이퍼파라미터이다.
- 각 스텝수를 늘리면 모델의 learning capacity를 늘릴 수 있다
- 그러나 학습시간과 메모리 사용량도 늘어나고, 오버피팅 위험도 있다.
-
각각의 스텝은 마지막 classification 단계에서 자신의 투표권(vote)가 있고, 이 vote들은 같은 가중치를 가진다(equally weighted)
- 앙상블 분류와 비슷한 논리
Feature Transformer
- 여러개의 레이어가 있고, 이 레이어중 몇개는 모든 스텝에 대해 공유되고, 몇개는 각 스텝에 대해서 유니크하다.
- 각 레이어는 FC-layer, Batch Normalization, Gated Linear Unit activation를 가지고 있다.
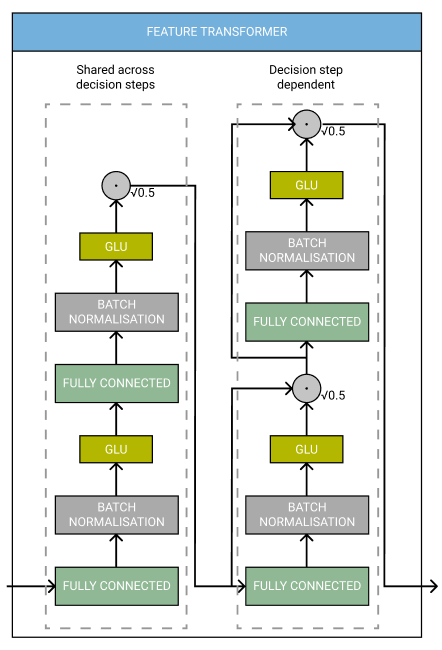
- TabNet의 저자는, decision step마다 몇개의 레이어를 공유하는 것은 “parameter-efficient and robust learning with high capacity” 을 얻을 수 있다고 한다.
- 그리고 루트0.5로 normalize하는 것은 “분산이 크게 변하지 않기 때문에, 학습을 안정화시키게 된다.”
- feature transformer의 아웃풋은 ReLU를 사용한다.
Feature Selection
-
일단 피쳐가 transform되면, 그 후에는 Attentive Transformer와 mask를 통과시킨다
-
Attentive transformer는 FC-layer, batch normalization, sparsemax normalization으로 이루어져있다.
-
또한 prior scale를 포함한다 -> 이전의 스텝에서 각 피쳐를 얼마나 사용했는지를 알 수 있다.
- 이전의 feature transformer의 processed feature를 사용해서 mask를 도출한다
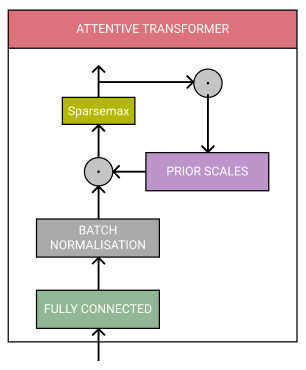
- 이전의 feature transformer의 processed feature를 사용해서 mask를 도출한다
-
mask는 모델이 가장 중요한 피쳐에만 집중할 수 있게 한다. 그리고 를 통해 explainability(설명력)을 도출할 수 있다.
-
mask는 일단 피쳐를 가리게 되는데, 이는 attentive transformer에서 중요하다고 판단했던 피쳐에 대해서만 모델이 사용하게 한다는 것을 의미한다.
-
모든 decision스텝과 각 prediction에서 해당 피쳐가 얼마나 마스팅되었는지 살펴봄으로써 feature importance에 대해 해석할 수 있다
-
TabNet employs soft feature selection with controllable sparsity in end-to-end learning
- 하나의 모델이 결합되어서 feature selection과 아웃풋 매핑을 수행한다는 것을 의미한다. (end-to-end니까)
-
TabNet uses instance-wise feature selection, which means features are selected for each input and each prediction can use different features.
- Instance-wise feature selection은 각 인풋에서 피쳐가 선택되고, 각 예측에서 다른 피쳐를 사용할 수 있다는 것을 의미한다.
-
이러한 피쳐 셀렉션은 decision boundary를 각 피쳐의 linear combination으로 일반화할 수 있게 한다.
- linear combination: a1x1+a2x2+ ... 이렇게 선형결합된 상태를 생각하면 된다.
- 각각의 피쳐의 기여도를 계수가 결정하게 되어서, 모델의 interpretability를 높이게 되는 것이다.
Example Tutorial
Explainability
TabNet의 가장 큰 장점은 explainable하다는 것이다. SHAP이나 LIME없이는 gradient boosting을 해석할 수 없다. 마스킹 덕분에 피쳐에 대한 해석을 global(전체 데이터셋에 대해서) / local(각각의 예측에 대해서) 하게 할 수 있다.
개별 피쳐에 대한 중요도를 살펴보자.
트리 기반 모델을 썼을 경우에는, 하나의 변수나, 엄청나게 많은 unique 값이 있는 categorical 변수에 대해서 skew될 수 있다.
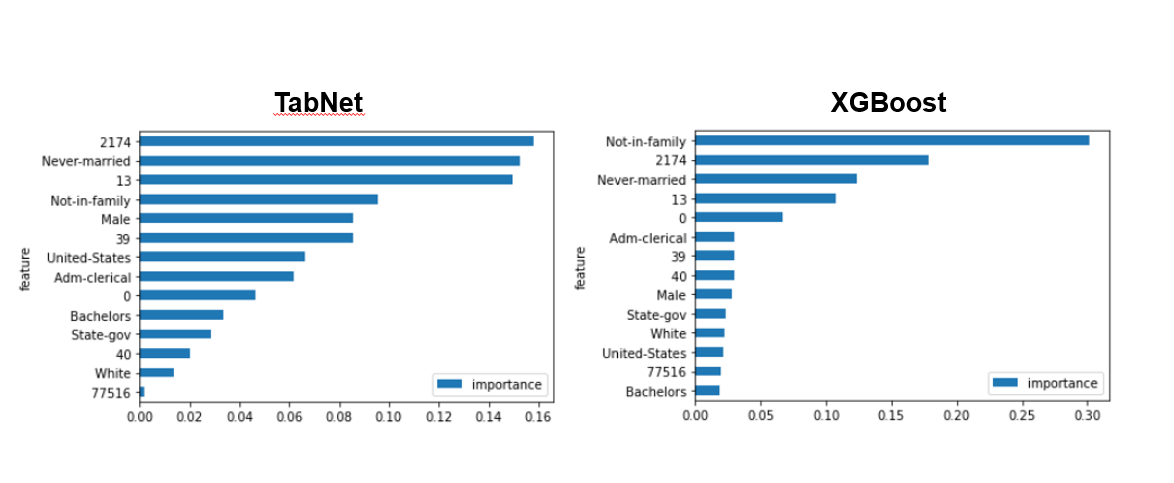
이 예시에서, TabNet을 썼을 때 중요도가 더 넓게 퍼져있는 것을 볼 수 있다. 이말인 즉슨, TabNet 이 피쳐들을 더 균등하게 사용하고 있다는 것이다. 이게 더 낫다고 말할 수는 없지만, 원 논문의 저자는 그들이 예상한 피쳐를 TabNet이 썼다고 말한다.
Masks
마스킹을 사용함으로써, 예측단계에서 사용된 피쳐에 대한 해석이 가능하다. 결합된 마스크(aggregate mask)를 볼 수도, 개별적인 마스크를 볼 수도 있다.
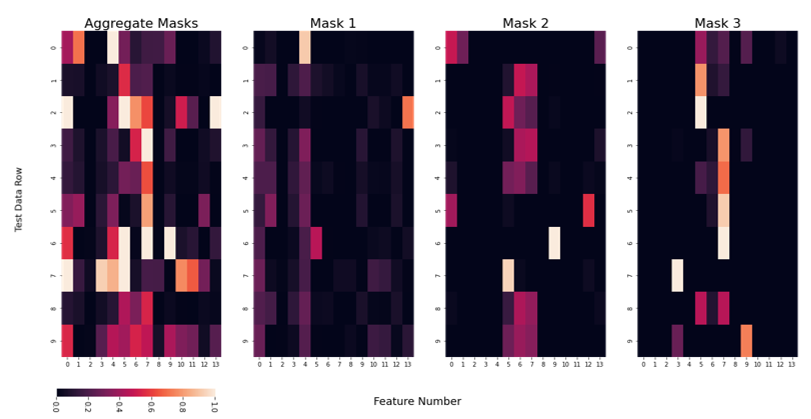
테스트 데이터의 첫번째 행을 보자.
mask1은 4번째 피쳐에 대해 매우 높은 priority를 준 것을 볼 수 있다.
반면 다른 마스크들은 다른 피쳐를 사용하고 있다.
그러나, 이러한 해석이 실제 피쳐값과 관련이 있는지는 미지수이다. 더 중요한 것은 우리는 아직 interaction term(두 변수의 상관관계)를 해석할 준비가 안되어있다는 것이다.
요즘에 transformer 안쓰는 곳이 없는 것 같다는 생각이 든다.
이런걸 볼때마다 흥미롭다는 생각이 든다.
