
면접 단골질문으로 Hash를 묻는 이유가 무엇일까?
오늘은 면접에서 Hash를 묻는 이유를 지극히 개인적인 생각으로 써볼 생각이다.
✅ Hash 란?
Hash에 대해서는 수 많은 글이 존재할 것이다. 긴 설명은 생략한다.
Hash는 데이터를 다루는 기법 중에 하나이다. 검색 및 저장에 아주 빠른 성능을 보인다. (평균 O(1))
특정 key 값을 임의의 "Hash Function"을 통과시켜 나온 값인 인덱스에 저장하는 기법이다.
🔍 묻는 이유
위에서 언급한대로 Hash 는 검색, 저장, 삭제 등등 데이터를 접근하는데 엄청난 시간을 줄여주는 효과가 있다.
이 또한 물어본 의도와는 맞지만, 나는 더 중요한 이유가 있다고 생각한다.
답을 먼저 말하자면 다음과 같다.
DB 서버를 분산화하면서, 일련의 데이터들을 Hash를 이용하여 서버마다 골고루 저장할 수 있다.
🔍 DB 의 분산화
기업에서는 사용자의 트래픽이 점점 많아짐으로 인해서 아주 많은 문제가 발생한다. 어플리케이션 서버 단에서도 많은 문제가 생기지만, DB 또한 문제가 생긴다.
다음의 그림을 보자.
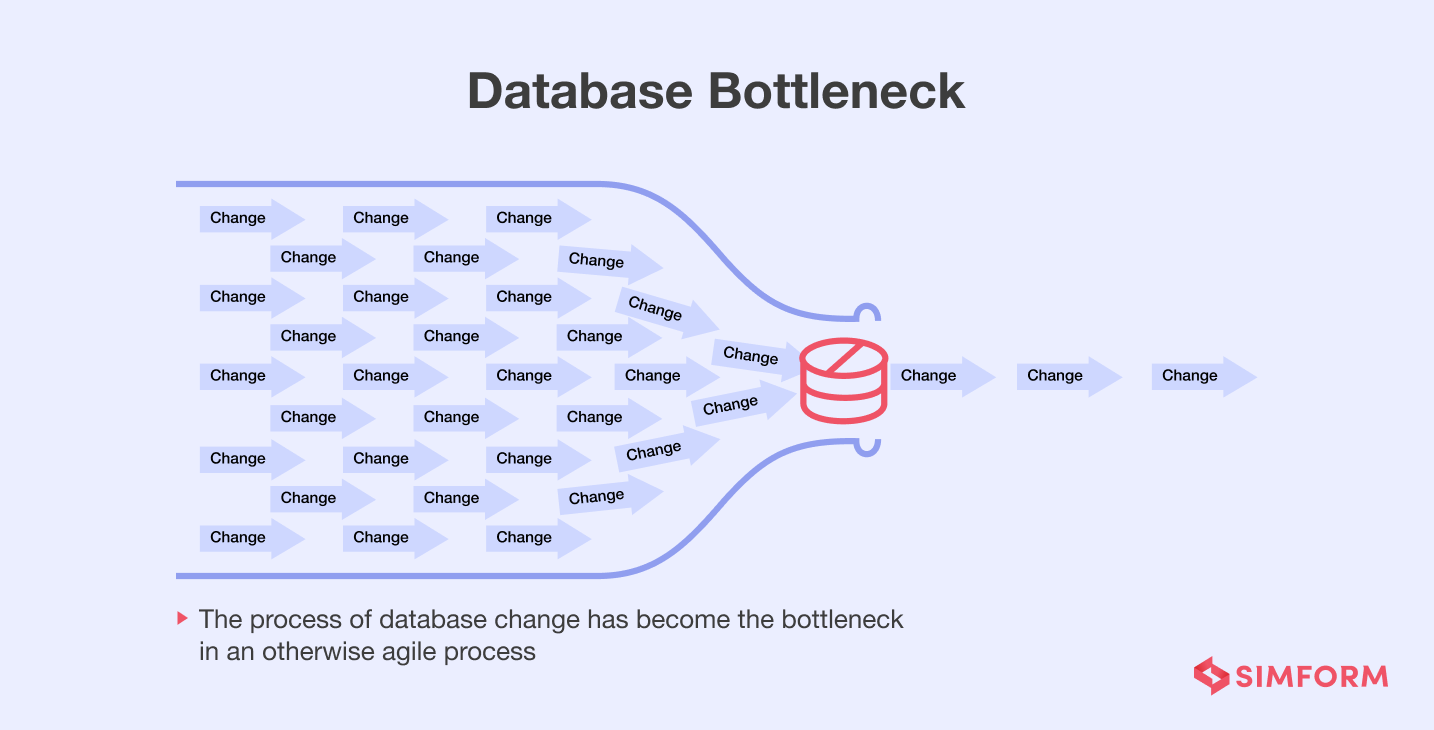
출처 : SIMFORM 페이지
위 그림은 엄청나게 많은 서버에서 어떠한 DB 1개에 접근을 하는 상황이다. 서버는 다중화하여 어플리케이션 서버 단은 병목현상이 일어나지 않는다. 하지만 DB에서 병목현상이 일어나고 있다.
이를 방지하기 위해서 DB 또한 분산화를 시작한 것이다.
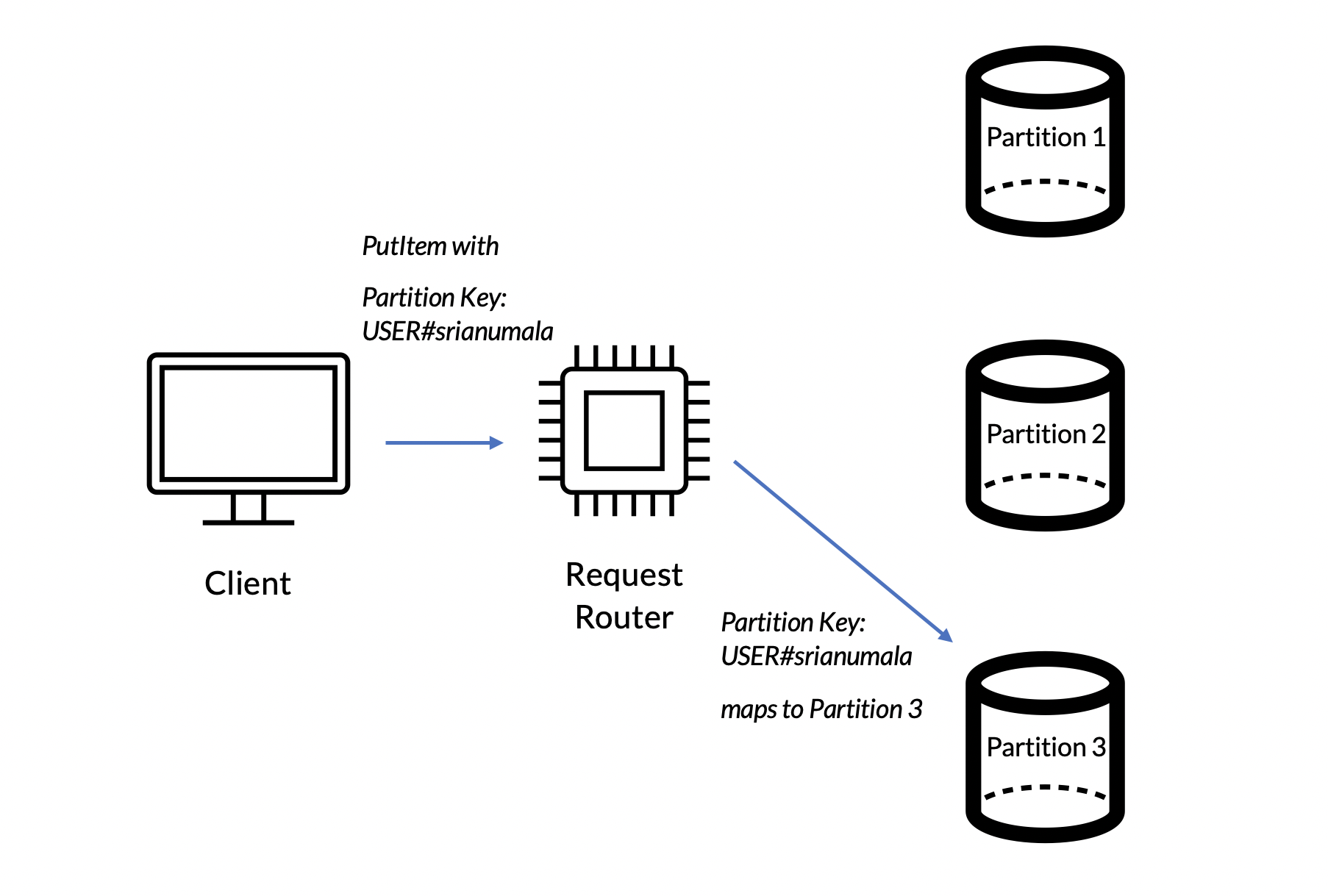
출처 : Credera
🔍 스마트한 분산화
DB는 분산하기로 했고 어떻게 분산해야하지?
DB를 분산하는 방법은 아주 많을 것이다.
-
DB 서버를 100개 준비하고 모든 데이터를 100개에 똑같이 저장한다. 그리고 로드밸런싱한다.
-
특정 범위를 기준으로 구분하여 각 DB에 저장한다. 특정 값에 접근할 때, 해당 값이 어느 DB에 있는지 파악한 후 DB 서버에 요청을 한다.
위의 두 가지 모두 좋은 방법이라고 생각한다. 하지만 각각 TradeOff가 존재한다.
각 방법의 장단점
1번 방법
1번 방법은 단순히 모든 DB를 복사하여 로드밸런싱만 해주면 되기 때문에 매우 간단하다.
그래서 장점으로는
- 매우 쉽다.
- 특정 서버가 장애가 났을 때, 다른 상태좋은 서버 아무 곳에 요청해도 좋다.
단점으로는
- 서버마다 엄청난 데이터를 저장해야하기 때문에, 용량적으로 바쳐주지않는다.
- 엄청난 데이터를 저장하기 때문에 성능적으로 좋지 못하다.
2번 방법
2번 방법은 데이터들을 특정 범위로 잘라서 여러가지 DB서버에 분산하여 저장하는 방법이다.
그래서 장점으로는
- 데이터를 분산화하여 용량적인 부담이 없다.
- 데이터를 엑세스가 엄청 빠를 "수" 있다.
단점으로는
- 어느 서버에 어떤 데이터가 저장되어있는지 생각하면서 개발을 진행해야한다.
- 어느 서버에 어떤 데이터를 저장할지 자~알 생각해야한다.
- 어떤 서버가 문제가 생기면 해당 서버가 가지고있는 데이터에 접근할 수가 없다.
- 개발자가 힘들다.
결국 2번 방법을 선택한다.
🔍 또 다른 문제
2번 방법대로 분산화를 하려고한다. 근데..
기존에 사용하던 RDBMS는 너무나 많은 연관관계가 있다. 때놓을 수가 없다.
그래서 NoSql이 등장하게 된다.
NoSql의 등장
NoSql은 많은 분들이 알고 계시듯, 저장에 대한 제약이 크게 존재하지 않고 자유롭게 저장한다.
그러기 때문에 다음과 같이 저장할 수가 있다.

출처 : Azure microsoft - SQL vs NoSQL
위 그림과 같이 한 컬렉션 단위로 저장을 하면 외래키에 걱정없이 분리시켜서 다른 서버에 저장해도 무방하다.
그래서 NoSQL을 선택했다.
-
NoSql이 떡상한 다른 이유
-
NoSql의 Async 지원
-
급격하게 변하는 서비스 요구사항에 따른 잦은 DB 설계 변경
-
인덱스 단위로 접근하여 빠른 접근 가능
등등 더 많다.
-
🔍 돌고돌아 Hash를 왜 묻느냐.
자 분산화를 한다는 것은 이해했다.
다음의 상황을 보고 어떤 DB 서버에 어떻게 저장할지 생각해보자.
-
서버는 10대가 준비되어있다.
-
1 ~ 1,000,000까지 순서대로 데이터가 저장 요청이 들어온다.
-
100,000,000,000번 숫자 조회 요청이 들어온다. 이 조회 요청은 모두 1 ~ 1000 까지의 조회 요청이다.
데이터를 어떤 서버에 어떻게 저장해야 합리적일까?
정답은
Hash 함수를 이용하여 10대에 고르게 고르게 저장하는 것이다.
1,000,000을 10개로 나누어 1 ~ 100,000까지는 1번 서버, 100,001 ~ 200,000까지는 2번 서버.. 로 저장하면 조회 요청에서 1번 서버에만 요청이 된다.
그래서 특정 hash function을 이용하여 1이면 1번 서버, 2이면 2번 서버, 3이면 3번서버 등등으로 고르게 저장하도록 하는 방식으로 하는게 합리적이다.
물론 다른 방법이 있다. 1 ~ 1000까지 캐싱하면 된다.
🤗 결론
Hash는 DB 분산화에서 데이터들을 고르게 분산하여 저장하기에 매우 적합한 알고리즘이다.
다음 시간부터 NoSql의 대표주자인 카산드라에 대해서 공부해보자.
