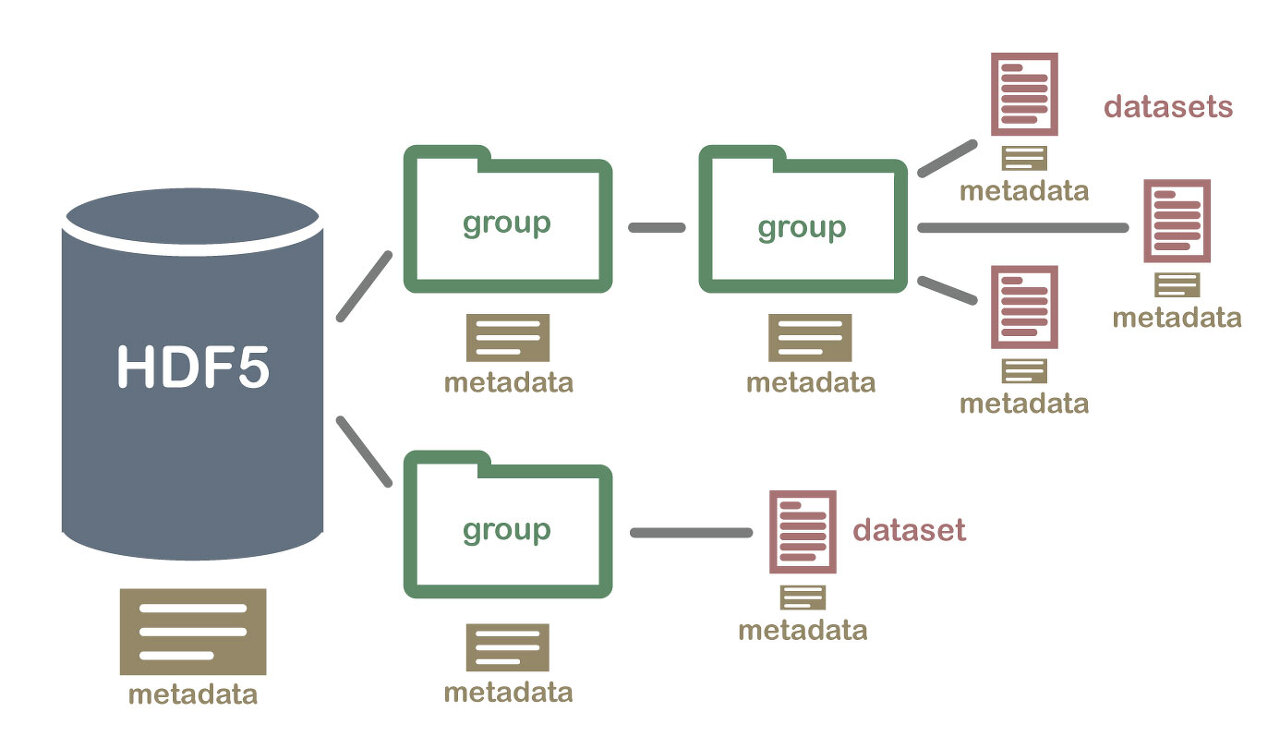
- HDF5 구조에서, 각 폴더는 'Group'이라고 불린다.
- Root 폴더 역시 하나의 폴더인 것처럼, 생성한 HDF file 역시 하나의 group이다.
- root에도 dataset을 생성할 수 있다
- 파일의 역할을 하는 것은 'Dataset'과 'Attribute'이다.
- Dataset은 HDF5 file에 담겨져 있는 데이터를 말한다. 예를 들면 numpy array가 될 수 있다.
- Attribute는 데이터의 metadata라고 생각할 수 있다. 데이터에 대한 정보들을 함께 보관할 수 있다.
개요
- h5py는 Python에서 Hierarchical Data Format version 5 (HDF5) 파일 형식을 읽고 쓸 수 있는 라이브러리입니다.
- HDF5는 대용량의 복잡한 데이터를 저장하고 검색하기 위한 파일 형식으로, 과학적 데이터셋을 저장하는 데 주로 사용됩니다.
- h5py 라이브러리는 고성능의 데이터 I/O 기능을 제공하며, 데이터의 메타데이터와 함께 저장이 가능합니다.
장점
- 대용량 데이터 처리
- HDF5는 대용량의 다차원 배열과 복합 데이터를 저장하고 검색하는 데 최적화되어 있습니다.
- 사용 편의성
- h5py는 Python의 네이티브 인터페이스로 NumPy와 호환되어 사용하기 쉽습니다.
- 데이터 압축
- HDF5는 데이터를 저장할 때 압축을 지원하여 디스크 공간을 절약할 수 있습니다.
- 부분적 데이터 로딩
- h5py는 파일의 일부만 로드할 수 있는 슬라이싱 기능을 제공합니다. 이를 통해 메모리 사용량을 줄일 수 있습니다.
단점
- 표준성
- HDF5 파일 형식은 전용 포맷이므로, 다른 언어나 라이브러리를 사용하려면 추가적인 도구가 필요합니다.
- 병렬 I/O 지원
- h5py는 병렬 I/O를 기본적으로 지원하지 않습니다. 이를 위해서는 별도의 라이브러리를 사용해야 합니다.
사용법
h5py 파일 생성 및 작성
with h5py.File('myfile.hdf5', 'w') as f:
...
h5py.File.create_dataset(name, shape=None, dtype=None, data=None, **kwds)- name: 데이터셋의 경로와 이름
- shape: 데이터셋의 차원(shape). 기본값은 ()으로, 스칼라 데이터셋을 생성할 때 사용됩니다.
- dtype: 데이터셋에 저장될 데이터 타입(dtype). 기본값은 "float64"입니다.
- data: 데이터셋에 저장될 데이터. "data"와 "shape" 중 하나만 사용할 수 있습니다.
- kwds: 추가적인 데이터셋 속성. 예를 들어, 압축(compression) 또는 청크 크기(chunk size) 등을 지정할 수 있습니다.
- chunks
- chunks 파라미터는 데이터셋을 여러 개의 블록(또는 청크)으로 나누는 데 사용됩니다. 청크는 데이터셋의 일부를 나타내며, 청크 크기는 튜플 형태로 지정됩니다.
- 청크를 사용하면 데이터의 일부분만 읽거나 쓸 때 효율성이 향상됩니다. 특히, 데이터셋이 클 경우나 무작위로 액세스해야 하는 경우에 유용합니다.
- chunks 파라미터를 설정하지 않으면, 데이터셋 전체가 하나의 청크로 저장됩니다. 이 경우, 데이터셋 전체를 메모리에 올리지 않으면서 부분적으로 액세스하기 어렵습니다.
- maxshape
- maxshape 파라미터는 데이터셋의 최대 크기를 지정하는 데 사용됩니다. 각 차원에 대한 최대 크기를 담은 튜플 형태로 지정할 수 있습니다.
- maxshape를 사용하면 데이터셋의 크기를 동적으로 변경할 수 있습니다. 이를 이용해 가변 길이의 데이터셋을 만들 수 있습니다.
- maxshape를 설정하지 않으면, 데이터셋의 크기는 고정되며 이후에 변경할 수 없습니다.
- compression
- compression 파라미터는 데이터셋에 압축을 적용할지 여부를 결정하는 데 사용됩니다. 데이터셋의 크기를 줄이고, 디스크 공간을 절약할 수 있습니다.
- 다양한 압축 방식을 지정할 수 있으며, 가장 일반적인 방식은 "gzip", "lzf" 및 "szip"입니다.
- compression 파라미터를 설정하지 않으면, 데이터셋에 압축이 적용되지 않습니다.
- 압축을 사용하면 데이터 크기는 줄지만, 압축 및 해제 과정에서 시간이 소요됩니다. 따라서 압축을 사용할지 여부는 시간과 공간 사이의 트레이드오프를 고려해 결정해야 합니다.
import h5py
import numpy as np
# 쓰기 모드로 파일 생성
with h5py.File('example.h5', 'w') as f:
# 데이터셋 생성 및 저장
data = np.random.random(size=(100, 100))
f.create_dataset('my_dataset', data=data)Group
h5py.Group.create_group(name)- 그룹을 생성할 수 있다.
- 이 그룹들은 "h5py.File" 객체 "f" 내부에 저장됩니다.
- 그룹은 데이터셋(dataset)과 마찬가지로, 속성(attribute)을 가질 수 있습니다.
- 예를 들어, 그룹에 대한 설명(description), 그룹의 작성자(author), 그룹의 생성 날짜(created date) 등을 저장할 수 있습니다.
- 그룹의 속성은 그룹 객체의 "attrs" 속성을 사용하여 추가하거나 조회할 수 있습니다.
- 그룹은 HDF5 데이터 파일 내의 경로와 유사한 방식으로 작동합니다.
- 그룹은 데이터셋을 구성하는 하나의 요소이며, 데이터 파일 내에서 그룹의 경로는 경로 문자열의 일부입니다.
- HDF5 데이터 파일은 파일 내에 데이터 객체들(그룹, 데이터셋 등)을 포함하고, 이러한 객체들의 경로는 파일 내에서 "/" 문자로 구분된 경로 문자열로 나타납니다.
- 생성된 group들은 Python dictionary와 같은 방식으로 관리된다.
- 각 group의 name이 key가 되어, name을 이용해 각 group에 접근할 수 있고, 마찬가지로 dictionary의 여러 기능들을 이용할 수 있다.
import h5py
with h5py.File('example.h5', 'w') as f:
# 1단계 그룹 생성
grp1 = f.create_group("group1")
print(grp1.name)
# 2단계 그룹 생성
grp2 = grp1.create_group("group2")
# 2차원 배열 데이터 저장
data = [[1, 2, 3], [4, 5, 6]]
dset = grp2.create_dataset("my_dataset", data=data)
#group 접근
group2 = f['/group1/group2'] #이미 생성되어 있는 group만 가능
#group들의 list 확인
print(list(f.keys())
>> ['group1']
print(list(grp1.keys())
>> ['group2']
#group 삭제
del f['/group1/group2']
print(list(grp1.keys())
>> []h5py 파일 읽기
import h5py
# 읽기 모드로 파일 열기
with h5py.File('example.h5', 'r') as f:
# 데이터셋 로드
data = f['my_dataset'][:]
print(data)h5py를 이용한 부분적 데이터 로딩
import h5py
# 읽기 모드로 파일 열기
with h5py.File('example.h5', 'r') as f:
# 데이터셋의 일부만 로드
data_slice = f['my_dataset'][10:20, 10:20]
print(data_slice)attrs
- "h5py" 모듈의 데이터셋과 그룹은 "attrs" 속성(attribute)을 가지고 있습니다.
이 속성은 그룹 또는 데이터셋에 대한 속성 정보를 저장하는 데 사용됩니다. - 속성(attribute)은 데이터셋과 그룹의 메타데이터(metadata)를 저장하는 데 유용합니다.
- 예를 들어, 데이터셋의 차원(shape), 데이터셋에 대한 설명(description), 데이터셋의 작성자(author) 등을 저장할 수 있습니다.
- 이러한 정보는 데이터셋을 관리하고 분석하는 데 필요한 유용한 정보를 제공합니다.
import h5py
with h5py.File('example.h5', 'w') as f:
f.attrs['author'] = 'John Doe'
f.attrs['created_on'] = '2023-03-17'
# 혹은
group_a.attrs.create('attr_a', data='hello')
# Dataset과 다른 점은, attribute의 경우 접근과 동시에 생성을 할 수도 있다.
group_a.attrs['attr_b'] = 'hi'h5py.vlen_dtype(basetype)
-
Make a numpy dtype for an HDF5 variable-length datatype.
-
h5py.vlen_dtype은 h5py에서 가변 길이(vlen) 데이터 타입을 정의할 때 사용되는 함수입니다.
-
가변 길이 데이터 타입(vlen data type)이란, 데이터의 길이가 고정되지 않은 데이터 타입을 의미합니다.
-
예를 들어, 문자열이나 숫자 배열 등이 가변 길이 데이터 타입에 해당합니다.
-
이러한 데이터 타입을 저장하려면, HDF5 파일 내에서 데이터 길이를 먼저 저장하고, 실제 데이터를 저장하는 방식을 사용합니다.
-
h5py.vlen_dtype 함수는 이러한 가변 길이 데이터 타입을 정의할 때 사용됩니다.
-
이 함수는 파이썬 데이터 타입을 매개변수로 받아서, 해당 데이터 타입을 가변 길이 데이터 타입으로 변환합니다.
-
예를 들어, h5py.vlen_dtype(np.float32)는 32비트 부동소수점 배열을 가변 길이 데이터 타입으로 변환합니다.
-
이렇게 변환된 가변 길이 데이터 타입은 h5py의 create_dataset 메서드 등에서 사용될 수 있습니다.
-
이를 통해 가변 길이 데이터 타입을 갖는 데이터를 HDF5 파일 내에 저장하고, 이를 파이썬에서 다룰 수 있습니다.
import h5py
import numpy as np
# 가변 길이 문자열 데이터 타입 정의
dt = h5py.vlen_dtype(np.dtype('S10'))
# HDF5 파일 생성 및 데이터 저장
with h5py.File('example.h5', 'w') as f:
dset = f.create_dataset('strings', shape=(3,), dtype=dt)
dset[0] = np.array([b'hello', b'world'], dtype='S10')
dset[1] = np.array([b'foo', b'bar', b'baz'], dtype='S10')
dset[2] = np.array([b'one', b'two', b'three', b'four'], dtype='S10')- 이 예시에서는, 우선 h5py.vlen_dtype 함수를 사용하여, 길이가 최대 10바이트인 문자열을 저장할 수 있는 가변 길이 문자열 데이터 타입(dt)을 정의합니다.
- 이후, 'example.h5'라는 이름의 HDF5 파일을 생성하고, 'strings'이라는 이름의 데이터셋을 생성합니다.
- 이 데이터셋의 dtype을 dt로 지정하여, 가변 길이 문자열 데이터를 저장할 수 있도록 합니다.
- 마지막으로, 데이터셋에 문자열 데이터를 저장합니다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.