
1. 대회 개요
2022 유플러스 AI Ground는, 캐릭터부터 교육용 콘텐츠까지 다양한 콘텐츠를 제공하는 유아-아동 전용 미디어 서비스 ‘아이들나라’의 AI Task 및 실제 사용자 데이터를 바탕으로, 새로운 추천 아이디어 및 프로필별 맞춤형 콘텐츠 추천 AI 모델을 개발하는 AI 경진대회 입니다.
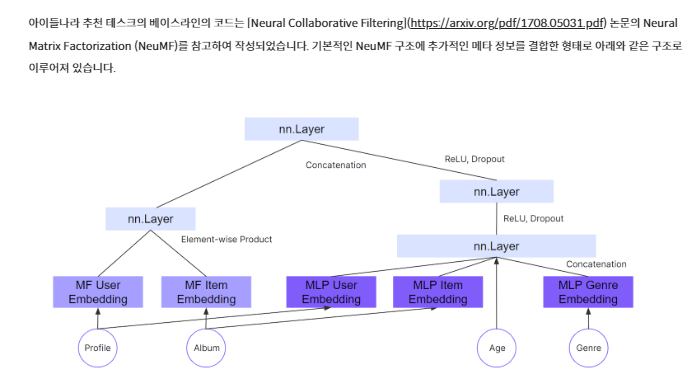
1-1. Baseline 코드(NMF)
1-2. 평가 지표
score = 평균 Recall@K 0.75 + 평균 NDCG@K 0.25 (K = 25)
1-3. 결과
658 팀 중 87등(PRIVATE)
2. 초반에 진도가 너무 지체된 이유
- Ranking Contest를 어떻게 진행해야 할 지 아무것도 모른 체, 대충 안다고 생각한 체로 10일 정도를 무지성으로 다른 Model들을 찾았고, 이를 적용했지만 당연히 문제점이 많았다. Negative Sampling 적용 불가한 점이 가장 컸다.
- Labeling을 진행하는 대회는 처음이라 이 부분은 정말 생각도 못했다. CatBoost Ranker Model을 사용하는데, 생각해보니 Label이 없었다. 모두 시청한 데이터로만 진행했기 때문에. Labeling에 대해서 시청한 Contents를 4등분으로 나눠서 Labeling을 진행했지만, 성능이 좋지 않았다.
→ 실제 Youtube 논문에 있어서는 시청 시간을 기준으로 모두 시청했으면 1, 아니라면 0으로 Labeling을 진행한 사실을 논문을 공부하면서 깨달았다.
- Model 선정의 우선순위(가설의 우선순위)에 있어서 역시 생각하지 못했다. 이러한 대회가 처음이여서 모델에 있어서도 우선순위를 정할 필요가 있다는 것을 깨달았다. 다음에 진행할 AI 대회에서는 모델의 우선순위를 선정하여 빠르게 가설을 검증할 것이다.
- DataFrame에 대해서 merge를 진행하면서 EDA를 함께 진행하였지만, FE위한 EDA는 막상 많이 하지 못한 것 같다.
→ 어떠한 식으로 FE를 진행해야 할지 가설을 세우지 않은 체로, 즉 목적성이 없는 EDA를 진행하였기 때문에 효과적인 EDA를 진행하지 못했던 것 같다.
Naver 부캠에서 진행한 대회와 큰 레벨 차이가 있는 대회임을 느꼈다. 비록, 현재 진행 중인 DKT에 시간 투자를 많이 안해서인지(?), 대회의 성적은 현재 좋지 않지만, 그것과 별개로 대회를 진행 하는 데 있어서 갈피를 잡을 수 없다라는 느낌을 받은 것이 처음이다.
물론, Ranking 대회도 처음이고, 일반 예측 대회가 아닌 딥 러닝을 활용한 대회 역시 처음이라 더욱이 그랬던 것 같다.
3. 대회 진행 과정
3-1. Data & Task 이해
Data와 Task에 대한 이해가 정말 중요한 대회임을 깨달았다.
특히, Task에 대한 이해를 제대로 하지 않고 진행하면 삽질을 엄청나게 하고 시간 낭비를 엄청할 수 있다라는 사실을 깨달았다.
- Data 이해: 크게 Profile, Contents, 그리고 시청 Data 3개의 부류로 나뉠 수 있다. 처음에는 이 모든 데이터를 사용해야만 하는 줄 알고 모든 DF를 merge를 진행했었다.
→ 이 부분에 있어서도 시간적인 소비가 컸다. Data에 대한 이해는 내가 진행하고자 하는 가설에 필요한 데이터들을 파악하는 과정이라 느꼈다. 즉, 모든 데이터를 건드리는 Bottom-up 방식 보다, 필요한 데이터들에 대해서 EDA와 FE를 진행하는 Top-down 방식이 중요함을 느꼈다.
- Task 이해: 이번 대회의 Task는 아이들이 어떤 컨텐츠를 시청할지 25개의 데이터를 기존에 주어진 데이터를 이용하여 추천 모델을 개발하는 것이다. 여기서, 중요한 것은 어떻게 25개의 데이터를 추천할 것인가?
→ 이 부분을 인지하지 않고, 진행하니 이제 마지막에 추천 아이템을 추출할 때 시청한 데이터가 1개인 사람들은 1개만 추천할 수 밖에 없는 모델의 구조를 짰었다.
Task에 대해서 어떻게 진행할지 알 수 있다. 다음 대회에는 확실히 인지하자.
3-2. Feature Engineering & 전처리
- train에 있어서 행을 필요한 Users들만 넣어서 진행
→ 원래는 matrix를 구성할 때 userID가 없는 index까지 포함됐는데, 실제 UserID만 slicing해줘서 진행하였음. 실제로 모델의 성능이 좋아졌음
- 총 점수 0.0016오르면서 96 → 48 등 까지 올라갔다.
- 그리고, Items 부분도 cold items들을 추가해주려했지만,
Nueral에 들어가는 genre feature에 있어서 cold items들의 정보를 모르기 때문에 진행하지 못함. 그래서, matrix를 baseline에서는 저렇게 구성한 것 같음.
→ 다른 Model을 사용한다고 한들 genre와 같은 다른 feature들은 못쓸 것 같음 ,,(즉, Cold start를 다른 feature로 해결할 수 없다는 뜻)
- 따라서, 최선은 matrix의 형태만 변형할 수 있음(Baseline기준 or AI Models). 이를 토대로 컨텐츠 기반 필터링(CBF)을 이용해서 유사도 feature를 만들어서 Embedding 적용하여 해결하거나 또는 모델링한 것들을 기반으로 concat를 하는 식으로 하려했지만, CBF는 적용했지만 Pretrain Embedding 및 Fine Tuning은 진행하지 못함.
3-3. 여러 가설 검증
✨가설 1 : 특정 개수 이하로 시청한 유저들에게 컨텐츠 기반 필터링 적용하여 추천
제목(자연어)에 기반해서 tf-idf (제목이 그래도 token으로 평균 5~7개는 돼보였다.) 통계적 기반 필요
현재 구축되어 있는 NMF 기반으로 나온 결과 값을 기준
1) 가장 높은 예측 값을 지닌 녀석과의 title tf-idf -> cosin 유사도를 적용해서 5개? 10개? 정도 앙상블
1-1. Contents Based Filtering(CBF)
- DF: title, cosine_similarity
- 목적: NMF에서 나온 첫 번째 값을 기준으로 5개, 10개 이렇게 뽑아서 결과 앙상블
- input : NMF의 User별 album_id 추천 리스트의 첫 번째 (album_id)
- modeling : 코사이 유사도 함수 돌리는 시간이 너무 오래걸려서 따로 모델 함수에서 빼서 변수로 할당하고 변수만 사용
CSW = cosine_similarity(wordmatrix)
def content_based_filtering_cosin(album_title_list: list,
wordmatrix: np.array,
title: str,
topn: Optional[int]=None) -> pd.DataFrame:
topn=11 if topn is None else topn+1
sim_matrix = pd.DataFrame(CSW, index=album_title_list, columns=album_title_list)
target_similarity_df = sim_matrix[title].reset_index().copy()
target_similarity_df.columns=['title', 'cosine_similarity']
return target_similarity_df.sort_values('cosine_similarity', ascending=False).reset_index(drop=True)[1:topn]-
How NMF 결과에서 title을 뽑아낼 것인가?
→ 결과 DF의 첫 번째 album_id -> 매핑돼있는 title 뽑아내서 적용
-
문제점
나온 리스트 -> title나옴 -> 이거를 어떻게 album_id로 뽑아내지 (Ensemble Algoritm 구현)
# top1 album_id의 title로 부터 유사도 top10 뽑아내기
# for 전체 User의 top1 뽑아내는 반복문
# get_list 적용 (함수 새로 setting)
def get_list(top1):
titles = content_based_filtering_cosin(album_title_list, wordmatrix, meta_df[meta_df['album_id'] == top1]['title'].values[0], 10)
# 배열로 만드는 이유는 df로 만들어서 merge하기 위해
album_list = []
final_list = []
# 해당 title의 album_id 추출
for title in titles:
# 중복되는 제목이 있기 때문에 indexing 해줘야함
V = meta_df[meta_df['title'] == 'title']['album_id'].values[0]
album_list.append(V)
final_list.append(album_list)
return final_list
# return 값을 받아서 list에 저장해주고 최종적으로 df로 만듦
'''
tmp = {0 : [[1,2,3]], 1: [[3,4,4]]}
pd.DataFrame(tmp)
'''
# 위에 설정 CBF_list (반복문 안)
CBF_list = []
CBF_list.append(get_list(top1))
# 최종 DF (반복문 끝)
pd.DataFrame(CBF_list)- 앨범 id 뽑아낸다해도 붙이고 중복 제거 해주고 다시 25개 슬라이싱 해줘야함. 일단,나중에 중복으로 사라질 album_id도 있으니까 5개를 하려고 해도 10개 정도 선별하기
1-2. Ranking Ensemble 방법
-
다른 모델의 예측 리스트가 포함된 df를 앙상블 하려는 df와 병합해준다.
-
병합 후, 두 예측 리스트 컬럼을 합쳐주는 과정이 필요하다. 지금까진 반복문 밖에 모르겠다. 대회끝나면 다른 코드 참고해야겠다. 반복문에서 리스트를 합쳐주고, set 형변환 후, 다시 list로 돌려준다.
-
최종적으로, submit 하기 위해 처음 두 모델의 예측리스트 컬럼을 삭제해주고 나머지 컬럼만 predicted_list로 컬럼명 변경해서 제출하면 끝!
1-3. CBF + NMF Methods
각 USer의 top1 album_id의 title을 기준으로 Content Based Filtering 진행해서 topk 선별하여 앙상블
-
시청 앨범 조금 있는 애들은 어떻게 해야 되지? (5개미만?)
-
전체 Users 대상으로 10개 합치기 (40%)
+) 이미지 데이터를 구해서 외부 데이터를 적용하여 CNN 계열 딥러닝을 섞으면 좋지 않을까
✨가설 2 : Cold-start만큼 모든 임베딩 늘리기
▶ 모델이 망가질 것 같다..
why? cold items들 사이에서 어떤 가중치를 줄 지 아니, 가중치를 매길 수 없다.
why? 다 똑같은 값들을 가질테니까. 단 하나의 feature 빼고(genre). 그래서, 지금 모델을 통체로 다 뜯어서 feature를 추가하면서 하기에는 시간 대비 cost가 너무 커서 시도하기 어렵다 판단. (확률도 굉장히 낮고)
✨가설 3 : 논문의 cold item 컨텐츠 추천(attention, knn 활용)기법 적용해보기
→ 적용해보지 못함
✨가설 4 : Rule Based 기반 11개 이하인 시청유저 -> 3천명 대상 (12//25 = 약 0.5%)을 기준으로 적용함
▶ 성능이 매우 안좋음 -> NMF 성능이 괜찮았다는 것 (특정 개수 이상의 시청자들에게)
✨가설 5 : Rule Based 기반 2개 이하인 시청유저에게만 대상으로 진행 Ensemble
▶ 성능이 기본 NMF 모델보다 좋지 않다. 이유는 .. 음.. 당연히 시청이 많은 순으로 top25를 선별했지만, 이 부분이 성능에 도움이 안된다는 것이겠지
→ 이 부분에 있어서도 빠르게 방향을 전환해서 다른 방식으로 가설을 진행하면 더 좋을 것이다.
4. Etc
4-1. Negative Sampling
Sampling 비율을 높이면서, 메모리 오류 발생
-
RuntimeError: CUDA out of memory 발생
→ 배치사이즈 줄임32 -
참고 블로그
https://heytech.tistory.com/354
→ Postive의 5~20배의 Negative Sampling이 성능이 좋음
4-2. Dropout
왜 이렇게 과적합이 나오는 걸까? negative sampling 기준으로 시청한 데이터의 100배로 뽑는데도 불구하고 과적합이 생긴다?(평균인 100개만 뽑아도 10100개인데..)
이건 데이터가 적어서 과적합이 된다기 보다는 다른 것이 문제가 있다. 그래서, 보니까 dropout이 0.05로 라는건 큰 과적합의 문제이지 않을까 했다. 그런데, 0.5로 해도 비슷한 추세다.
Baseline Dropout 기준이 0.05로 설정돼있는데 negative sampling 비율을 높게 잡아버릴까?
4-3. Embedding
크기 조절에 따라 성능 천차만별
컨텐츠 기반에 대한 임베딩
→ 임베딩의 크기 역시 중요하다.
😂대회 회고
- 논리에 입각해서 가설을 세우고, 실험을 진행했어야 했는데 '어 Nueral Net Part에 피쳐 더 추가하면 좋지 않을까?' 하고 여러번 기대하면서 진행했던 것이 시간적으로 많이 잡아먹어서 아쉬웠다. 하나를 먼저 추가해볼걸
- 그리고, 컬럼 추가에 있어서는 CatboostRanker의 Feature Importance를 기준으로 추가했었는데, 이 부분도 빈약한 근거였다. Nueral Net에 영향을 미치는 Feature가 무엇이였을까 하는 고민을 더 해볼 걸 아쉽다.
- Baseline을 제대로 독파하지 못해서 초반에 10일 정도의 시간을 고생했던 것이 아쉬웠다. 나중에야 이유가 Baseline을 통한 기본적인 알고리즘을 이해하지 못했던 것이였던 걸 깨달았다. why? 처음 Ranking 대회를 접해보고, 알고리즘을 짜봤기 때문이다.
- 모델에 대한 Skill을 쌓는 것도 중요하지만, 실제로 어떠한 문제에 있어서 잘 적용할 수 있는지, 어떠한 시도를 했는지가 더 중요한 것 같다. 최근에 부캠에서 여러 취업 설명회를 듣고 있는데, 왜 현직자 분들이 이러한 능력이 더 중요하다고 하는지 이번 대회를 통해서 절실히 느꼈다.
- 특정 모델을 선정하기에 앞서서 sweep을 적용하는 코드를 적용할 걸 그랬나 하는 아쉬움이 있다. 다음 대회에는 sweep을 적용하면서 대회를 진행해볼 할 것이다.
