- torchvision도 그렇고 albumentation도 그렇고 계산은 standardization이면서 클래스 이름은 Normalize인 이유가 무엇일까?
(2022. 06. 08)
한글 설명
Min-Max Normalization : 0 to 1 정규화
Z-Score Normalization : mean 0 std 1 표준화
둘 다 정규화의 기법들 중 하나이다.
(2022. 06. 07)
여기에 자세히 설명되어있다.
Normalize에는 두 가지의 의미가 존재한다고 한다.
Putting the data on the same scale (Scaling)
Balancing the data around a point (Centering)
(2022. 05. 20)
보통 normalization은 scaling(min-max)을 목적으로 많이 사용하는데 Normalize 클래스도 scaling(standard)을 수행하는 것이라 볼 수 있으므로 scaling이라는 공통점에 착안하여 Normalize라고 칭한 것일까?
(2022. 05. 23)
batchnorm도 norm도 normalization인 것을 보면 normalization은 아예 모든 scaling를 포괄하는 개념이고 standardization은 normalization의 일부인 것으로 보는게 합당한 것 같다.

그렇다면 Image Classification에 있어 torchvision.transforms.Normalize를 하는 이유는 무엇일까?
머신러닝 수업 때 정규화와 표준화에 대해서 배웠다.
이것 저것 알아본 결과 정규화의 의미는 매우 넓다.
보통 정규화 = Normalization으로 번역되지만 규제를 나타내는 Regularization또한 정규화로 부르기도 하는 등 상당히 넓은 의미로 사용되기 때문에 '정규화'라는 단어를 본다면 문맥을 보고 나타내는 바가 정확히 무엇인지 파악해야 한다.
이렇게 한글과 영어 사이를 왔다갔다하면서 느낀 게 하나 있다.
보다 정확한 의미전달을 위해선 한글보단 영어로 표기하는 것이 좋지 않을까 하는 것이다.
그런 의미에서 앞으로는 메모할 때 0 to 1 scaling(정규화)를 Min-Max Norm으로, mean 0 std 1 scaling(표준화)를 Z-Score Norm으로 표현하기로 했다.
머신러닝에서 min-max Norm을 사용하는 주된 이유는 0 to 1 scaling을 통해 column간의 단위가 다를 때 단위가 큰 쪽에만 모델이 집중하는 현상을 막기 위함이며
Z-Score Norm의 주된 이유는 mean 0 std 1 scaling과 더불어 데이터의 분포를 고르게 하여 모집단의 분포를 보다 효과적으로 예측하기 위한 것이다.
물론 Min-Max Norm와 Z-Score Norm이 무조건적인 답은 아니며 데이터의 특성을 면밀히 파악한 후 그에 맞춰 사용해야 한다는 것도 배웠다.
이미지 분류에서 Min-Max Norm과 Z-Score Norm을 사용하는 목적도 비슷하다.
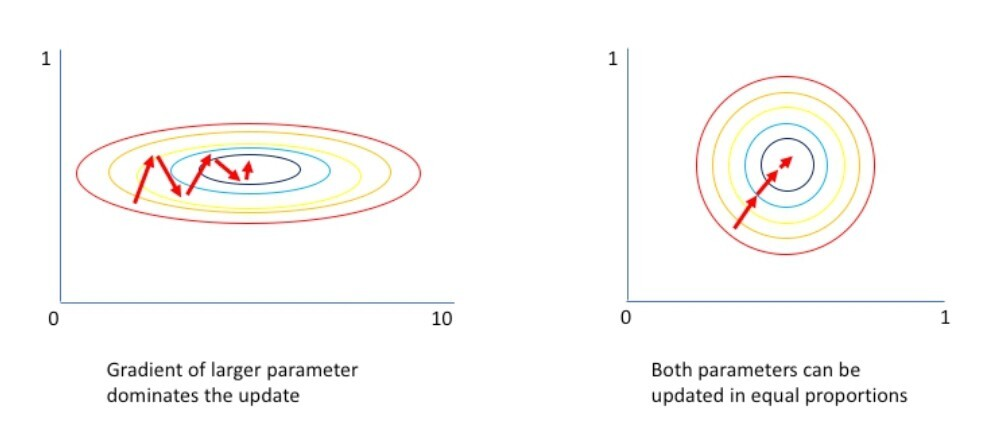
Min-Max Norm은 0~255의 rgb값을 그대로 사용하면 각 픽셀마다 학습률을 다르게 적용하느라 연산이 복잡해지기 때문에 0 to 1 scaling을 하기 위해 사용하며
Z-Score Norm은 광원과 같은 외부 요인으로 인해 픽셀간의 대비가 왜곡되는 현상(=모집단의 분포를 예측하기 힘들게 만듦)에 대응하여 다양한 외부 요인 하에서도 원활하게 분류할 수 있게 일반화 성능을 높이기 위해 사용한다.
그러나 pytorch를 사용할 땐 Min-Max Norm을 신경쓸 필요가 없다. 이미지 전처리 과정에서 rgb to tensor 변환에 반드시 필요한 torchvision.transforms.ToTensor()를 거치면 Min-Max Norm도 자동으로 이루어지기 때문이다.
※ input 이미지의 array type이 np.uint8일 경우에 한해서 Min-Max Norm이 진행된다.
※ uint8 : 0부터 255(2^8-1)까지의 값을 저장할 수 있는 양의 8비트 정수 자료형를 뜻한다. int앞에 붙는 u가 양수를 의미한다.
※ int8 : -128부터 127까지의 값을 저장할 수 있는 8비트 정수 자료형을 뜻한다.
남은 건 Z-Score Norm인데... Z-Score Norm이 언제나! 반드시! 필요한 것은 아니라는 생각이 들기 시작했다.
개인적으로 Z-Score Norm를 썼을 때 성능에 차이가 없거나 오히려 성능이 낮아지는 경우가 있었고 그런 경험담도 종종 보이는 것을 보아 Z-Score Norm라고 해서 무조건 만능이 아니고 장단점이 있으며 적재적소가 있을 것으로 생각된다.
매우 극단적인 예를 들어보자.
동물의 종류를 분류하는 것이 목표인 데이터셋에서 '고양이'에 해당하는 데이터가 아침, 한낮, 저녁, 야간, 실내 등 다양한 광원과 흙바닥, 풀밭, 아스팔트, 수영장 등 다양한 배경에서 찍은 사진인데 이 중 저녁에 흙바닥에서 찍은 고양이 사진이 80%나 된다고 가정해보자. 이런 데이터셋으로 학습을 시킨다면 모델은 아무래도 저녁시간 특유의 노을색 광원과 흙바닥 특유의 고동색 배경, 즉 rgb 셋 중 r값에 편향된 가중치를 가질 수 밖에 없을 것이다. 객체인 고양이 그 자체만 본다면 딱히 r값에 편향돼있지 않음에도 말이다.
이러한 데이터셋에 Z-Score Norm을 적용해준다면 데이터셋의 80%를 점유하고 있는 저녁시간+흙바닥의 rgb특성이 모든 데이터에 고르게 녹아들 것이고, 배경&광원이 다르다는 이유로 오분류를 일으키는 불상사를 어느정도 예방할 수 있는 것이다. (물론 이 정도로 극단적인 불균형이 발생한다면 아무리 Z-Score Norm을 적용해도 한계가 있을 것이다. 머신러닝이든 딥러닝이든 모집단의 분포를 잘 반영한 양질의 데이터셋을 확보하는 것이 그 무엇보다 중요한 이유다.)
즉 이미지에 있어서 Z-Score Norm란 유효한 feature 추출을 방해하는 불필요한 정보, "노이즈"를 제거하는 과정인 것이다.
의문점1.
- 그렇다면 광원과 배경을 칼같이 통제한 데이터라면 어떨까?
애초부터 노이즈가 없으니 Z-Score Norm을 적용하든 안하든 비슷한 결과가 나오지 않을까?
더 나아가 사람의 눈으로도 구분이 수 초 이상 걸릴 정도의 미세한 차이점을 구분해야 한다면 어떨까?
미묘한 색깔 차이를 통해 class를 구분해야 하는 데이터에서 Z-Score Norm을 사용한다면 그 미묘한 색깔 차이가 뭉개져서 모델이 더 헷갈려 할 수도 있을 것이다.
의문점2.
-
우리가 Augmentation을 사용하는 주된 목적은 데이터에 의도적으로 노이즈를 섞어서 일반화 성능을 올리기 위함이다.
앗! 그런데, 여기서 무언가 충돌하는 개념이 있다.
위에서 Z-Score Norm의 목적이 노이즈를 제거하는 것이라고 결론지었는데 Augmentation은 그와 반대로 노이즈를 추가한다...?
Z-Score Norm과 Augmentation 모두 일반화 성능 향상이라는 목적은 같지만 방향성이 정반대인 것이다.여기서 한 가지 추측이 가능하다.
두 가지 기법은 서로 trade-off 관계이며 특정 데이터셋에 대해 어느 한 기법이 특출나게 주효하다면 다른 쪽 하나는 오히려 사용을 지양해야하지 않을까?12th코드는 사용한 모델도 가볍고 validation도 수행하지 않았다.
특징은 오로지 albumentations 라이브러리를 활용해 매우 다양한 augmentation을 주었다는 것 하나 뿐이다.
그럼에도 상대적으로 높은 f1-score가 나왔다는 것은 그 '다양한 Augmentation'이라는 기법이 매우 효과적이었다고 해석할 수 있을 것이다.
반면 내 코드나 3rd코드 5th코드 모두 Z-Score Norm을 하나 안하나 성능에 차이가 거의 없었다.
MVTec데이터셋에 있어 표준화는 효과가 미미한 반면 Augmentation은 효과가 좋다는 것이 입증된 것이다.
그러한 Augmentation에 힘을 빡 준 12th코드에 Augmentation과 정반대의 방향성을 가진 Z-Score Norm을 적용했으니 성능이 떨어지는게 오히려 당연한 게 아닐까?정리하면 우리가 사용했던 데이터는 Z-Score Norm보다는 Augmentation에 집중하는 것이 더 효과적이라는 결론을 도출할 수 있다.
MVtec데이터셋에 Z-Score Norm의 효과가 없는 이유는 의문점1과 어느정도 상통할 것으로 보인다.
광원과 배경을 철저하게 통제한 환경 하에 촬영된 사진이니 유효 feature 추출에 악영향을 주는 "노이즈"가 없기 때문에 굳이 표준화를 하지 않아도 괜찮았던 것이다.
사람에게도 좋은 스트레스와 나쁜 스트레스가 있듯이 노이즈에도 좋은 노이즈가 있고 나쁜 노이즈가 있는 게 아닐까?
좋은 노이즈(Augmentation)는 일반화 성능을 높여주지만 나쁜 노이즈(편향된 광원과 배경)는 성능을 떨어뜨리는 것이다.
하지만 Z-Score Norm은 좋은 노이즈와 나쁜 노이즈를 구분하지 못하기 때문에 의도적으로 좋은 노이즈를 많이 부여한 데이터셋에 Z-Score Norm을 사용하면 오히려 성능이 떨어지는 경우가 발생하는 것이다.
