Reinforcement Learned Distributed Multi-Robot Navigation with Reciprocal Velocity Obstacle Shaped Rewards
human avoidance
목록 보기
1/7
사전 필요 지식
VO / 상호 작용 속도 장애물(RVO)의 개념: https://velog.io/@jk01019/Velocity-ObstacleVO
이 글을 통해, 알 수 있는 것
- Decentralized Mutli Robots 들이 제한된 정보 내에서, 서로 회피를 잘 하기 위한 알고리즘.
- 상호 작용 속도 장애물(RVO) 개념과 심층 강화 학습(DRL)을 결합한 접근법
"RVO 영역 및 예상 충돌 시간(TTC)" 기반 보상 함수의 개념
- 하지만, 이 논문의 접근법은, 아래의 것들을 추가적으로 알아야 합니다. (network input을 구성하기 위해, 알아야 합니다.) (decentralized라고 하기엔, 통신이 필요해 보이는 방법론입니다.)
- 상대 agent의 현재 속도 (상대 agent와의 time to collision)
- 상대 agent의 크기
abstract
- 논문의 목표
제한된 주변 정보 하에서 상호 충돌 회피 주행을 달성
- 논문의 기여 3가지는 아래와 같음.
- (1)
주변 로봇과 장애물의 정보를 RVO 및 VO 벡터로 각각 표현하여 (장애물과의 상호 작용 환경을 표현하는) 통일된 environment state representation을 달성(network input으로 쓰임) - (2) "주변 장애물의 다양한 수의 state"를 직접 action으로 매핑하는 -> bidirectional recurrent module based neural network 개발
- 변화하는 수의 주변 로봇에도 하나의 네트워크로 처리 가능.
- (3) 상호 충돌 회피 행동을 촉진하고, 충돌 위험과 이동 시간 간의 균형을 맞추기 위해 "RVO/VO 영역 및 예상 충돌 시간(TTC) 기반 보상 함수" 개발.
- (1)
- 소스 코드: https://github.com/hanruihua/rl_rvo_nav
Introduction
- 일반적으로, 다중 로봇 항법 시스템에는
중앙 집중식과분산식 방법의 두 가지 유형 로봇의 수가 증가함에 따라 중앙 집중식 시스템은 더 많은 계산 예산이 필요하며,각 개별 로봇과 중앙 제어기 사이의 신호 지연이나 불안정성으로 인해 문제가 발생할 수도 있습니다.- 그러므로, decentralized 방법으로 문제 범위를 좁힙니다.
2. Related Work
velocity obstacle
비홀로노믹 ORCA(Non-Holonomic ORCA, NH-ORCA)는ORCA와 운동 모델을 결합하여 비홀로노믹 제약 조건 하에서 ORCA 성능을 보장합니다.- 그러나 완벽한 감지 가정은 이러한 접근법들의 실제 세계 응용에서의 성능을 제한합니다.
- 따라서, 일부 접근법들은 로봇의 위치와 제어에서의 불확실성을 고려하기 위해, 로봇의 충돌 반경을 증가시키면서 VO 기반 방법을 로봇 운동 제약 조건과 결합합니다.
- 다른 접근법들은
가우스 불확실성을 극복하기 위해 RVO의 확률적 변형(PRVO)을 제안합니다. - 그럼에도 불구하고, 대부분의 이러한 VO 기반 접근법들은 지나치게 보수적이어서 필연적으로 항해 효율성을 감소시킵니다.
딥 강화 학습
- 다른 한편으로, 딥 강화 학습(DRL) 기반 충돌 회피 접근법은 많은 수의 훈련 경험을 고려할 수 있으며, 복잡한 시나리오를 효율적이고 견고하게 다루는 데 유리합니다.
- 일부 접근법은 원시 센서 데이터를 로봇 제어 벡터에 매핑하는 원시 센서 수준의 충돌 회피 정책에 초점을 맞춥니다.
- 원시 센서 수준 방법과 비교하여,
에이전트 수준 DRL 접근법은 원시 센서 데이터가 아닌환경 모델을 사용하여 센서 모드와 운동/동적 세부 정보에 대한 높은 계산 효율성과 유연성을 달성 - 이 논문에서는
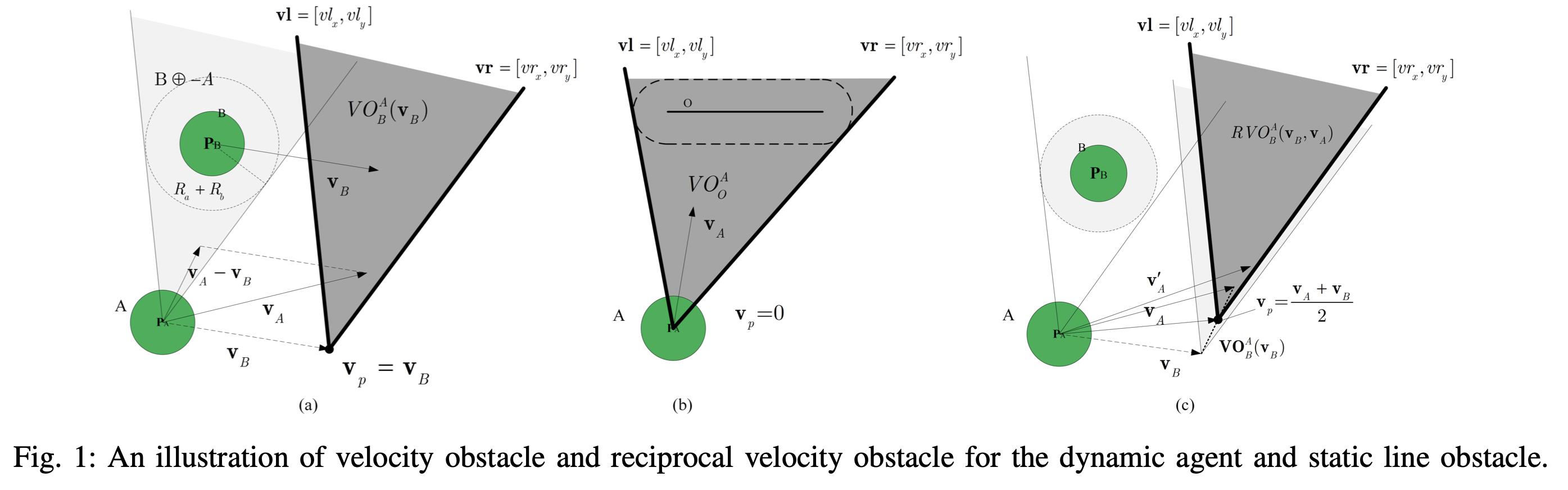
로봇의 위치와 속도 대신 RVO 벡터를 입력으로 사용합니다.- 이는 로봇 간의 상호 충돌 상호 작용을 더 잘 설명하고, 다양한 형태의 장애물을 모델링할 수 있습니다.
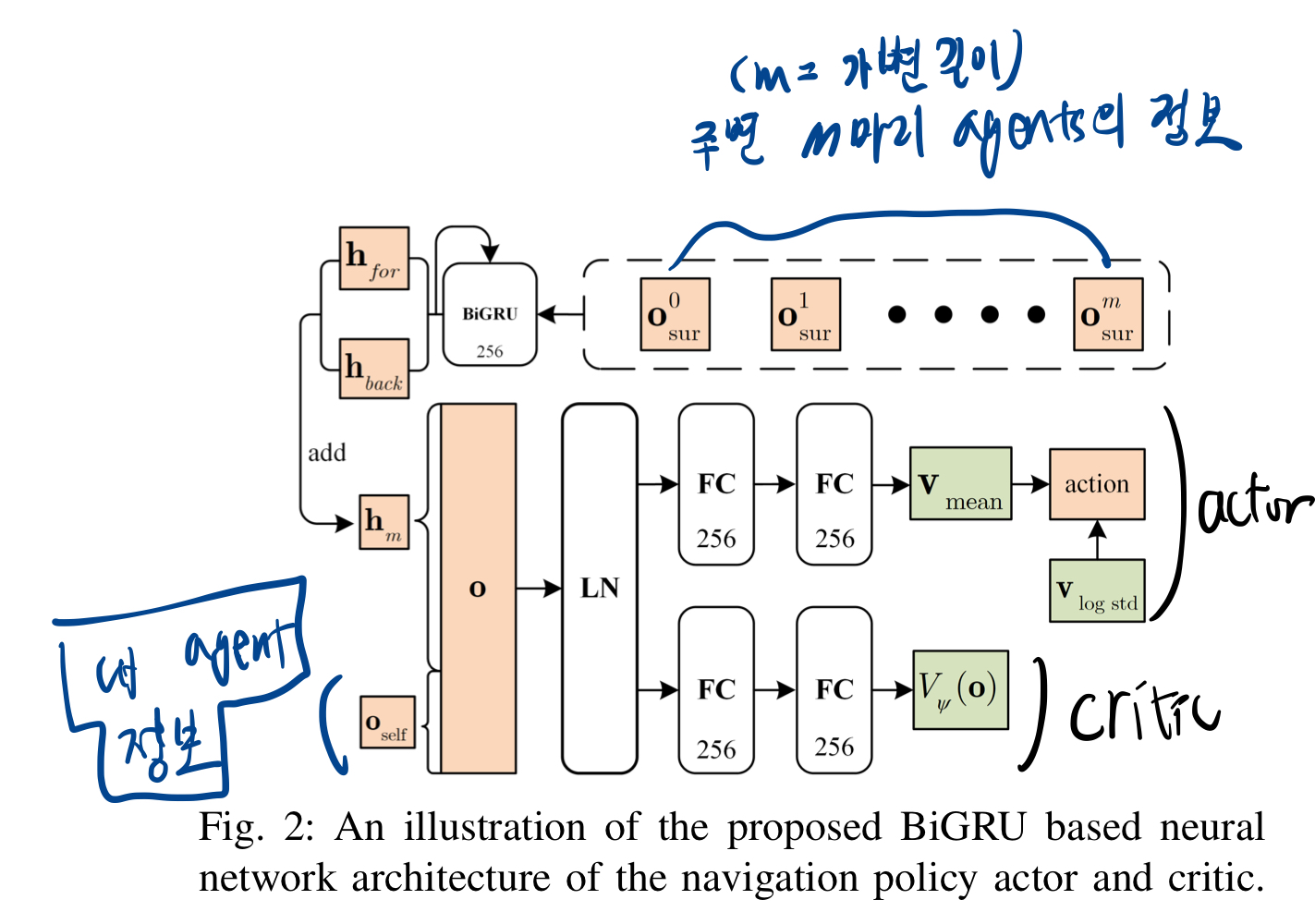
양방향 GRU 기반 신경망은 주변 로봇의 수가 변하는 상태를 직접적으로 연속적인 행동으로 매핑하도록 설계되어 저비용 계산을 달성
3. 시스템 설정 및 문제 진술
A. 시스템 프레임워크
- 각 로봇은 다른 로봇과 통신하지 않지만, 일정 범위 내의 주변 로봇을 감지할 수 있습니다.
내 로봇에 대한 정보에는 로봇 반경, 현재 속도, 현재 방향 및 원하는 속도가 포함- 원하는 속도는 로봇이 장애물을 고려하지 않고, 현재 위치에서 목표까지 직접 이동하기 위한 최대 속도
- 마찬가지로,
주변 로봇의 정보는 로봇 반경, 상대 위치 및 속도로 구성되며,이는 RVO 벡터를 통해 나타낼 수 있습니다. - 또한,
정적 선 장애물도 VO 벡터를 통해 나타낼 수 있습니다.이러한 벡터는 충돌 회피 정책을 훈련하기 위해 신경망에 공급됩니다. 현재 속도에서의 VO 영역과 예상 충돌 시간을 기반으로 상태와 행동을 평가하는 데 도움이 되는 보상 함수가 설계되었습니다.- PPO 알고리즘을 사용
- 대부분의 RL 기반 접근법의 정책 출력이 직접적으로 로봇의 제어 벡터인 반면, 우리 접근법의
출력은 각 시간 단계에서현재 속도의 증분, 즉 현재 속도의 변화율입니다. - 이를 통해 더 부드럽고 효율적인 로봇 제어를 달성할 수 있습니다.
Problem Statement
Ego input
기존
- lscan
- relative waypoints
- 현재 속도
- cmd_ctr
- prev_actions
논문에서 추가한 것
- 방향,
최고 목표 속도,충돌회피를 위한 가상 반지름 길이(로봇 크기)
Others input
기존
- 다른 agents들의 상대 위치 정보
논문에서 추가한 것
다른 동적 agents와의 RVO (상대 agent의 속도를 추가한 개념)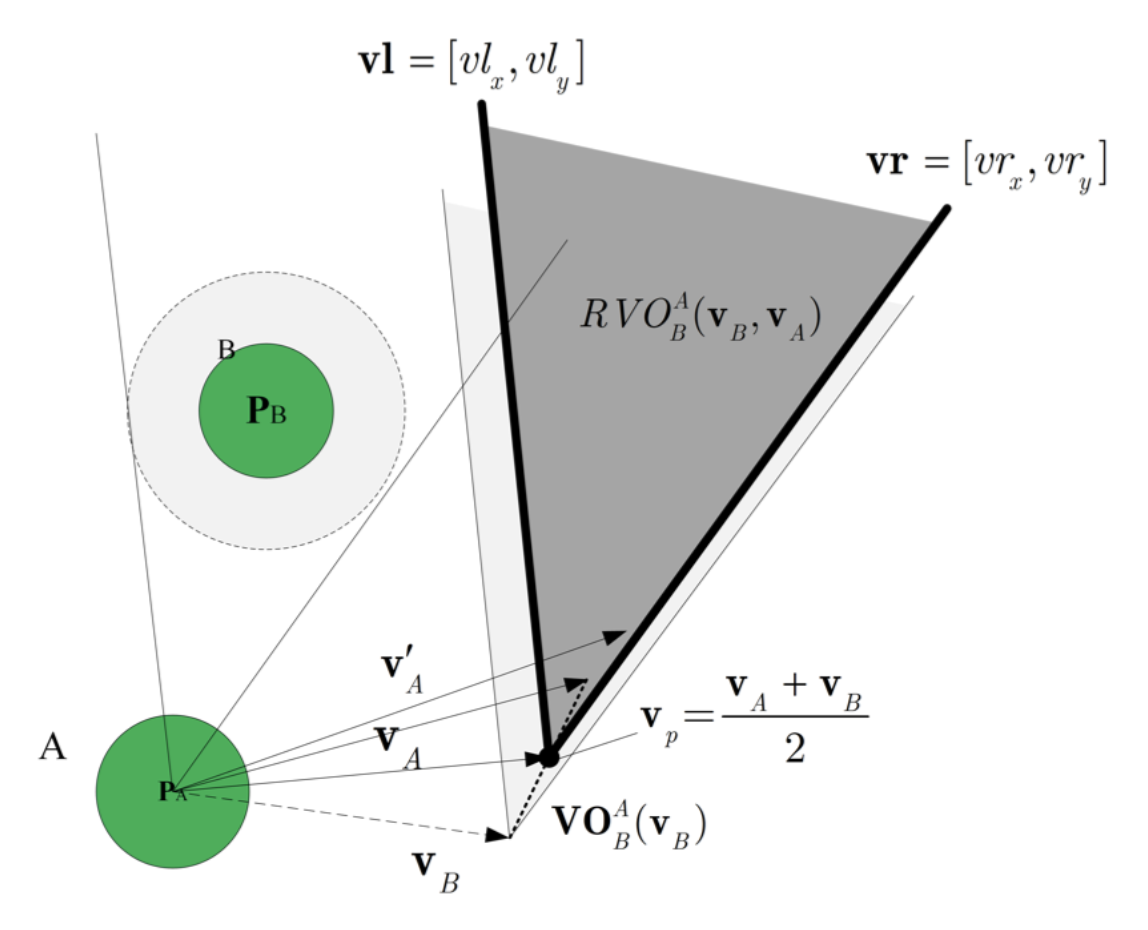
- apex coordinate: 2차원
- vl: 2차원
- vr: 2차원
- 다른 agent와의 상대 거리
- 이것까지 추가하면, 기존
다른 agents들의 상대 위치 정보는 빼도 됨.
- 이것까지 추가하면, 기존
다른 동적 agent와의 TTC(상대 agent의 속도를 추가한 개념)- TTC를 넣으면 무한대인 경우도 있으므로, 수학적 안정성을 위해 1/(TTC+0.2)를 넣었다.
4. Reinforcement Learning Framework
Neural Network Architecture
Reward Function
- 컨셉
- 위험조건: 조건 1 or 조건 2
- 조건 1: 로봇 속도 벡터가 다른 동적장애물들의 RVOs 공간에 포함되고, 동적장애물들과의 최소 TTC가 기준 이하
- 조건 2: lscan과의 최소TTC가 기준 이하
- 안전조건: 위험조건이 아닌 경우
- 위험조건인 경우, TTC기반 penalty를 적용하고, 안전조건인 경우는, 목표 속도와의 근접성으로 reward를 준다.
- 위험조건: 조건 1 or 조건 2


새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.