Loss
actor loss
- dataset의 state를 가져와서,
그 state에서 내가 현재 생각하는 action을 할 확률=state에서 내가 현재 생각하는 action을 했을 때의 가치로 만드는 것이 목표!- 알파가 크면, action probability가 Q분포를 부드럽게(덜 엄격하게)따라갈 것이다.
- 탐험 많이
- 알파가 작으면, action probability가 Q분포를 엄격하게 따라갈 것이다.
- 탐험 적게
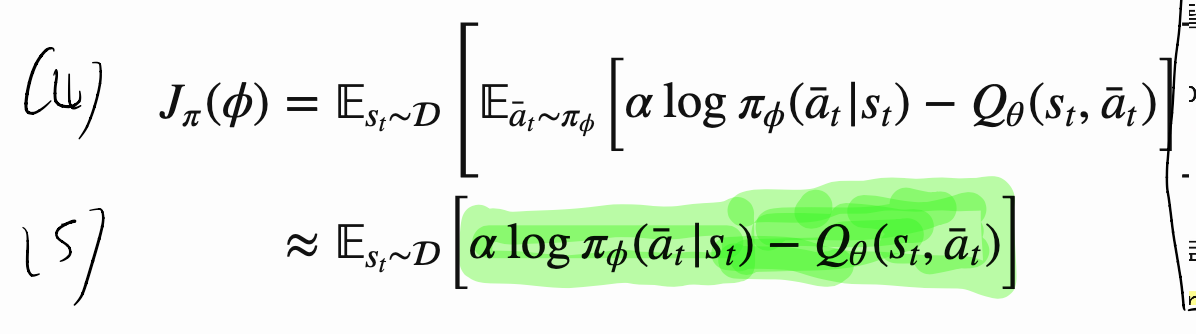
- 탐험 적게
Critic loss
- 데이터 셋에서, st, at, r, st+1 가져옴
- st, at의 행동을 가치 평가 잘하고 싶어.
- = reward + (st+1 상황에서 내가 생각한 행동을 했을 때의 가치)의 평균
- = reward + (st+1 상황에 온 가치)
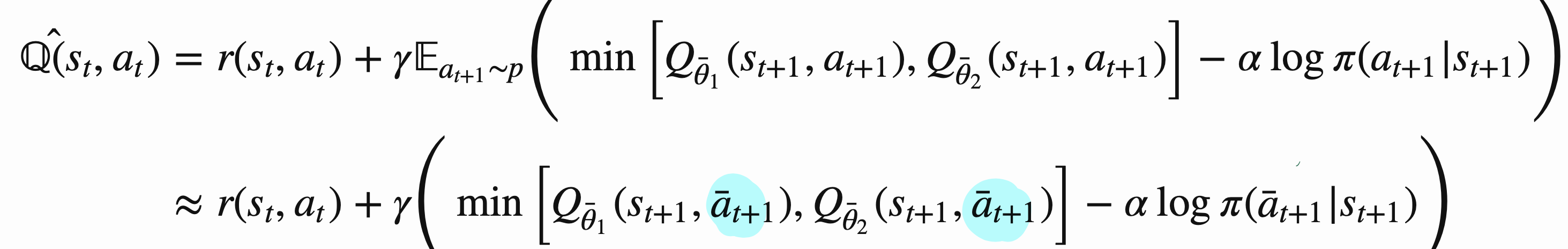
Temperature loss
- 현재 entropy가 target_entropy보다 작으면(음수), temperature(log alpha)가 큰 양수가 되도록 학습될 것입니다.
- 즉 탐험을 더 많이 하는 방향으로 학습될 것입니다.
- 현재 entropy가 target_entropy보다 크면(양수), temperature(log alpha)를 작은 음수(절댓값이 큰 음수)가 되도록 학습될 것입니다.
temperature_loss = log_temperature * (entropy - self.target_entropy).detach()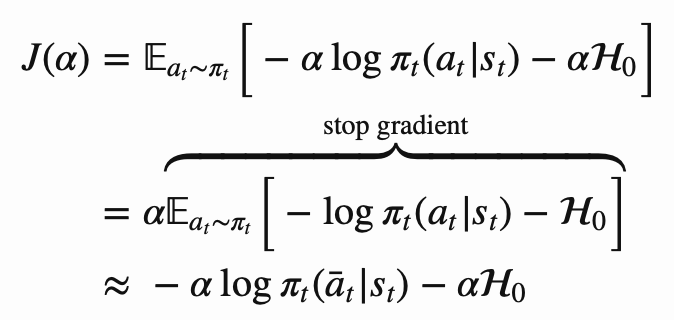
전체 큰 구조
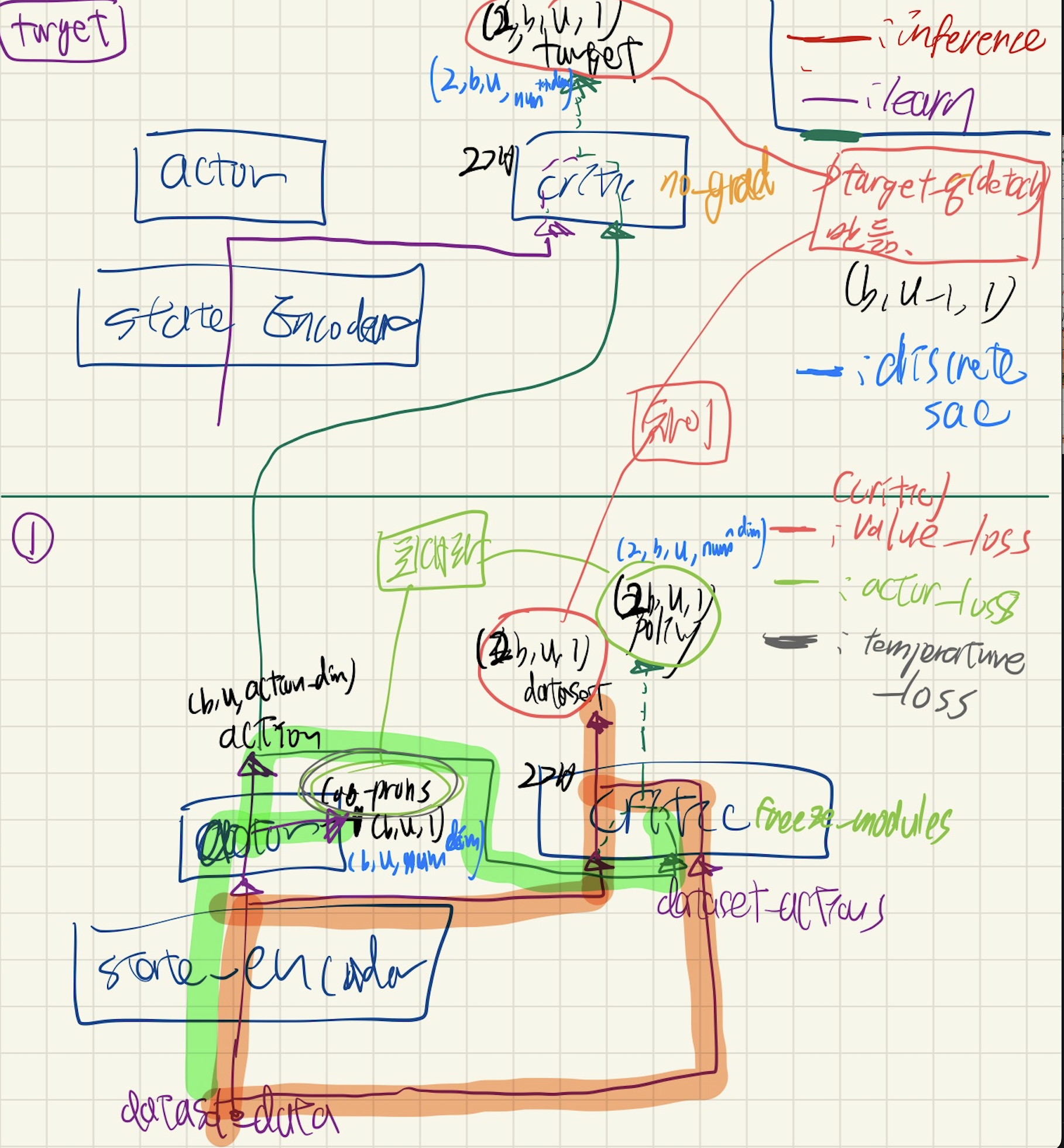
State Encoder
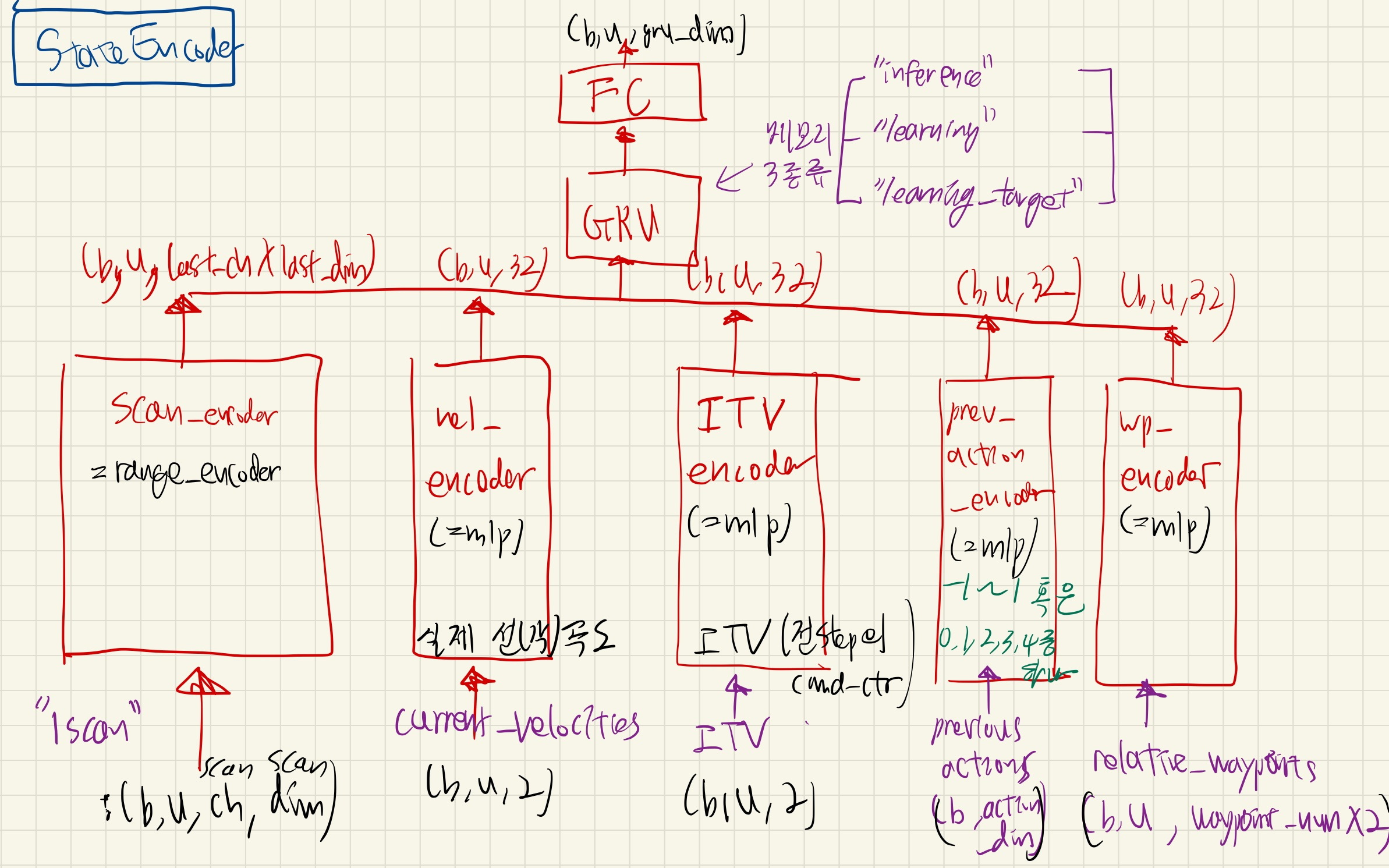
세부 사항
- RangeEncoder
- nn.Conv1d
- 나머지: mlp_block 2개
- Linear + LayerNorm + ACTIVATION
- GRULayerNormJIT
MLPGaussianActor / MLPDiscreteActor
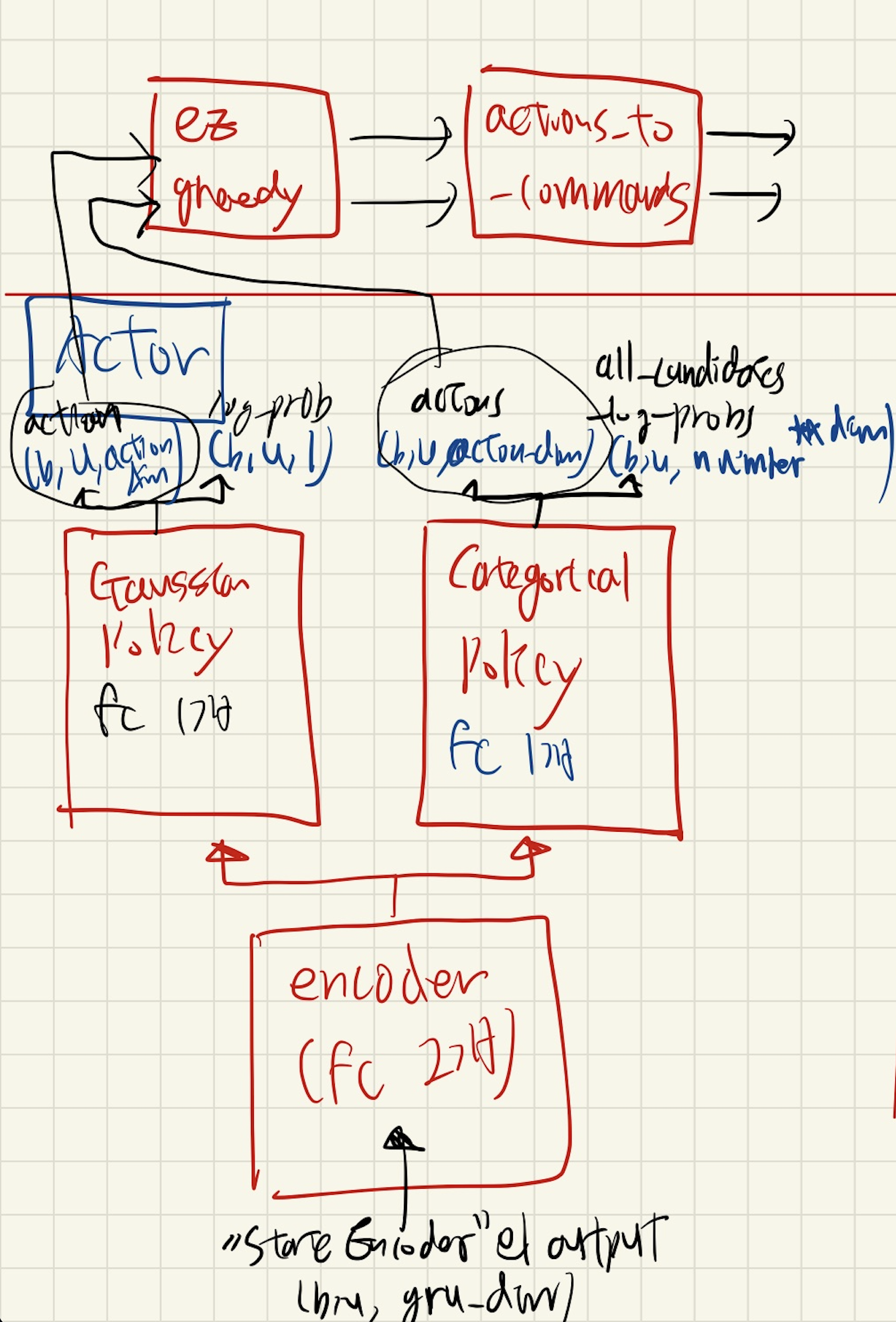
세부 사항
encoder- mlp_block 2개
- Linear + LayerNorm + ACTIVATION
- mlp_block 2개
- Gaussian Policy / Categorical Policy
- Linear 1개
MLPCritic / MLPDiscreteCritic
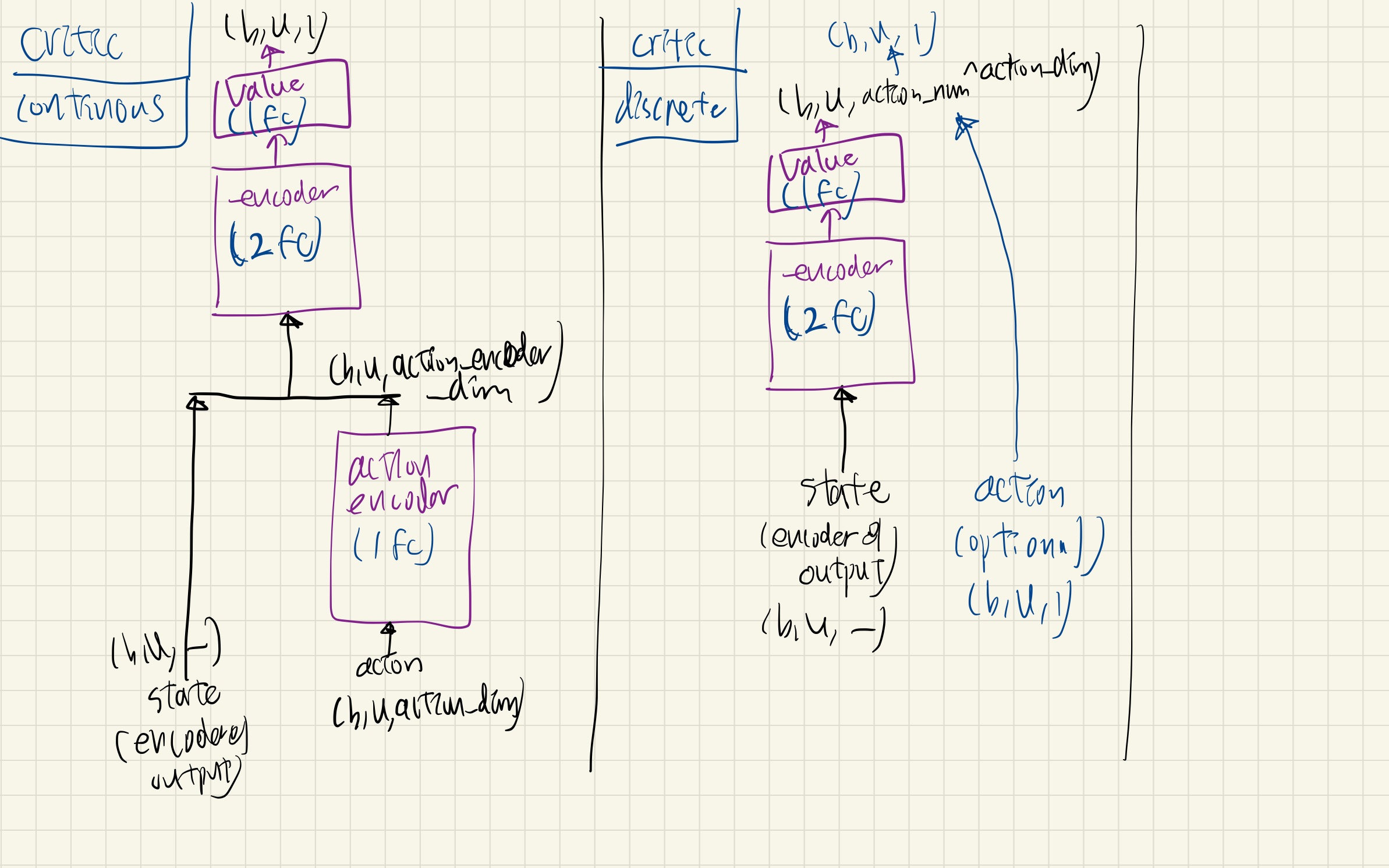
_action_encoder- mlp_block 1개
- Linear + LayerNorm + ACTIVATION
- mlp_block 1개
_encoder- mlp_block 2개
- Linear + LayerNorm + ACTIVATION
- mlp_block 2개
- value
- Linear 1개

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.