1. 언제 써야해? 장점?
- 한줄 요약: 10개의 주방 / 10개의 요리사 / 10개 해야할 요리
- parallel 을 확보하기 위함 ( CPU를 많이 쓰고, I/O waiting 이 적은 테스크에 적합)
- pool을 쓸 수 있습니다.
- 공유 메모리를 사용하는 더 고급스러운 기능을 제공합니다.(다른 패키지와 비교했을 때)
- 하지만, 이러한 고급 기능을 사용하는 것은 매우 복잡하다.
- 이 고급스러운 기능 사용은 다른 모든 패키지들을 사용해보고도 안되면, 제일 마지막 단계에 시도하라.
2. 단점?
- 해당 모듈로 짠 process를 thread로 바꾸기 위해서는 힘든 리펙토링이 들어갑니다.
3. 메서드와 어트리뷰트
import os
from multiprocessing import Process
num = 42
def f(name):
global num
num += 1
print('pid of parent:', os.getppid())
print('pid of %s : %d' %(name, os.getpid()))
print('%d' %num)
if __name__ == '__main__':
print('pid of main:', os.getpid())
p1 = Process(target=f, args=("proc_1",))
p2 = Process(target=f, args=("proc_2",))
p1.start(); p1.join()
p2.start(); p2.join()- p = mp.Process(target=None, name=None, args=(), kwargs={}, *, daemon=None)
- daemon 인자는 프로세스 daemon 플래그를 True 또는 False 로 설정합니다. None (기본값) 이면, 이 플래그는 만드는 프로세스로부터 상속됩니다.
- p.run()
- 프로세스의 활동을 나타내는 메서드.
- 서브 클래스에서 이 메서드를 재정의할 수 있습니다.
- 표준 run() 메서드는 객체의 생성자에 target 인자로 전달된 콜러블 객체를 호출하는데 (있다면) args 와 kwargs 인자를 각각 위치 인자와 키워드 인자로 사용합니다.
- p.start()
- 프로세스의 활동을 시작합니다.
- 이것은 프로세스 객체 당 최대 한 번 호출되어야 합니다.
- 객체의 run() 메서드가 별도의 프로세스에서 호출되도록 합니다.
- p.join([timeout])
프로세스의 실행이 완료될 때까지 기다립니다.- 프로세스가 시작된 후 (start() 메소드 호출 이후) 실행을 마칠 때까지 기다리는 데 사용됩니다.
- 선택적 인자 timeout 이 None (기본값) 인 경우, 메서드는 join() 메서드가 호출된 프로세스가 종료될 때까지 블록 됩니다.
- timeout 이 양수면 최대 timeout 초 동안 블록 됩니다.
- 이 메서드는 프로세스가 종료되거나 메서드가 시간 초과 되면 None 을 돌려줌에 주의해야 합니다.
- 프로세스의 exitcode 를 검사하여 종료되었는지 확인하십시오.
- 프로세스는 여러 번 조인할 수 있습니다.
- 교착 상태를 유발할 수 있으므로 프로세스는 자신을 조인할 수 없습니다.
- 프로세스가 시작되기 전에 프로세스에 조인하려고 하면 에러가 발생합니다.
- p.terminate()
- 해당 프로세스는 현재 실행 중인 작업을 완료하지 않고 강제로 종료
- 이는 데드락(deadlock) 상태에 빠진 프로세스를 종료시키거나,
- 더 이상 필요하지 않은 작업을 실행 중인 프로세스를 종료시킬 때 유용
- 프로세스가 정리 코드를 실행하지 못하도록 하므로, 열린 파일이나 네트워크 연결과 같은 리소스가 제대로 정리되지 않을 수 있습니다.
- 가능한 한 이 메소드의 사용을 피하고, 프로세스가 자체적으로 종료할 수 있는 방법을 마련하는 것이 좋음
- p.close()
- 호출하면 더 이상 해당 프로세스 객체를 사용하여 새 작업을 시작할 수 없습니다.
close()메서드를 실행하면 아래 "리소스" 가 정리됩니다.- 프로세스 핸들과 관리 리소스:
- 프로세스를 생성하고 관리할 때, 운영 체제는 이를 위한 리소스를 할당
프로세스의 식별자,상태 정보, 그리고프로세스 제어를 위한 핸들등이 포함
multiprocessing내부 리소스:- 기존:프로세스 간 통신(IPC)을 위해 파이프, 큐, 공유 메모리 등의 메커니즘을 제공
- 이러한 메커니즘을 구현하기 위해 모듈 내부적으로 다양한 리소스가 사용됨
close()메서드는 이러한 내부 리소스의 정리에 도움을 줍니다.
- 그러나, 프로세스가 직접 열었던 파일이나 네트워크 연결과 같은 리소스는
close()메서드의 책임 범위 밖 - 이러한 리소스는 프로세스 내에서 명시적으로 관리되어야 하며, 프로세스의 코드 내에서 적절히 열고 닫아야 합니다.
- 예를 들어, 파일을 열어 작업한 후에는 해당 파일을 명시적으로 닫거나, 네트워크 연결을 종료하는 등의 작업이 필요합니다.
close()메서드는 프로세스를 종료시키지 않으며, 프로세스가 실행 중인 상태에서는 해당 프로세스의 실행을 중단시키지 않음close()의 주된 목적은 프로세스 객체와 관련된 시스템 리소스를 해제하는 것이지, 실행 중인 프로세스의 작업을 중단시키는 것이 아닙니다.- 따라서 프로세스 내부에서 무한 루프(
while True:등)가 돌고 있을 경우,close()를 호출한다고 해서 해당 루프가 중단되거나 프로세스가 종료되지 않습니다. - 실행 중인 프로세스를 종료하려면,
terminate()메서드를 사용해야 합니다.
- proc = mp.current_process()
- 현재 실행되는 프로세스에 대한 정보를 담고 있는 객체를 얻을 수 있다.
- 현재 프로세스에 해당하는 Process 객체를 반환합니다.
- mp.parent_process() 도 있다.
- proc.name / proc.pid
- pid는 OS가 각 프로세스에게 부여한 고유 번호로써, 프로세스의 우선 순위를 조정하거나 종료하는 등 다양한 용도로 사용됩니다.
- mp.set_start_method('__')
- 'spawn'
- 상위 프로세스는 새로운 파이썬 인터프리터 프로세스를 시작한다.
- 하위 프로세스는 프로세스 개체의 run() 메서드를 실행하는 데 필요한 리소스만 상속합니다.
- 특히 상위 프로세스의 불필요한 파일 설명자 및 핸들은 상속되지 않습니다.
- 이 방법을 사용하여 프로세스를 시작하는 것은 포크 또는 포크 서버를 사용하는 것에 비해 다소 느립니다.
- 유닉스 및 윈도우에서 사용 가능합니다. 윈도우와 macOS의 기본값.
- 부모 프로세스가 OS에 요청하여 Child process를 새로 만들어내는 것을 spawning 이라고 부릅니다.
- fork
- 부모 프로세스는 os.fork() 를 사용하여 파이썬 인터프리터를 포크 합니다.
- 자식 프로세스는, 시작될 때, 부모 프로세스와 실질적으로 같습니다.
- 부모의 모든 자원이 자식 프로세스에 의해 상속됩니다.
- 다중 스레드 프로세스를 안전하게 포크 하기 어렵다는 점에 주의하십시오.
- 유닉스에서만 사용 가능합니다. 유닉스의 기본값.
- frokserver
- 프로그램이 시작되고 forkserver 시작 방법을 선택하면, 서버 프로세스가 시작됩니다.
- 그 이후부터, 새로운 프로세스가 필요할 때마다, 부모 프로세스는 서버에 연결하여 새로운 프로세스를 포크 하도록 요청합니다.
- 포크 서버 프로세스는 단일 스레드이므로 os.fork() 를 사용하는 것이 안전합니다.
- 불필요한 자원은 상속되지 않습니다.
- 유닉스 파이프를 통해 파일 기술자를 전달할 수 있는 유닉스 플랫폼에서 사용할 수 있습니다.
- 'spawn'
import time
from multiprocessing import Pool
def count(process_name):
for i in range(1, 100001):
print(process_name, i)
if __name__=="__main__":
start_time = time.time()
p_list = ["proc_1", "proc_2", "proc_3", "proc_4"]
pool = Pool(processes = 4)
pool.map(count, p_list)
pool.close()
pool.join()
print(time.time() - start_time)- from multiprocessing import pool
- pool = Pool(processes=4)
- pool 의 장점
- 요청이 올 때마다 생성하는 것보다, 생성 시간 비용을 줄일 수 있다.
- process의 총량을 관리할 수 있습니다.
- task의 생성과, task의 실행을 분리할 수 있습니다.
- 작업을 제출할 수 있는 작업자 프로세스 풀을 제어하는 프로세스 풀 객체.
- 제한 시간과 콜백을 사용하는 비동기 결과를 지원하고 병렬 map 구현을 제공합니다.
- processes 는 사용할 작업자 프로세스 수입니다.
- processes 가 None 이면 os.cpu_count() 에 의해 반환되는 수가 사용됩니다.
- with문을 pool과 함꼐 사용하면, enter 엔 Pool이 생성되고, exit 엔 terminate()가 호출됩니다. - initializer 가 None 이 아니면, 각 작업자 프로세스는 시작할 때 initializer(*initargs) 를 호출합니다.
- pool 의 장점
- pool.apply_async(func[, args[, kwds[, callback[, error_callback]]]])
- 인자 args 및 키워드 인자 kwds 를 사용하여 func 를 호출합니다.
- get()을 호출하여 결과물을 받기 위해선, 그 작업이 끝날 때까지 기다려야 한다.
- AsyncResult 를 반환합니다.
- pool = Pool(processes=4)
from multiprocessing import Pool
import multiprocessing as mp
import time
import os
def func(num):
c_proc = mp.current_process()
print("Running on Process",c_proc.name,"PID",c_proc.pid)
time.sleep(1)
print("Ended",num,"Process",c_proc.name)
return num
if __name__ == '__main__':
p = Pool(4)
start = time.time()
ret1 = p.apply_async(func,(1,))
ret2 = p.apply_async(func,(2,))
ret3 = p.apply_async(func,(3,))
ret4 = p.apply_async(func,(4,))
ret5 = p.apply_async(func,(5,))
print(ret1.get(),ret2.get(),ret3.get(),ret4.get(),ret5.get())
delta_t = time.time()-start
print("Time :",delta_t)
p.close()
p.join()-
-
pool.map_async(unc, iterable[, chunksize[, callback[, error_callback]]])
- map_async()도 apply_async()와 동일하게 AsyncResult를 반환받는다.
- map은 작업이 끝나기 이전에 메인 프로세스의 다음 줄의 코드들을 실행할 수 없지만, map_async()는 AsyncResult의 get()을 호출하기 이전까지는 작업이 완전히 끝나지 않아도 메인프로세스의 다음 코드들을 실행할 수 있다.
- 하지만 하나의 iterable 인자만 지원합니다, 여러 이터러블에 대해서는 starmap_async()을 참조하십시오.
-
pool.AsyncResult
- Pool.apply_async()와 Pool.map_async() 에 의해 반환되는 결과의 클래스.
- get([timeout])
- 결과가 도착할 때 반환합니다.
- timeout 이 None 이 아니고 결과가 timeout 초 내에 도착하지 않으면 multiprocessing.TimeoutError 가 발생합니다.
- wait([timeout])
- 결과가 사용 가능할 때까지 또는 timeout 초가 지날 때까지 기다립니다.
- ready()
- 호출이 완료했는지를 돌려줍니다.
- successful()
- 예외를 발생시키지 않고 호출이 완료되었는지를 돌려줍니다.
- 결과가 준비되지 않았으면 ValueError 를 발생시킵니다.
-
from multiprocessing import Pool
import multiprocessing as mp
import time
import os
def func(num):
c_proc = mp.current_process()
print("Running on Process",c_proc.name,"PID",c_proc.pid)
time.sleep(1)
print("Ended",num,"Process",c_proc.name)
return num
if __name__ == '__main__':
p = Pool(4)
start = time.time()
ret = p.map_async(func,[1,2,3,4,5])
print("is 'ret' ready? :",ret.ready())
print(ret.get())
delta_t = time.time() - start
print("Time :",delta_t)
p.close()
p.join()- callback은 어떻게 써? (apply_async, map_async에서)
from multiprocessing import Pool
import multiprocessing as mp
import time
import os
def callback_func(result):
print("callback_func got result :",result)
def square(x):
return x*x
if __name__ == '__main__':
with Pool(4) as p:
result = p.map_async(square,range(11),callback=callback_func)
result.wait()
callback_func got result : [0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100]- pool.close()
- 더는 작업이 풀에 제출되지 않도록 합니다.
- 모든 작업이 완료되면 작업자 프로세스가 종료됩니다.
- pool.terminate()
- 계류 중인 작업을 완료하지 않고 즉시 작업자 프로세스를 중지합니다.
- pool.join()
- 작업자 프로세스가 종료될 때까지 기다립니다.
- join() 호출 전에 반드시 close() 나 terminate()를 호출해야합니다 .
4. multiprocessing.pool VS concurrent.futures.ProcessPoolExecutor
4.1. multiprocessing.pool
- 후자와 다르게, task를 취소할 능력이 없다.
- 후자와 다르게, 다른 종류의 tasks 조합과 함께 일할 능력이 없다.
- 후자와 다르게, 모든 tasks를 강제로 종료할 능력을 가지고 있다.
- 후자와 다르게, task에서 발생할 수 있는 예외에 접근할 수 있는 능력이 없다.
4.2. concurrent.futures.ProcessPoolExecutor
- 전자와 다르게, task를 취소할 능력이 있다.
- 전자와 다르게, 다른 종류의 tasks 조합과 함께 일할 능력이 있다.
- 전자와 다르게, 모든 tasks를 강제로 종료할 능력이 없다.
- 전자와 다르게, task에서 발생할 수 있는 예외에 접근할 능력이 있다.
5. Inter Process Communication(IPC)
5.1. multiprocessing.Manager()
5.2. multiprocessing.Queue([maxsize])
-
언제쓰는가?
- native python objects를 쓸 때 가장 흔하고 단순하게 쓴다.
- 왜냐하면 전송 전에 패키지화 되고, 전송 후에는 unpackage화 되기 때문이다.
- 여러 생산자와 소비자를 쓰고 싶으면(two points 이상으로 의사소통 하고 싶으면) 써라.
-
파이프와 몇 개의 록/세마포어를 사용하여 구현된 프로세스 공유 큐를 반환합니다.
-
프로세스가 처음으로 항목을 큐에 넣으면 버퍼에서 파이프로 객체를 전송하는 피더 스레드가 시작됩니다.
-
제한 시간 초과를 알리기 위해 표준 라이브러리의 queue 모듈에서 정의되는 queue.Empty 와 queue.Full 예외를 일으킵니다.
-
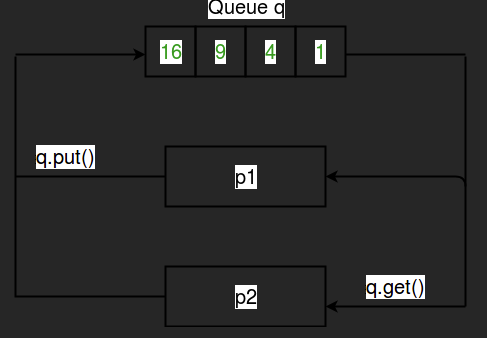
-
Queue.put()
-
Queue.get()
from multiprocessing import Process, Queue
sentinel = -1
def creator(data, q):
// Creates data to be consumed and waits for the consumer
// to finish processing
print('Creating data and putting it on the queue')
for item in data:
q.put(item)
def my_consumer(q):
// Consumes some data and works on it
// In this case, all it does is double the input
while True:
data = q.get()
print('data found to be processed: {}'.format(data))
processed = data * 2
print(processed)
if data is sentinel:
break
if __name__ == '__main__':
q = Queue()
data = [5, 10, 13, -1]
process_one = Process(target=creator, args=(data, q))
process_two = Process(target=my_consumer, args=(q,))
process_one.start()
process_two.start()
q.close()
q.join_thread()
process_one.join()
process_two.join()- Queue.cancel_join_thread()
- 기본적으로, multiprocessing.Queue 객체를 만들 때는 join_thread 파라미터가 True로 설정
- 이는 큐 객체가 소멸될 때 큐를 처리하는 스레드가 종료될 때까지 기다리는 것을 의미
- cancel_join_thread() 메서드를 사용하면 프로그램 종료시 더 빠른 종료가 가능해지며, 대신에 큐가 처리되지 않을 수 있다는 점을 유의해야 합니다.
5.3. multiprocessing.Pipe([duplex])
- 언제 쓰는가?
- python과 다른 언어 간에 공유하는 경우 protocol buffer + pipe를 사용하거나, Redis를 사용할 수 있다.
- 2 endpoints 로 충분하면 써라. 왜냐면 pipe가 queue 보다 훨씬 빠르기 때문이다. (Queue는 Pipe를 기반으로 만들어졌다.)
- 파이프의 끝을 나타내는 Connection 객체 쌍 (conn1, conn2) 를 반환합니다.
- duplex 가 True (기본값) 면 파이프는 양방향입니다.
- duplex 가 False 인 경우 파이프는 단방향입니다.
- conn1 은 메시지를 받는 데에만 사용할 수 있고, conn2 는 메시지를 보낼 때만 사용할 수 있습니다.
- 메서드 종류
poll(timeout=None)- 파이프로부터 데이터를 수신할 준비가 되었는지 확인합니다.
- 이 메서드는 파이프에 새로운 데이터가 도착하면 True를 반환하고, 그렇지 않으면 False를 반환합니다.
- blocking 되지 않음
- timeout은 초 단위, None일 경우 무한 대기.
recv(buffersize=None, flags=0)- recv() 메서드는 파이프로부터 데이터를 수신합니다.
- 이 메서드는 데이터가 도착하기 전까지 블로킹됩니다.
- 따라서, poll() 메서드를 사용하여 데이터 수신 준비가 된 상태인지 확인한 후, recv() 메서드를 호출해야 합니다.
- 이 메서드는 기본적으로 파이프에서 데이터를 읽을 때까지 대기합니다.
- 만약 파이프에서 데이터를 읽을 때 예외가 발생하면 EOFError를 발생시킵니다.
- buffersize
- 수신할 데이터의 최대 크기, None = 버퍼 크기 제한 x
- flags: 수신할 데이터에 대한 flag 지정.
send(obj, timeout=None, bufsize=-1)- send() 메서드는 파이프를 통해 데이터를 송신합니다.
- 이 메서드는 기본적으로 파이프가 가득 찰 때까지 블로킹됩니다.
- 따라서, 데이터를 전송하기 전에 파이프의 버퍼 크기를 확인하고, 버퍼에 충분한 공간이 있는지 먼저 확인하는 것이 좋습니다.
- send() 메서드는 파이프 객체에 직렬화되지 않은 객체를 전송할 수 있으며, multiprocessing 모듈 내에서 객체를 직렬화하고 전송하는 과정은 자동으로 처리됩니다.
- parameter
- obj
- 전송할 객체입니다.
- 이 객체는 파이프에 저장될 때 자동으로 직렬화됩니다.
- timeout
- 파이프가 가득 찬 경우 블로킹될 때 대기할 시간을 지정합니다.
- 이 값은 초 단위로 지정하며, 기본값은 None입니다.
- None일 경우 무한대기를 의미합니다.
- bufsize
- 객체를 전송할 때 사용되는 버퍼의 크기를 지정합니다.
- 이 값은 바이트 단위로 지정하며, 기본값은 -1입니다.
- -1일 경우, 시스템의 기본 버퍼 크기를 사용합니다.
- obj
from multiprocessing import Process, Pipe, current_process
import time
import os
# 실행 함수
def worker(id, baseNum, conn):
process_id = os.getpid()
process_name = current_process().name
# 누적
sub_total = 0
# 계산
for _ in range(baseNum):
sub_total += 1
# Produce
conn.send(sub_total)
conn.close()
# 정보 출력
print(f"Process ID: {process_id}, Process Name: {process_name}")
print(f"*** Result : {sub_total}")
def main():
# 부모 프로세스 아이디
parent_process_id = os.getpid()
# 출력
print(f"Parent process ID {parent_process_id}")
# 시작 시간
start_time = time.time()
# Pipe 선언, 리턴이 2개이며, 부모/자식에게 할당
parent_conn, child_conn = Pipe()
# 프로세스 생성 및 실행
# 생성
# t = Process(name=str(1).zfill(2), target=worker, args=(1, 100000000, child_conn))
t = Process(target=worker, args=(1, 100000000, child_conn))
# 시작
t.start()
# Join
t.join()
# 순수 계산 시간
print("--- %s seconds ---" % (time.time() - start_time))
print()
print("Main-Processing : {}".format(parent_conn.recv()))
print("Main-Processing Done!")
if __name__ == "__main__":
main()5.4. SharedMemory(name=None, create=False, size=0)
5.5. Event

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.