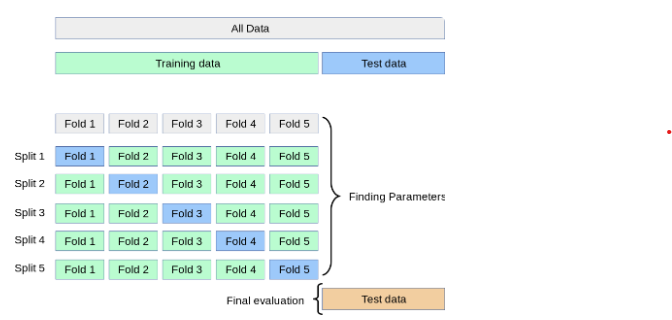
1. K-fold Cross Validation
-
구성요소
-
Split : k개의 폴드가 뭉쳐진 것
-
fold : 한 개의 Validation fold와 나머지 Train Folds
-
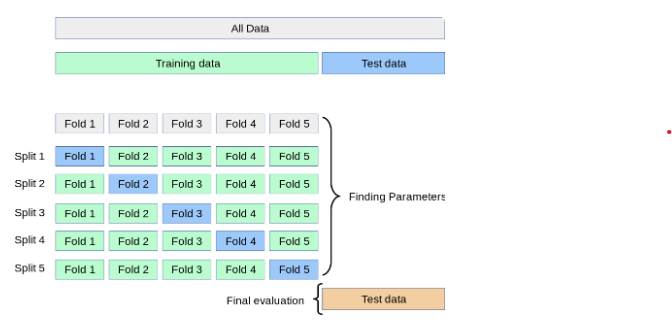
최종적으로는 K번 검증된(K개의 Split을 활용하여) 결과 값의 평균을 도출 !
1.1. Stratified Cross Validation
(공통점) : k-fold와 같이 k-1개의 Train과 1개의 Validation Fold를 이루지만
(차이점) : Fold별 클래스 비중을 모두 동일하게 진행한다는 차이점만 존재
데이터의 차원을 축소하기 위한 방법
-
변수 선택(Feature Selection)
- 주어진 많은 변수들 중 특정 기준에 따라, 혹은 주어진 태스크에 맞게 -
변수 추출(Feature Extraction)
2. PCA
PCA하면 보통 차원의 저주를 해결하기 위해 사용된다고 합니다. 하지만 ! 변수가 증가한다고 반드시 차원의 저주가 발생하는 것은 아니라고 하네요.
관측치보다 변수 수가 많아지는 경우에 차원의 저주 문제가 발생한다고합니다!
- 차원의 저주를 모른다면? [차원의 저주 정의]
차원이 증가하면서 학습데이터 수가 차원 수보다 적어져서 성능이 저하되는 현상을 일컫습니다. 차원이 증가할수록 변수가 증가하고, 개별 차원(예를 들어, 한 개의 컬럼 또는 Feature) 내에서 학습할 데이터 수가 적어진다.
- 변수 추출을 위해 사용
2-1. [Python] PCA 실습
- Sklearn 활용
from sklearn.decomposition import PCA
pca = PCA(n_components = 2)
X2D = pca.fit_transform(X)🧨일반화 성능이란?
학습에 사용하지 않은 데이터를 활용한 예측 성능을 의미

장난감이 데이터인 사람