
'index를 탄다'는 것은 뭘까?
DB에서 쿼리를 실행하여 데이터를 찾게 될 때, 인덱스를 타야된다고 흔히 얘기한다.
그렇다면 인덱스를 탄다는 것은 무슨 뜻일까? 오늘 다 알아보자..!
우선 index에 대해서
📕 영어사전에서 'zoo'라는 단어를 찾아본다고 생각해보자.
1페이지의 a-로 시작하는 단어부터 찾는 사람이 있을까?
(물론 있을수도 있지만 매우 오래 걸릴 것이다! )
우리는 보통 z 섹션으로 바로 펼치고, 다음 글자인 zo- 섹션을 찾고.. 이러한 단계로 단어를 찾아나간다.이것이 바로 index를 타고 단어를 찾아나가는 것이다.
그렇다면 DataBase에서의 index라는 것은 무엇일까?
인덱스(Index)는 데이터베이스의 테이블에 대한 검색 속도를 향상시켜주는 자료구조이다.
특정 테이블의 column에 대한 index를 만들면 데이터베이스 열의 검색 속도가 빨라져서 쿼리의 성능이 향상된다 !
index를 타지 못하면 '전체 테이블 스캔(full scan)' 방식을 사용하여 데이터를 찾게 된다. (처음부터 끝까지 찾기..검색 속도가 느리겠죠?)
index를 탄다 == index를 통해 효율적인 검색을 한다 정도가 되겠군요
Index는 어떻게 작동하는 건데?
index는 다음과 같은 단계로 작동한다.
1. index 생성
- 컬럼의 값들을 정렬해서 data 구조로 만든다.
- 구현 방식에 따라 B+tree 혹은 해시 알고리즘을 사용한다.
B+Tree
- b-tree는 자식노드-부모노드로 이루어진 트리 형태의 자료 구조이다.
- 2개 만을 갖는 이진 트리(Binary Tree)를 확장하여 N개의 자식을 가질 수 있고, 모든 리프노드들이 같은 레벨을 가질 수 있도록 자동으로 밸런스를 맞추는 균형잡힌 트리 구조이다.
Hash
- 해시 테이블은 key와 value를 한 쌍으로 데이터를 저장하는 자료구조이다.
https://velog.io/@jiwonyyy/javascipt-Set-vs-Array-시간복잡도-비교-해시테이블이란
2. index 탐색 및 data 검색
- 해당 컬럼에 대한 검색 쿼리가 나타나면, 인덱스를 사용하여 대상 데이터를 찾는다.
- 검색된 index를 통해서 해당 레코드를 찾아서 반환
?? 그러면 이 해시인지 비트리인지.. 어떻게 정하는걸까? 내가 정해야하나??
정답은 no...
쿼리 옵티마이저 (Query Optimizer)
다행히도, 데이터베이스 시스템에서는 쿼리 실행 시 적절한 인덱스를 선택하고 사용하는 것을 자동으로 처리하는 쿼리 옵티마이저(Query Optimizer)라는 것이 있다.
쿼리 옵티마이저는 인덱스를 사용할 수 있는지, 어떤 인덱스를 사용할지, 어떤 순서로 테이블에 접근해야 하는지 등을 결정한다. 이때 쿼리 옵티마이저는 테이블에 대한 통계 정보, 인덱스 구조, 쿼리 조건 등을 고려하여 최적의 실행 계획을 수립한다.
B tree 알고리즘을 사용하는 경우
- 범위 검색(Range Query)
- 중복 값을 가지는 컬럼
- 자주 갱신되는 데이터
해시 알고리즘을 사용하는 경우
- 등호 검색(Exact Match Query)
- 고정 길이의 키(Key)
- 자주 갱신되지 않는 데이터
그렇다면 index를 무조건 설정하는 것이 좋지 않아?
무조건 좋은 것... 이라는게 있을까?
- 인덱스는 데이터베이스의 용량을 증가시킨다.
- 또한 data Insert, Update, delete 작업의 속도를 늦출 수 있다.
- INSERT : 새로운 데이터에 대한 인덱스를 추가해야 함
- DELETE : 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업 수행해야 함
- UPDATE : 기존의 인덱스를 사용하지 않음 처리, 갱신된 데이터에 대한 인덱스 추가해야 함.
=> 그러므로 index는 적절한 column에 대해서만 사용하는 것이 좋다 !
그러면 index를 언제 설정하면 좋을까?
- write보다 read의 빈도가 더 높은 컬럼 (검색, 필터 등이 적용되는)
- data row 수가 많은 경우
- 인덱스를 적용한 컬럼이 where절에서 많이 사용되는 경우
- 검색 결과가 원본 테이블 데이터에 비해 적을 경우
- 해당 컬럼이 null을 포함하는 경우 (NULL 값을 가진 노드를 건너뛰고 검색을 수행)
Sql에서 index 사용하는 방법
우선, 기존의 table을 까보자
DESCRIBE users;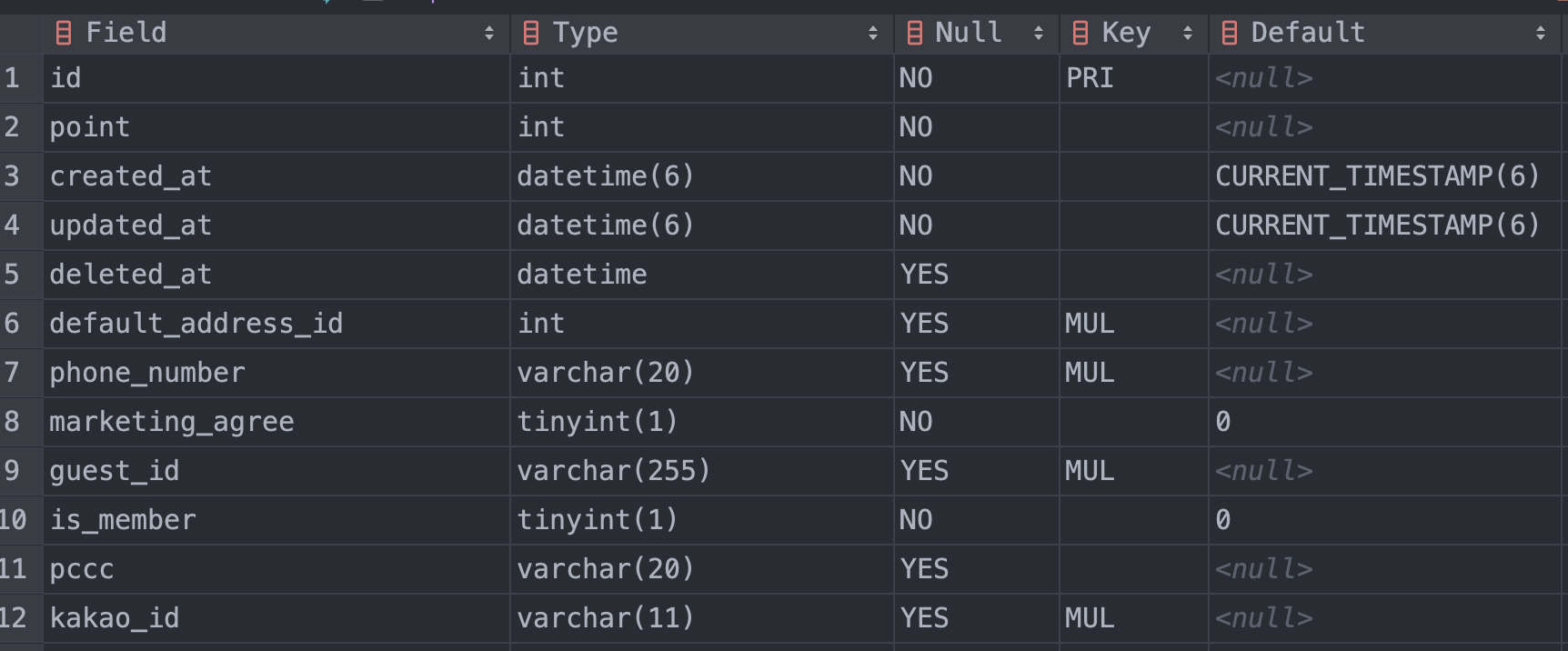
여기서 key 컬럼에 값이 들어간 필드들이 있다.
key에는 세가지가 들어갈 수 있는데
PRI = primary key
UNI = unique key
MUL = Multiple
이중 하나라도 들어가 있으면 인덱스를 타는 필드들이다!
index를 추가하는 방법
필드에 인덱스를 어떻게 추가할까?
primary key이거나 unique 인 경우는 자동으로 인덱스가 생성이 되고, 특정 컬럼에 다음과 같은 명령어로 추가할 수도 있다.
CREATE INDEX 인덱스명 ON 테이블명 (컬럼명);만들었던 인덱스 제거하려면
DROP INDEX 인덱스명;자 그럼 이제 내가 실행시킨 쿼리가 인덱스를 타는지 안타는지 확인해보자.
조건이 있는 쿼리문의 실행 계획을 보자.
- 인덱스를 타는 경우 (phone_number)
explain select * from users where phone_number like '0103300%';
- 인덱스를 타지 않는 경우 (pccc)
explain select * from users where pccc like '123%';


실행 계획을 확인했을 때 key값에 index-name이 있으면, 해당 인덱스를 타고 탐색이 되고 있는 것이고, 없으면 full-scan을 통해서 값을 찾는 것이다.
주의사항
힘들게 index에 대해서 알아 놓고.. index를 태우지 않는 쿼리를 만들어 내면 안될 것이다.
대표적인 실수로 index가 걸려있는 값을 형변환 해서 검색하는 경우가 있다. 형변환이 이루어진 경우, 쿼리에서 사용하는 조건 값이 인덱스 컬럼과 데이터 타입이 일치하지 않아 풀 스캔을 수행하게 된다.
example
// BAD
minCreatedAt &&
(query = query.andWhere('date(oi.createdAt) >= :minCreatedAt', {
minCreatedAt,
}));
maxCreatedAt &&
(query = query.andWhere('date(oi.createdAt) <= :maxCreatedAt', {
maxCreatedAt,
}));코드에서 date 함수를 사용함으로써 형변환이 이루어져 index를 가진 컬럼이라도, 인덱스를 타고 검색을 하지 못한다. 이런 경우에는 코드를 수정해주어야 한다!
createdAt 값을 BETWEEN 연산자를 사용하여 범위를 지정하도록 수정하였다. 이렇게 하면 createdAt 값이 직접 비교되므로 인덱스를 타게 된다
// GOOD
minCreatedAt && maxCreatedAt &&
(query = query.andWhere('oi.createdAt BETWEEN :minCreatedAt AND :maxCreatedAt', {
minCreatedAt,
maxCreatedAt,
}));Full text index
그렇다면 검색 쿼리를 살펴보자.
기존의 서버 코드를 살펴보면..
searchTerm &&
(query = query.andWhere(
`concat_ws(' ', pv.model, pv.erpCode) like :searchTerm`,
{
searchTerm: `%${searchTerm}%`,
},
));이 코드는 아래와 같은 쿼리를 실행한다
select * from product_variations pv
where concat_ws(' ', pv.model, pv.erp_code) like '%테이블%';
model, erpCode는 모두 index를 갖는 필드임에도 불구하고
concat method로 무자비하게 합쳐버렸으니 ㅠㅠ
아무리 인덱스를 가진다해도 풀스캔으로 검색하는 중이었다...............
그래서 index를 공부한 후에
그럼 concat으로 하지말고 or 조건을 넣어서 해봐야지! 라고 다음과 같이 쿼리문을 고쳐보았다
select * from product_variations pv
where pv.erp_code like '%123%' or pv.model like '%123%';
근데 여전히 인덱스를 타지 않는 것을 확인하였다.
그 이유를 알아보니,
LIKE 연산자를 사용하는 경우, 와일드카드(%)를 사용하면 범위 검색이 불가능 하여 인덱스를 사용할 수 없게 될 수 있다고 한다.
LIKE 연산자를 사용할 때는 와일드카드(%)를 최대한 적게 사용하고, 만약에 사용해야 한다면 와일드카드가 있는 부분 이전까지는 정확한 값을 지정해 주거나, (한쪽만 와일드카드일 시에는 인덱스 탐)
컬럼에서 일부 문자열을 찾아야 하는 경우에는, 전체 테이블을 스캔하지 않고도 인덱스를 이용한 검색이 가능한 Full Text Search(Full-Text Indexing) 기능을 사용해야 한다.
이 케이스의 경우
다양한 컬럼의 값에 대해서 일부 텍스트가 일치하는 레코드를 가져와야하기 때문에 풀텍스트 설정을 해두는 것이 맞다. (예시로는 2개 컬럼이지만 실제로는 10개 넘는 컬럼에 대한 검색이 필요했음)
풀텍스트 인덱스 설정하기
- 풀텍스트 설정할 컬럼들을 모아서 add fulltext
alter table product_variations add FULLTEXT (model, erp_code);- where절에 like가 아닌 match-against로 조건 주기
select * from product_variations
where MATCH (model, erp_code) AGAINST ('%123%' IN BOOLEAN MODE);
이렇게 fulltext index를 이용하여 검색 속도를 향상시킬 수 있다~!
