오픈소스 Kafka에 대한 분석내용이다.
소개
Pub-Sub 모델의 고성능 분산 메시징 플랫폼
Linkedin에서 만들어져서 2011년 아파치 재단의 오픈소스로 공개
- Netflix, Airbnb, Kakao 등에서 사용중
기본 메시징 시스템(rabbitMQ, ActiveMQ)에서는 Broker가 Consumer에게 메시지를 push해 주는 방식
Kafka는 Consumer가 Broker 로부터 메시지를 직접 가져가는 Pull 방식으로 동작 - Consumer는 자신의 처리 능력만큼의 메시지만 가져와 처리
특징
대용량 실시간 로그처리에 특화되어 설계된 메세징 시스템
- Producer와 Consumer 분리
- Linkedin에서 하루 1조개의 메세지를 생산하고 1페타바이트 이상의 데이터를 처리
메세지를 디스크에 저장
- 일반적인 메세징 시스템은 Consumer가 메세지를 읽어가면 큐에서 삭제하는 방식
- Kafka는 메세지를 파일로 저장하고 일정시간이 지나면 삭제
- 서버에 장애가 발생해도 메세지 복원 가능
간단한 Scale out 및 무중단 서비스
- Kafka Cluster는 최소 1대의 브로커로 시작해 수십대로 확장 가능
구조
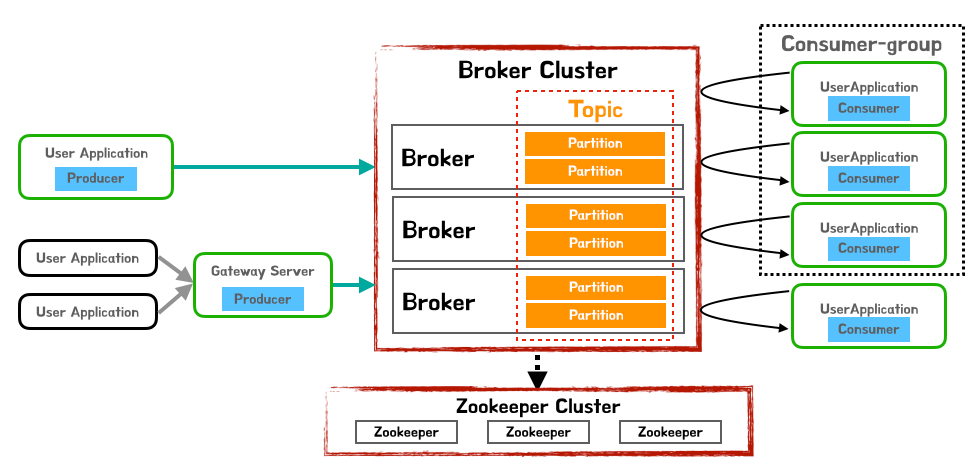
Broker
Kafka를 구성하는 각 서버
Topic
Data가 저장되는 곳
Kafka에 저장되는 메세지는 Topic으로 분류됨
- ex) email topic, sms topic
Topic은 여러개의 파티션으로 나눠질 수 있고 Kafka Cluster는 각 파티션을 관리한다.
Partition
Topic내에서 메세지가 분산되어 저장되는 단위
한 Topic에 Partition이 6개 있다면 6개의 Partition에 대해 메세지가 분산되어 저장
Partition안에 메세지의 상대적 위치를 나타내는 Offset Id가 할당
동시에 들어오는 많은 데이터를 여러개의 파티션에 나누어 저장하기 때문에 병렬로 빠르게 처리할 수 있다.
Producer
Broker에 데이터를 write하는 역할
데이터를 특정 토픽(Topic)으로 전송
Consumer
Broker에서 데이터를 read하는 역할
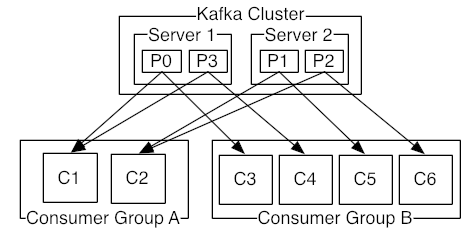
Consumer-Group
Consumer의 묶음 단위(n consumers)
Topic에 대한 Offset은 Consumer Group 단위로 구분
Zookeeper
Kafka를 운용하기 위한 Coordination service
클러스터의 설정 정보, 동기화, 리더 채택등 클러스터의 서버들이 공유하는 데이터를 관리하기 위해 사용
데이터 쓰기, 읽기, 복제
Write
Producer는 1개 이상의 Partition에 나뉘어 데이터를 Write함

Read
Consumer는 Partition단위로 데이터를 병렬로 읽을 수 있음
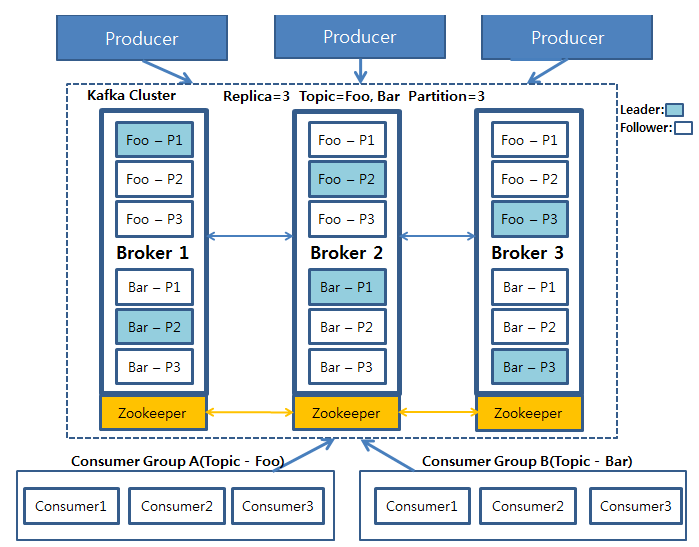
Replication
Replication 수를 지정하여 Topic을 만들수 있음
- replication-factor 옵션으로 지정
- ex) "Topic-3"은 replication-factor=3
Leader/Follower Partition
- Kafka Cluster내에는 Broker 간에 Leader/Follower Partition 개념이 있음
- Topic의 모든 데이터에 대한 Read/Write는 오직 Leader에서 이루어진다.
- Follower는 Leader와 Sync를 유지함으로써 Leader에 문제가 생겼을 경우 Follower들 중 하나가 Leader역할을 한다.
ACKS 설정
- 복제를 하기 위한 시간과 네트워크 비용이 들기 때문에 데이터의 중요도에 따라 acks 옵션으로 세부 설정이 가능
- acks=0
Producer는 Broker로 메시지를 전송만 하고 응답을 기다리지 않는다. - acks=1
Producer는 Broker로 메시지를 전송하고 응답을 기다린다. - acks=all(-1)
Producer는 Broker로 메시지를 전송하고, 리더는 모든 서버들의 복제가 끝난후 Producer에게 응답을 한다.
Kafka Client 종류
C/C++
Python
Go (AKA golang)
Erlang
.NET
Clojure
Ruby
Node.js
Proxy (HTTP REST, etc)
Perl
stdin/stdout
PHP
Rust
Alternative Java
Storm
Scala DSL
Clojure
Swift기타
KSQL
Kafka에서 사용가능한 스트리밍 SQL 엔진, KSQL Server 필요
SQL문법으로 Real time application을 작성할 수 있음(ex. Streaming ETL, Anomaly Detection, Monitoring)
Kafka Streams
Library로서 Java나 Scala로 Real time application을 작성할 수 있음
import org.apache.kafka.streams.scala.Serdes._
import org.apache.kafka.streams.scala.ImplicitConversions._
.....
val builder = new StreamsBuilder()
val textLines: KStream[String, String] = builder.stream[String, String]("streams-plaintext-input")
val wordCounts: KTable[String, Long] = textLines
.flatMapValues(textLine => textLine.toLowerCase.split("\\W+"))
.groupBy((_, word) => word)
.count()
wordCounts.toStream.to("streams-wordcount-output")
....참고
https://www.confluent.io/blog/using-apache-kafka-drive-cutting-edge-machine-learning/#model-deployment
https://victorydntmd.tistory.com/344
https://www.popit.kr/kafka-consumer-group/
https://zzsza.github.io/data/2018/06/15/apache-kafka-intro/
https://blog.voidmainvoid.net/179
https://engkimbs.tistory.com/691
https://www.confluent.io/blog/ksql-streaming-sql-for-apache-kafka/
