- RLHF는 강화 학습을 이용하여 인간의 피드백을 통해 언어 모델의 출력을 사람이 원하는 방식에 가깝도록 학습하는 과정
1. RLHF의 과정 및 구성 요소
1.1. 초기 언어 모델 학습
- 먼저, 대규모 텍스트 데이터를 사용하여 초기 언어 모델을 사전 학습
- 이 모델은 다양한 입력 프롬프트에 대한 응답을 생성할 수 있습니다.
1.2. 인간 피드백 수집
모델이 생성한 여러 응답 중에서 인간이 선호하는 응답을 선택하고 이를 평가- 예를 들어, 모델이 하나의 질문에 대해 여러 응답을 생성하면, 인간 평가자가 각 응답의 질을 순위 매기거나 점수를 부여
1.3. 보상 모델 학습
- 인간의 피드백을 바탕으로 보상 모델을 학습시킴
- 보상 모델은
입력 프롬프트와 생성된 응답의 쌍을 받아들여,각 응답에 대한 보상 점수를 예측 - 이는 인간 평가자의 선호도를 반영한 점수입니다.
1.4. 강화 학습
보상 모델의 점수를 기반으로 -> 초기 언어 모델을 강화 학습- 강화 학습을 통해
언어 모델의 가중치가 조정되며, 이는 모델이 더 바람직한 응답을 생성할 수 있도록 합니다.
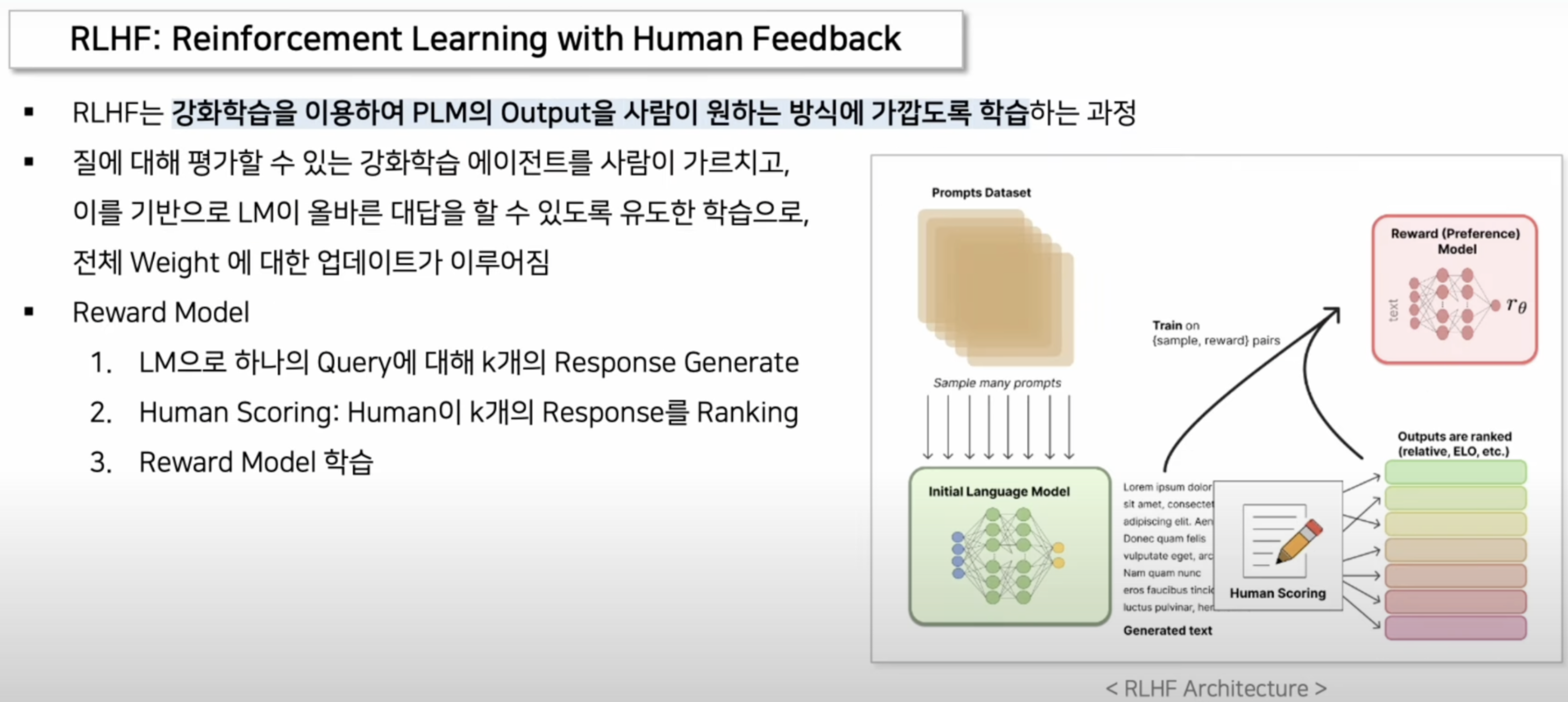
- PLM은 Pre-trained Language Model의 약자
2. 그림 설명
그림 요약:
- Prompts Dataset: 다양한 입력 프롬프트가 포함된 데이터셋.
- Initial Language Model: 초기 학습된 언어 모델이 입력 프롬프트에 대해 여러 응답을 생성합니다.
- Human Scoring: 인간 평가자가 각 응답을 평가하여 순위를 매깁니다.
Reward Model:
- 인간의 평가를 바탕으로 보상 모델이 학습됩니다.
- input
- Query: 모델이 응답해야 하는 입력 질문 또는 프롬프트입니다.
- Response: 모델이 생성한 여러 개(Query당 k개의) 응답들입니다. 각 응답은 동일한 Query에 대한 것입니다.
- Output
- Reward Score: 각 응답에 대해 보상 점수를 출력합니다. 이 점수는 응답의 질을 평가한 결과입니다.
- 점수는 인간 평가자가 각 응답에 대해 매긴 순위 또는 점수를 기반으로 합니다.
- ELO 시스템 적용:
- 각 응답을 "플레이어"로 간주하고, 두 응답 간의 상대적인 우열을 평가합니다.
- 인간 평가자는 두 응답을 비교하여 더 나은 응답을 선택합니다.
- 선택된 응답은 ELO 점수가 상승하고, 선택되지 않은 응답은 점수가 하락합니다.
Training
- Training: 보상 모델을 사용하여 초기 언어 모델을 강화 학습으로 업데이트합니다.
2.1. RLHF의 장점과 단점
장점:
- 향상된 응답 품질: 모델이 인간의 선호도를 반영하여 더 자연스럽고 유용한 응답을 생성할 수 있습니다.
- 감소된 Hallucination: 실제로 존재하지 않는 정보를 생성하는 문제를 줄일 수 있습니다.
단점:
- 비용과 시간: 인간 평가자를 통해 피드백을 수집하고 이를 반영하는 과정은 비용이 많이 들고 시간이 오래 걸릴 수 있습니다.
- 피드백 편향: 인간 평가자의 주관적인 판단이 모델에 반영될 수 있습니다.
2.2. 추가 정보
- RLHF는 자연어 처리 및 대화형 AI에서 매우 중요한 기술로, 사용자 경험을 향상시키고 더 신뢰할 수 있는 모델을 만드는 데 기여
- 이는 OpenAI의 GPT 모델을 포함한 여러 최신 언어 모델에서 채택되고 있는 방법론입니다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.