70. 최적화하기 전에 프로파일링을 하라.
요약
- 파이썬 프로그램을 느리게 하는 원인이 불문명한 경우가 많으므로, 프로그램을 최적화하기 전에 프로파일링하는 것이 중요하다.
profile모듈 대신cProfile모듈을 사용하라.cProfile이 더 정확한 프로파일링 정보를 제공한다.- 함수 호출 트리를 독립적으로 프로파일링하고 싶다면,
cProfile모듈의Profile객체의runcall메서드를 사용하기만 하면 된다. Stats겍체를 사용하면, 프로파일링 정보 중에서 프로그램 성능을 이해하기 위해 살펴봐야 할 부분만 선택해 출력할 수 있다.
본문
- 프로파일러(profiler): 프로그램의 각 부분이 실행 시간을 얼마나 차지하는지 결정할 수 있게 해주는 기능
- 파이썬에는 2가지 내장 프로파일러가 있다.
profile- 순수 파이썬으로 작성됨
- 결과가 왜곡될 수 있다.
cProfile- C 확장 모듈로 돼 있다.
- 이게 더 좋다.
- 프로파일 대상 프로그램의 성능에 최소로 영향을 미치기 때문이다.
- Note
- 외부 시스템의 성능을 배제한, 코드 자체의 성능을 측정하도록 유의해야 한다.
- 네트워크나 disk에 있는 자원에 접근하는 함수에 유의하라.
- 여러분의 프로그램이 이런 느린 자원의 응답 시간을 가리기 위해 cache를 사용한다면, profiling을 시작하기 전에 캐시를 적절히 예열 해둬야 한다.
def insertion_sort(data):
result = []
for value in data:
insert_value(result, value)
return result
def insert_value(array, value):
for i, existing in enumerate(array):
if existing > value:
array.insert(i, value)
return
array.append(value)
from random import randint
max_size = 10**4
data = [randint(0, max_size) for _ in range(max_size)]
test = lambda: insertion_sort(data)
from cProfile import Profile
profiler = Profile()
profiler.runcall(test)-
테스트 함수가 실행되고 나면,
pstats내장 모듈에 들어 있는Stats클래스를 사용해 성능 통계를 추출할 수 있다. -
Stats에 들어 있는 여러 메서드를 사용해- 관심 대상 프로파일 정보를 선택하고 정렬하는 방법을 조절해 내가 관심 있는 항목만 표시할 수 있다.
-
strip_dirs- file names로부터 온 모든 leading path 정보를 제거
- printout의 사이즈를 80 columns 정도로 줄이는데 매우 도움이 된다.
- 이 함수 수행을 끝낸 후에, ojbect는 랜덤한 순서로 entries를 가지고 있다고 간주된다.
- If strip_dirs() causes two function names to be indistinguishable (they are on the same line of the same filename, and have the same function name), then the statistics for these two entries are accumulated into a single entry.
-
sort_stats(*keys)
- 제공되는 기준에 따라 Stats object를 sorting
- The argument: a string or a SortKey enum identifying the basis of a sort
- (example: 'time', 'name', SortKey.TIME or SortKey.NAME).
- (The SortKey enums > string argument) in that it is more robust and less error prone.
- When more than one key is provided, then additional keys are used as secondary criteria when there is equality in all keys selected before them.
- For example, sort_stats(SortKey.NAME, SortKey.FILE) will
- sort all the entries according to their function name, and
- resolve all ties (identical function names) by sorting by file name.
- For example, sort_stats(SortKey.NAME, SortKey.FILE) will
- For the string argument, abbreviations can be used for any key names, as long as the abbreviation is unambiguous.

-
print_stats(*restrictions)
- profile.run()의 결과를 출력
- 더 알아보고 싶다면: https://docs.python.org/3/library/profile.html#pstats.Stats.print_stats
from pstats import Stats
stats = Stats(profiler)
stats.strip_dirs()
stats.sort_stats('cumulative') # 누적 통계
stats.print_stats()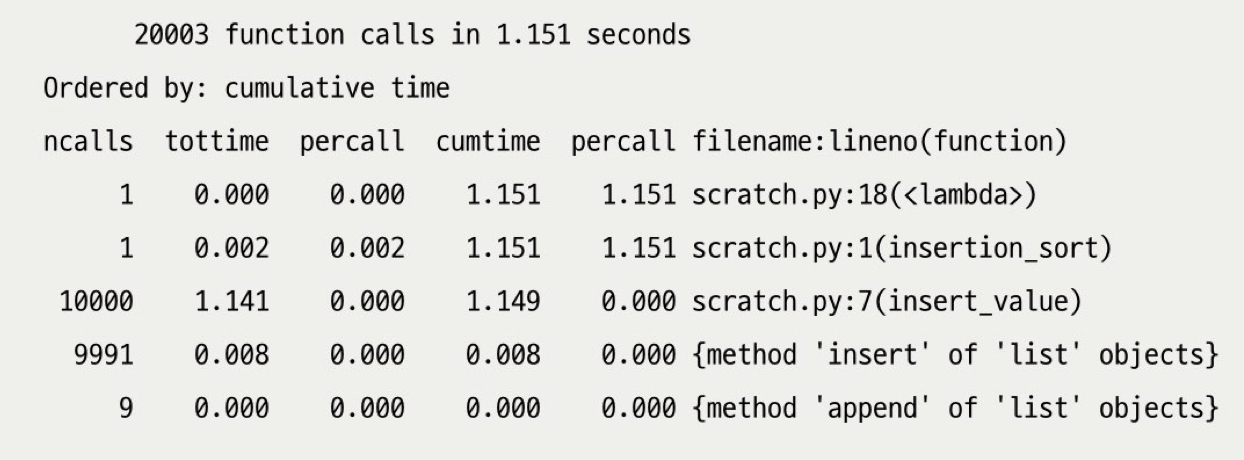
-
ncalls- 프로파일링 기간 동안 함수가 몇 번 호출됐는지 보여준다.
-
tottime- 프로파일링 기간 동안 대상 함수를 실행하는데 걸린 시간의 합계를 보여준다.
- 대상 함수가 다른 함수를 호출한 경우, 이 다른 함수를 실행하는데 걸린 시간은 제외된다.
-
tottime percall- 함수 1번 호출당 걸리는 시간의 평균
tottime / ncalls
-
cumtime- 함수를 실행할 때 걸린 누적 시간의 합
- 대상 함수가 호출한 다른 함수를 실행하는데 걸린 시간이 모두 포함됨
-
cumtime percallcultime/ncalls
-
stats.print_callers()- 특정 함수를, 누가?(어떤 다른 함수가?) 많이 호출했는지까지 보고 싶다면,
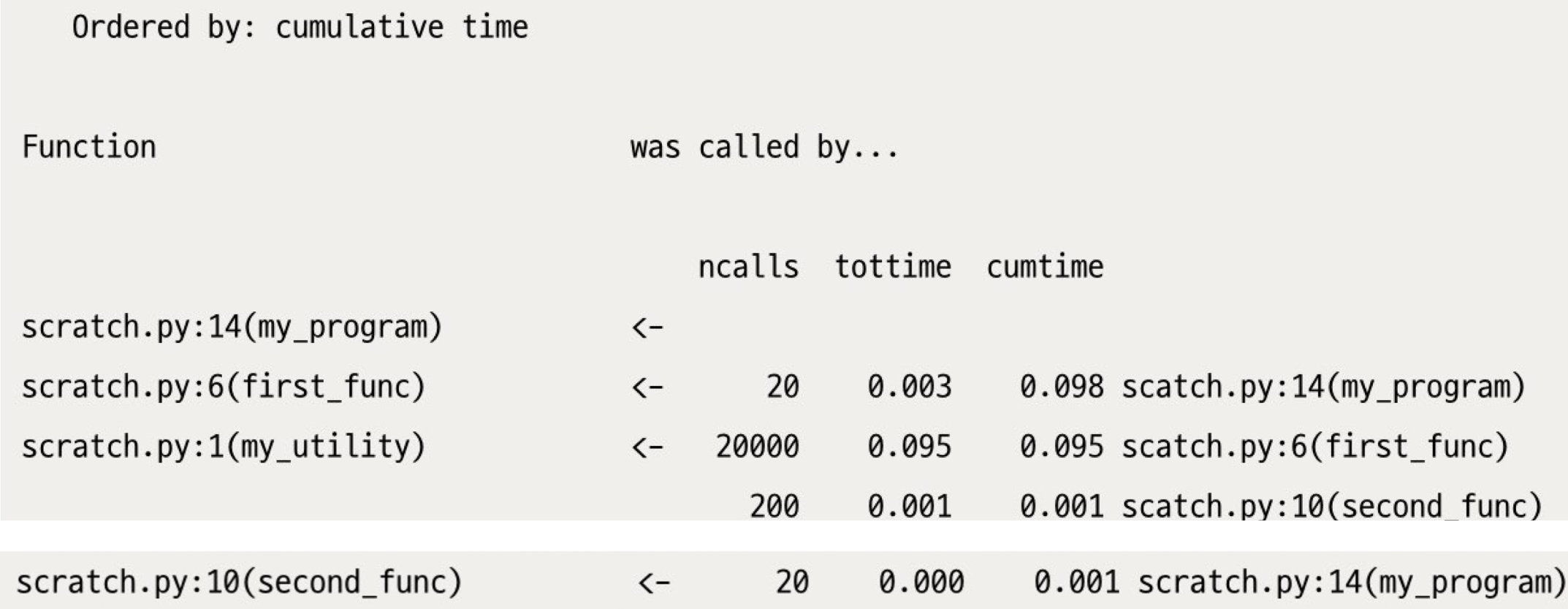
- 특정 함수를, 누가?(어떤 다른 함수가?) 많이 호출했는지까지 보고 싶다면,
71. 생산자-소비자 큐로 deque를 사용하라.
요약
- 생산자는
append를 호출해 원소를 추가하고, 소비자는pop(0)을 사용해 원소를 받게 만들면, 리스트타입을 FIFO 큐로 사용할 수 있다.- 하지만 리스트는 FIFO 큐로 사용하면, 큐가 길이가 늘어남에 따라
pop(0)의 성능이 선형보다 더 크게 나빠지기 때문에 문제가 될 수 있다.
- 하지만 리스트는 FIFO 큐로 사용하면, 큐가 길이가 늘어남에 따라
collections내장 모듈에 있는deque클래스는, 큐 길이와 관계없이 상수 시간 만에append와popleft를 수행하기 때문에 FIFO 큐 구현에 이상적이다.
본문
- deque = double ended queue
- 프로그램에서 생산자-소비자 대기열이 임계 단계라면, deque가 훌륭한 선택이다.
72. 정렬된 sequence를 검색할 때는, bisect를 사용하라.
요약
- 리스트에 들어 있는 정렬된 데이터를 검색할 때,
index 메서드를 사용하거나/for 루프와 맹목적인 비교를 사용하면 선형 시간이 걸린다. bisect내장 모듈의bisect_left함수는, 정렬된 리스트에서 원하는 값을 찾는 데 로그 시간이 걸린다. 따라서 다른 접근 방법보다 훨씬 빠르다.
본문
- 메모리에 정렬된 리스트로 존재하는, 커다란 데이터를 검색하고 싶은 경우가 자주 있다.
- 예: 특정 날짜의 금융 거래 목록을 읽어오는 경우
- 리스트에서
index함수를 사용해 특정 값을 지닌 index를 찾아내려면, 리스트 길이에 선형으로 비례하는 시간이 필요하다.
data = list(range(10**5))
index = data.index(91234)
assert index == 91234- 찾는 값이 리스트 안에 들어 있는지 모른다면, 원하는 값과 가장 유사한 index를 찾고 싶을 것인데, 이는 어렵다.
- bisect 모듈을 이용하라.
bisect_left- 정렬된 원소로 이뤄진 시퀀스에 대해 이진 검색을 효율적으로 수행 가능
- 반환하는 index는 리스트에 찾는 값의 원소가 존재하는 경우에도 가능, 존재하지 않는 경우, 정렬 순서상 해당 값을 삽입해야할 자리의 Index
- 리스트 뿐만 아니라, sequence 처럼 작동하는 모든 파이썬 객체에 대해 bisect 모듈의 기능을 사용할 수 있다는 점이다.
from bisect import bisect_left
index = bisect_left(data, 91234) # 정확히 일치
assert index == 91234
index = bisect_left(data, 91234.56) # 근접한 값과 일치
assert index == 91235
index = bisect_left(data, 91234.23) # 근접한 값과 일치(찾는 값 이상의 값 중 근접한 값을 찾음)
assert index == 9123573. 우선순위 큐로 heapq를 사용하는 법을 알아두라.
요약
- 우선순위 큐를 사용하면, FIFO가 아니라, 원소의 중요도에 따라 원소를 처리할 수 있다.
- 리스트 연산을 사용해 우선순위를 구현하면, 큐 크기가 커짐에 따라 프로그램의 성능이 선형보다 더 빠르게 나빠진다.
heapq내장 모듈은,효율적으로 규모 확장이 가능한 우선순위 큐를 구현하는 데 필요한 모든 기능을 제공한다.heapq를 사용하려면, 우선순위를 부여하려는 원소들이 자연스러운 순서를 가져야 한다.- 이는 원소를 표현하는 클래스에 대해
__It__와 같은 special method가 있어야 한다는 뜻이다.
- 이는 원소를 표현하는 클래스에 대해
- thread 안전한 다른 선택이 필요하다면
queue.PriortyQueue클래스를 보라.
본문
- 도서관 책을 빌려주고 반납하는 것을 관리하는 코드를 아래와 같이 짜면, 성능이 좋지 않다.
queue = []
add_book(queue, Book('돈키호테', '2020-06-07'))
add_book(queue, Book('프랑켄슈타인', '2020-06-05'))
add_book(queue, Book('레미제라블', '2020-06-08'))
add_book(queue, Book('전쟁과 평화', '2020-06-03'))
def add_book(queue, book):
queue.append(book)
queue.sort(key=lambda x: x.due_date, reverse=True)
class Book:
def __init__(self, title, due_date):
self.title = title
self.due_date = due_date
#########################
now = '2020-06-10'
found = next_overdue_book(queue, now)
print(found.title)
found = next_overdue_book(queue, now)
print(found.title)
try:
next_overdue_book(queue, now)
except NoOverdueBooks:
pass # 이 문장이 실행되리라 예상함
else:
assert False # 이 문장은 결코 실행되지 않음
def next_overdue_book(queue, now):
if queue:
book = queue[-1]
if book.due_date < now:
queue.pop()
return book
raise NoOverdueBooks
class NoOverdueBooks(Exception):
pass
#########################
queue = []
book = Book('보물섬', '2020-06-04')
add_book(queue, book)
print('반납 전:', [x.title for x in queue])
return_book(queue, book)
print('반납 후:', [x.title for x in queue])
def return_book(queue, book):
queue.remove(book)- heap은 여러 아이템을 유지하되, 새로운 원소를 추가하거나 가장 작은 원소를 제거할 때 로그 복잡도가 드는 데이터 구조다. (따라서 선형 복잡도보다 규모 확장성이 좋다.)
- 가장 작은 원소?: 만기가 가장 빠른 책
- heapq 안에 들어가는 원소들은, 반드시 원소 사이에 자연스러운 정렬 순서가 존재해야 한다.
- 이를 @functools.total_ordering 과
__lt__special method를 통해 구현 가능하다.
- 이를 @functools.total_ordering 과
import functools
@functools.total_ordering
class Book:
def __init__(self, title, due_date):
self.title = title
self.due_date = due_date
def __lt__(self, other):
return self.due_date < other.due_datequeue 를 만드는 3가지 방법
- 방법 1 (
heappush)
from heapq import heappush
queue = []
add_book(queue, Book('오만과 편견', '2020-06-01'))
add_book(queue, Book('타임 머신', '2020-05-30'))
add_book(queue, Book('죄와 벌', '2020-06-06'))
add_book(queue, Book('폭풍의 언덕', '2020-06-12'))
def add_book(queue, book):
heappush(queue, book)- 방법 2 (
list.sort())
queue = [
Book('오만과 편견', '2020-06-01'),
Book('타임 머신', '2020-05-30'),
Book('죄와 벌', '2020-06-06'),
Book('폭풍의 언덕', '2020-06-12'),
]
queue.sort()- 방법 3 (
heapify)
from heapq import heapify
queue = [
Book('오만과 편견', '2020-06-01'),
Book('타임 머신', '2020-05-30'),
Book('죄와 벌', '2020-06-06'),
Book('폭풍의 언덕', '2020-06-12'),
]
heapify(queue)대출 만기를 넘긴 책을 검사하는 방법
heappop
from heapq import heappop
now = '2020-06-02'
book = next_overdue_book(queue, now)
print(book.title)
book = next_overdue_book(queue, now)
print(book.title)
try:
next_overdue_book(queue, now)
except NoOverdueBooks:
pass # 이 문장이 실행되리라 예상함
else:
assert False # 이 문장은 결코 실행되지 않음
##################
def next_overdue_book(queue, now):
if queue:
book = queue[0] # 만기가 가장 이른 책이 맨 앞에 있다
if book.due_date < now:
heappop(queue) # 연체된 책을 제거한다
return book
raise NoOverdueBooks제시간에 반납된 책을 처리하는 방법
- 이 방법의 단점: 도서관의 모든 대출된 책이 모두 만기 이전에 반환된 경우, 가장 빠른 만기일이 될 때까지는 힙의 크기가 최대 크기에서 줄어들지 않는다는 것이다.
heapq를 사용하면 힙 연산은 빨라지지만, 메모리 사용량이 크게 늘어날 수 있음에 주의하라.
@functools.total_ordering
class Book:
def __init__(self, title, due_date):
self.title = title
self.due_date = due_date
self.returned = False # 새로운 필드
def __lt__(self, other):
return self.due_date < other.due_date
def next_overdue_book(queue, now):
while queue:
book = queue[0]
if book.returned:
heappop(queue)
continue
if book.due_date < now:
heappop(queue)
return book
break
raise NoOverdueBooks
def return_book(queue, book):
book.returned = True74. bytes를 복사하지 않고 다루려면, memoryview와 bytearray를 사용하라.
요약
memoryview내장 타입은, 객체의 슬라이스에 대해 -> 파이썬 고성능 버퍼 프로토콜로 읽고 쓰기를 지원하는, 복사가 없는 interface를 제공한다.bytearray내장 타입은 복사가 없는 읽기 함수(socket.recv_from과 같은)에 사용할 수 있는bytes와 비슷한 변경 가능한 타입을 제공한다.memoryview로bytearray를 감싸면, 복사에 따른 비용을 추가 부담하지 않고도 수신받은 데이터를 범퍼에서 원하는 위치에 slice할 수 있다.
내용
- 필요할 때 공부하자.
번외. timeit을 통해, 걸리는 시간에 대한 마이크로 벤치마크를 수행하라.
def run_linear(data, to_lookup):
for index in to_lookup:
data.index(index)
def run_bisect(data, to_lookup):
for index in to_lookup:
bisect_left(data, index)
baseline = timeit.timeit(
stmt='run_linear(data, to_lookup)',
globals=globals(),
number=10)
print(f'선형 검색: {baseline:.6f}초')
comparison = timeit.timeit(
stmt='run_bisect(data, to_lookup)',
globals=globals(),
number=10)
print(f'이진 검색: {comparison:.6f}초')
slowdown = 1 + ((baseline - comparison) / comparison)def heap_overdue_benchmark(count):
def prepare():
to_add = list(range(count))
random.shuffle(to_add)
return [], to_add
def run(queue, to_add):
for i in to_add:
heappush(queue, i)
while queue:
heappop(queue)
tests = timeit.repeat(
setup='queue, to_add = prepare()',
stmt=f'run(queue, to_add)',
globals=locals(),
repeat=100,
number=1)
return print_results(count, tests)
baseline = heap_overdue_benchmark(500)
for count in (1_000, 1_500, 2_000):
comparison = heap_overdue_benchmark(count)
print_delta(baseline, comparison)
새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.