개요
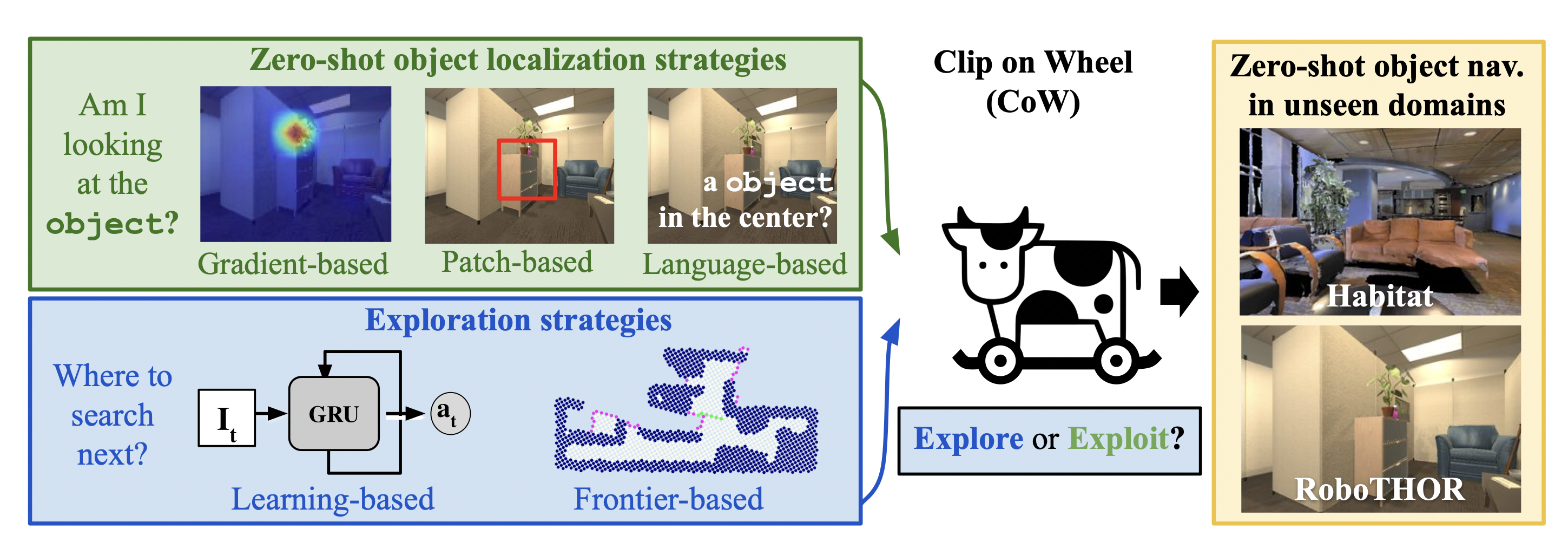
- CLIP on Wheels
- https://arxiv.org/pdf/2203.10421v1.pdf
- 언어로 말한 물체를 로봇이 찾기 위해, CLIP과 GradCAM을 활용하여 대상 카테고리에 대한 살리언시 맵을 구축하는 방법론
- CLIP 모델을 사용함으로써, CoW는 주어진 자연어 명령(예: "물병을 찾아라")을 분석하여 해당하는 시각적 대상을 이미지에서 식별
- GradCAM은 Convolutional Neural Networks(CNNs)의 중간 레이어에서 중요한 영역을 시각화하는 기술로,
- 모델이 특정 결정을 내리는 데 있어 중요한 이미지 영역을 강조
- CLIP와 결합될 때, GradCAM은 대상 카테고리에 대한 이미지 내의 관련 영역을 강조하는 살리언시(saliency) 맵을 생성
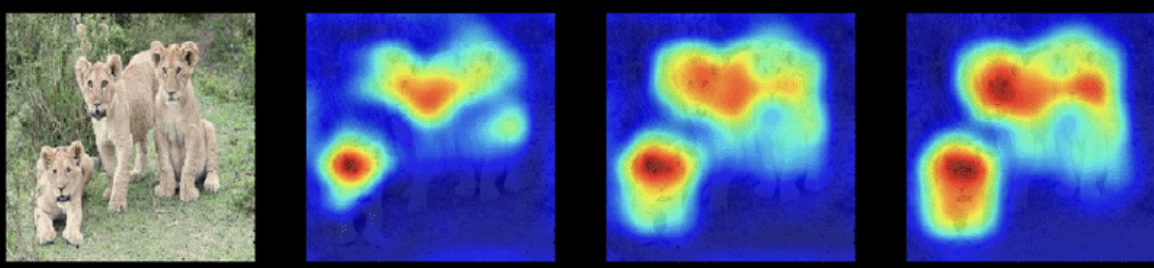
- CoW는 생성된 살리언시 맵에서 살리언시 값에 임계값을 적용하여 대상 객체 카테고리에 대한 분할 마스크를 추출 -> 이를 통해 객체의 정확한 위치를 파악
- 그 후, 이 위치 정보를 바탕으로 로봇이나 탐색 에이전트가 대상 객체까지의 경로를 계획할 수 있음
- 내가 가고자 하는 목적지가, 현재 센싱된 이미지에 있으면(CLIP을 통해 확인), salient map을 생성해서 추출한 목적지로 가고,
- 현재 센싱된 이미지에 없으면, 탐험을 계속합니다.

abstract
- Robot perception must handle a large variety of semantic objects without additional fine-tuning to be broadly applicable in homes.
- Recently, zero-shot models have demonstrated impressive performance in image classification of arbitrary objects.
- In this paper, we translate the success of zero-shot vision models (e.g., CLIP) to the popular embodied AI task of object navigation.
- In our setting, an agent must find an arbitrary goal object, specified via text, in unseen environments coming from different datasets.
- Our key insight is to modularize the task into zero-shot object localization and exploration.
- We find that a CoW, with CLIP-based object localization plus classical exploration, and no additional training, often outperforms learnable approaches in terms of success, efficiency, and robustness to dataset distribution shift.
기초 개념
- "Frontier"
- 탐색 과정에서 아직 탐색되지 않은 영역의 경계
- 로봇이나 탐색 에이전트가 환경을 지도화할 때, 이미 알려진 영역과 아직 알려지지 않은 영역 사이의 경계를 "프론티어"라고 합니다.
- 이 경계선은 에이전트가 다음으로 탐색해야 할 장소를 결정하는 데 사용되며, 보통은 미지의 영역으로의 확장을 위해 선택된다고 볼 수 있습니다.
- 프론티어 기반 탐색(Frontier-Based Exploration) 알고리즘에서는 이러한 프론티어를 중요한 결정 포인트로 사용하여 효율적인 탐색 경로를 계획

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.