안녕하세요? 이번에 우아한테크캠프 프로젝트를 진행하면서 조회 페이징 구현을 하면서 정리한 내용입니다.
Offset 페이징
대부분 처음 페이징을 배울 때 사용하는 페이징 방식입니다. 다들 처음에 페이징을 한다면 이 방식을 썼을거라고 생각합니다.
SQL의 offset과 limit 구문을 사용하는 방식입니다. 아래는 SQL query 예시입니다.
select * from board b order by b.name limit 5 offset 3;이런 형태의 페이징이 됩니다. (출처: 백준)
이 방식의 장점은 구현이 쉽고, Spring Data JPA에서 Pageable이라는 객체를 사용하여 간단하게 페이징을 구현할 수 있는 장점이 있습니다.
Offset 페이징의 단점
offset 페이징 쿼리는 offset까지 데이터를 조회한 뒤 limit 범위의 데이터를 읽는 방식입니다.
이런 말도 안되는 쿼리가 있다고 생각해볼까요?
select * from board b where order by b.id limit 5 offset 328312418234123;이 때 offset까지 데이터를 조회하기 때문에 328312418234123 + 5개의 tuple을 탐색하게 됩니다.
말도 안되게 시간이 오래 걸리겠죠?
즉 offset 페이징은 offset의 값이 커지면 쿼리의 실행이 오래 걸리는 문제가 발생합니다.
다른 문제도 알아볼까요?
offset 페이징은 중간에 데이터가 추가되거나 삭제되는 상황에서 데이터 조회에 문제가 발생할 수 있습니다.
2가지 경우에 대해 각각 알아봅시다.
- 중간의 데이터가 삭제되는 경우
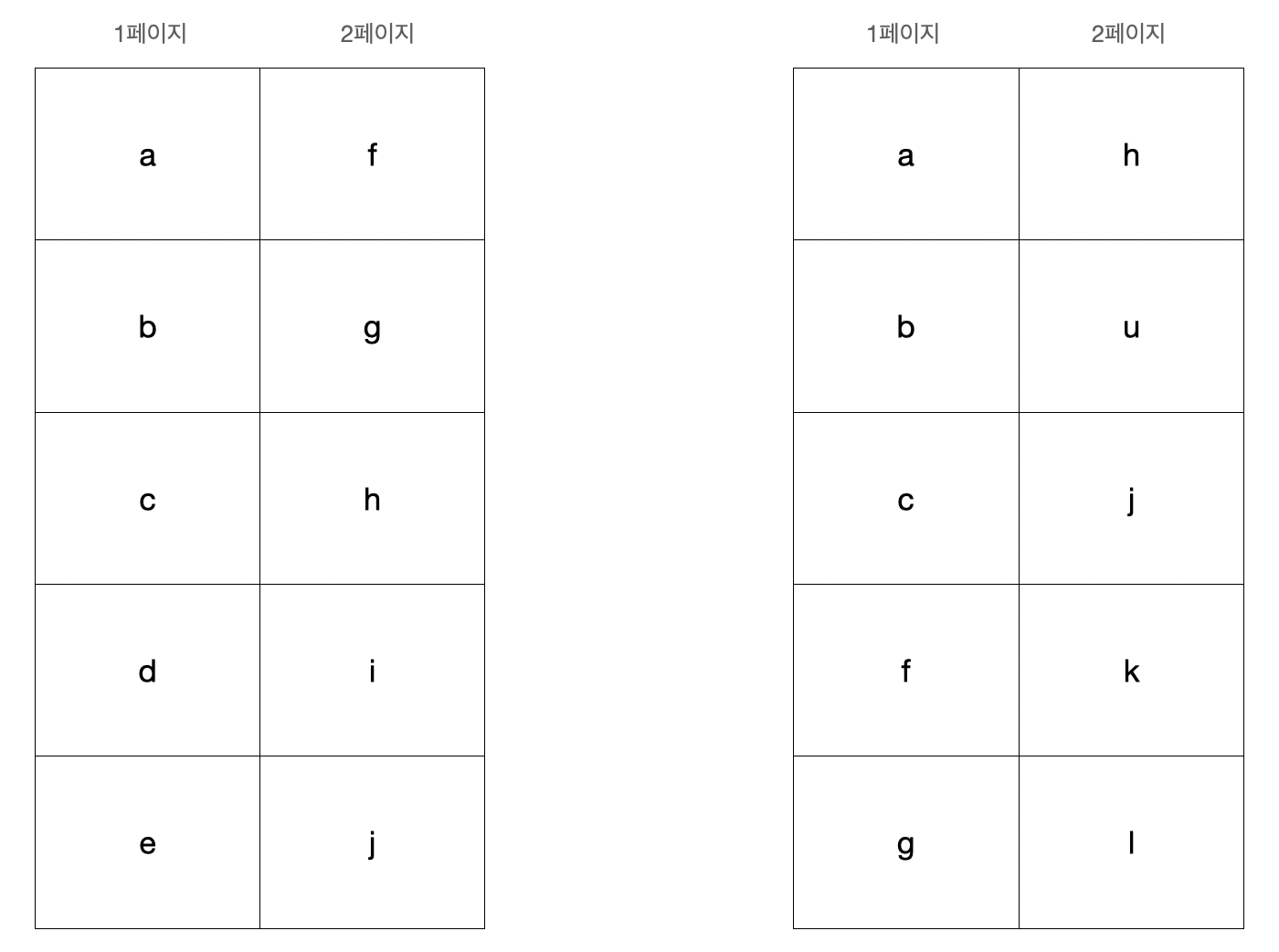
1페이지를 조회하던 중 d, e 데이터를 삭제했다고 생각해보자 그러면 우리는 2페이지를 볼 때 f,g 데이터를 다음 페이지에서 볼 수 없게 됩니다.
- 중간에 데이터가 추가되는 경우
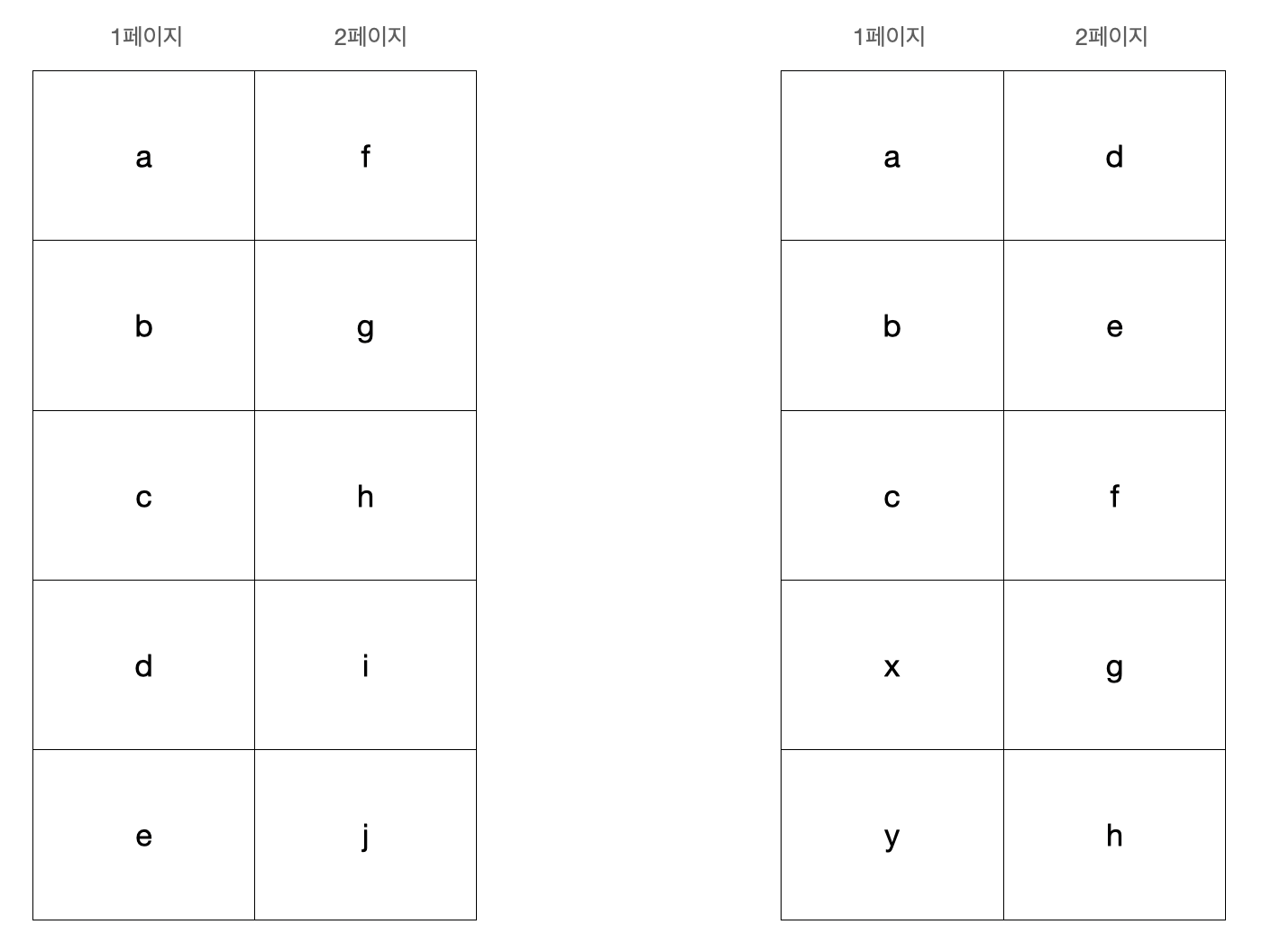
1페이지를 조회하던 중 1페이지에 x, y 데이터가 추가 되었을 때 2페이지를 넘어가게 되면 중복된 d, e 데이터를 조회하게 됩니다.
이런 문제가 사실 큰 문제는 아닐 수 있지만 사용자에게 좋지 않은 경험을 주기 때문에 이런 문제는 피하는게 좋겠죠?
cursor 방식
이런 offset 페이징의 문제를 해결하기 위해 등장한 것이 cursor 방식 페이징입니다.
cursor 페이징을 이용하게 되면 offset 페이징에서 발생하는 문제(데이터 중복, 누락, 속도)를 해결할 수 있습니다.
cursor 페이징은 offset 구문이 아닌 where 조건으로 페이징을 처리합니다.
where 조건에 현재 조회한 데이터들의 마지막 데이터의 조건을 넣어주는 방식으로 페이징 처리를 진행합니다.
select * from board b where b.id > 10 order by b.id limit 5;이렇게 되면 offset을 탄다고 이전의 모든 데이터를 조회하지 않기 때문에 성능적으로 빨라지겠죠?
그러면 처음 데이터는 어떻게 조회할까요? 처음 데이터는 where 조건을 안주면 조회할 수 있습니다.
select * from board b order by b.id limit 5;이러면 알아서 첫 5개의 데이터를 가져오게 됩니다.
cursor 방식 주의사항
항상 모든 기술이 만능은 아닙니다. cursor 방식도 만능이 아니여서 주의해야 될 점이 존재합니다.
뭘 주의해야되는지 알아봅시다.
- where의 커서 조건에 인덱스가 걸려있어야 된다.
현재 제가 적은 sql 예시는 id(pk)를 기준으로 where 조건을 타게 되어 알아서 인덱스가 적용이 되겠지만 만약 인덱스가 걸려있지 않은 특정 필드 값을 바탕으로 cursor 조회를 한다고 가정하면 테이블의 모든 row를 찾게 됩니다.
그 예시를 하나 보여드리겠습니다.

현재 products 테이블의 quantity 속성에는 인덱스가 걸려있지 않습니다. 이 때 이 쿼리 계획을 보면 아래와 같은 결과가 나옵니다.

테이블 전부를 scan하는 것을 확인할 수 있습니다. 이러면 cursor를 사용하는 이유가 아예 없겠죠?
이번에는 quantity 속성에 인덱스를 부여하고 다시 쿼리 실행 계획을 살펴보겠습니다.

인덱스를 바탕으로 범위 스캔을 하는 것을 확인할 수 있습니다.
- 커서 조건 중 최소한 하나는 unique 필드로 두어야 한다.
커서 조건에 중복되는 데이터가 있을 때 문제가 발생할 수 있습니다. 어떤 문제인지 살펴볼까요?
위의 상황에서 quantity는 unique 필드가 아니므로 이 상황에서 바로 예시를 하나 드리겠습니다.

select *
from products
order by quantity
limit 3;처음에 3개의 데이터를 가져왔다고 생각합니다. 그 다음 페이지를 가려면 아래와 같은 쿼리가 실행됩니다.
select *
from products
where quantity > 33
order by quantity
limit 3;마지막 데이터의 커서 정보의 quantity가 33이므로 이런 쿼리가 나가겠죠? 그러면 아래의 데이터를 가져오게 됩니다.

이렇게 일부 데이터가 누락되게 됩니다. 이런 상황을 피하기 위해서 cursor 방식으로 페이징을 하기 위해서는 unique한 필드 하나를 포함해야 됩니다.
지금 같은 상황에서는 pk 값 또는 다른 유니크 필드를 커서 조건으로 넣어줘야겠죠?
이 부분을 직접 만드는 과정은 생략하도록 하겠습니다.
이상으로 글을 마치도록 하겠습니다. 감사합니다.
