Attention Is All You Need
- Rnn -> LSTM -> LSTM+Attention -> Only Attention(Transformer)로 변해왔고, Sequence의 불필요성을 알게되었고, Language는 sequence라는 고정관점을 깨게되었다.
-
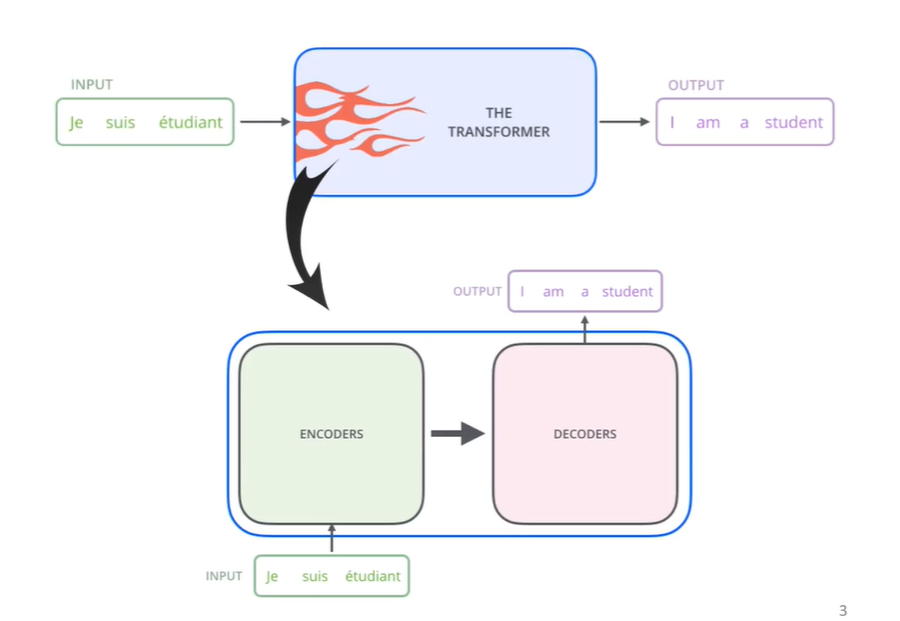
Transformer는 크게 Encoder파트와 Decoder파트로 나눠져있다. 보통, seq2seq의 모델을 encoder와 decoder을 이용한다고 볼 수 있다.
-
좀 더 자세히 살펴보면, 아래와 같다.
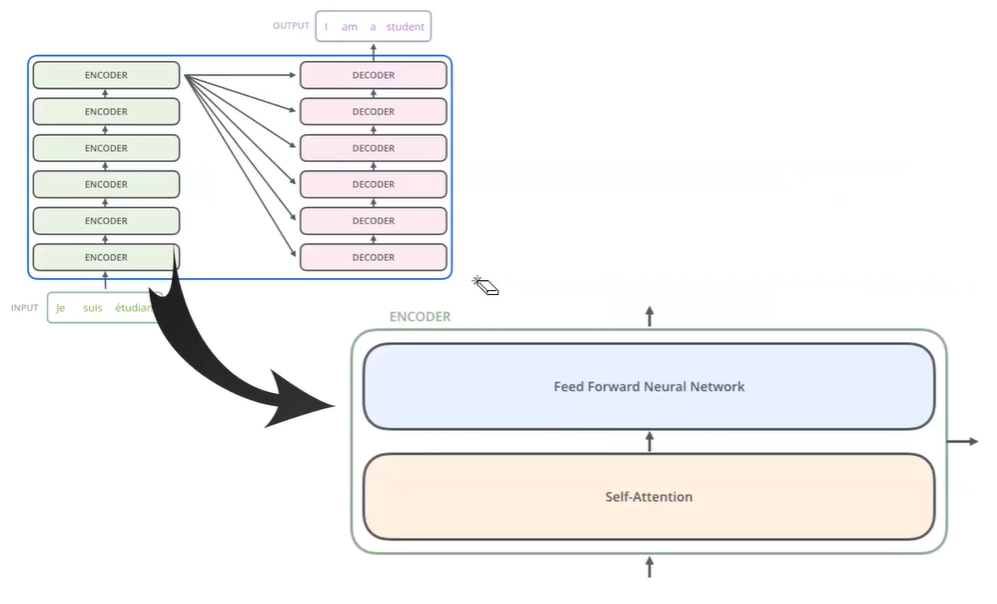
-
여러개의 Encoder와 여러개의 Decoder가 같은 개수로 존재한다. 또한 해당 Encoder는 Self-Attention과 Forward Network가 각각 존재한다.
Decoder는 Self-Attention, Encoder-Decoder Attention, Forward Network가 존재한다. -
단어 embedding으로는 512차원을 일반적으로 사용하여, 기존 LSTM의 capacity를 크게 늘려줬다.
Self-Attention
-
Self-Attention은 주변단어들을 고려한 target word representation 만들어주는 역할을 한다.
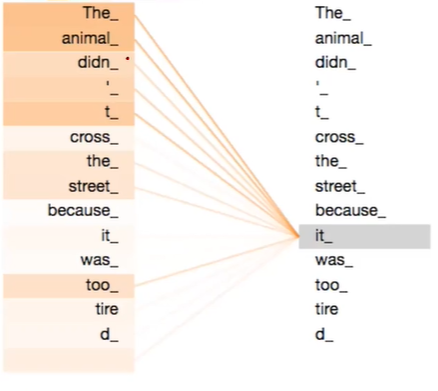
-
Self-Attention은 기존 word-embedding에서는 알수 없었던, It과 같은 대명사가 무엇을 가리키는지 알 수 있고, LSTM에 경우 It에 도달할때까지, 많은 noisy가 끼는데, Self-Attention은 로켓배송처럼 직접 가리키는 단어를 알 수 있다.
-
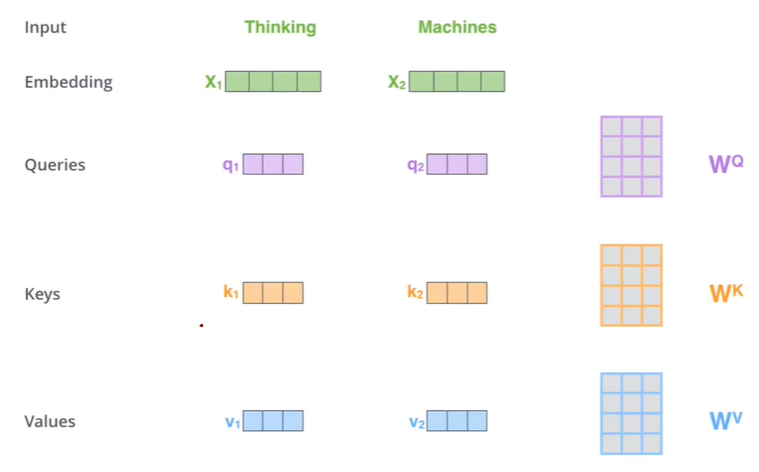
Self-Attention의 작동을 자세히 살펴보자.
우선 Embedding, Queries, keys, Values vector로 구성되어있고, 해당 Queries, Keys, Values는 각각의 Trainable parameter를 Embedding vector에 곱해줌으로써, 구할 수 있다.
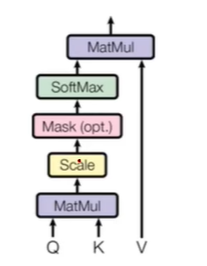
-
위와 같은 방식으로 matrix multiplication을 해주어, 학습 할 수 있다.
-
또한, 기존 LSTM과 같은 RNN embedding에서 대명사가 의마하는 다 다른 것을, Multi-head Attention을 이용하여 해당 문제를 해결해준다.
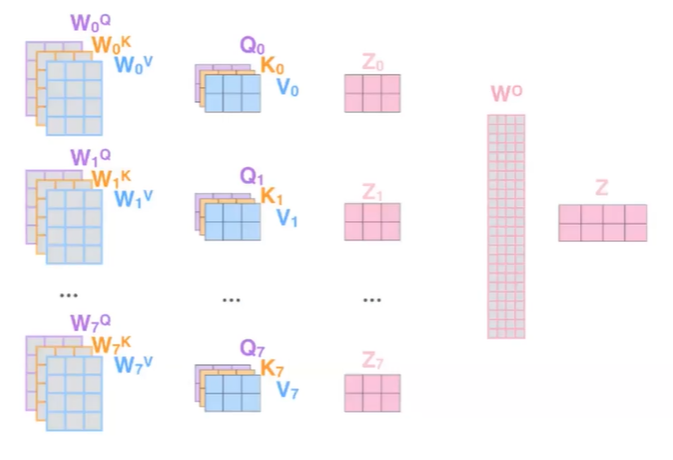
-
위와같이, 여러개의 Multi-head를 만들어주어, 해당 단어가 어떤 것을 의미하는지 나타내 줄 수 있다.
