
3.5 Connection-oriented transport:TCP
- connection-oriented:handshaking
- full duplex data(양방향)
- pipeline(ack 안받고 연속으로 보냄)
- flow control(rwnd)
- congestion control(cwnd)
TCP segment structure
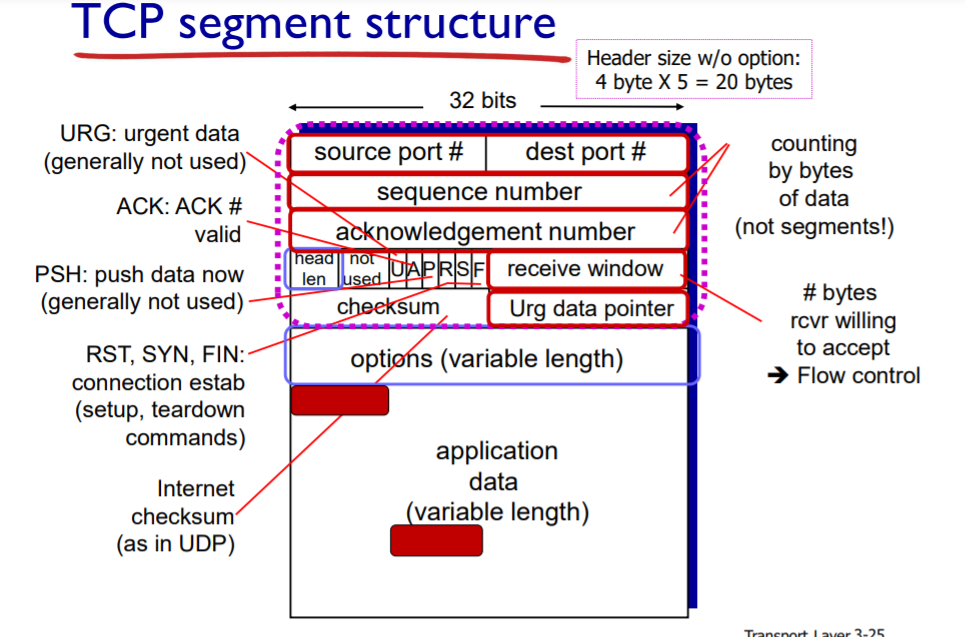
ack num: 다음에 이거 보내줘!
0~535byte 포함하는 segment 받았으면 다음 ack num은 536
receiver가 틀린 순서로 받으면? ack은 받아야 되는 올바른 번호로 보내고, 잘못 받은건 버리거나 keep하거나 알아서..(tcp 정의x)
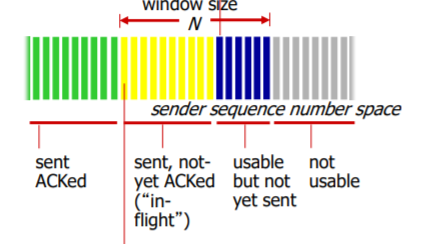
sendbase: oldest unacked byte. 노랑이 첫번째
next seq num: usable but not yet sent의 첫번째=파랑이 첫번째
TCP tound trip time, timeout
timeout value는 RTT보단 길어야 함.
sampleRTT:segment가 송신된 시간 ~ ack이 도착 시간. 재전송으로 인한 틀린 sampleRTT는 무시!
estimateRTT: sampleRTT의 평균 계산값. 새로운 sample RTT값을 얻자마자 갱신해준다.
※새로운 estimatedRTT= 이전 estimatedRTT x (1-a)+ a x sampleRTT. (a=0.125)
DevRTT: sampleRTT가 estimatedRTT로부터 얼마나 많이 벗어나는지에 대한 예측
새로운 DevRTT=(1-p)x(이전 DevRTT)+ px|sampleRTT-estimateRTT|. (p=0.25)
결론적으로, timeoutInterval=EstimateRTT + 4x(DevRTT)
3.5 (1)Reliable data transfer
TCP reliable data transfer
pipelining+ cumulative ack
cumulative ack이란?
현재까지 수신된 바이트들을 하나의 ack로 일괄 응답. 앞선 ack이 loss되어도 그다음만 잘가면 ok. 불필요한 재전송 피하는 방법 중 하나
재전송 결정하는 두가지- timeout, 3개의 중복ack
※3개인 이유- 늦게오는 애들을 loss로 오인하지 않기 위해
3.5 (2)Flow control
윈도우 사이즈 W= min (cwnd, rwnd)
flow control과 관련된건 rwnd!
flow control은 receiver의 output 버퍼의 오버플로우 방지한다. → 버퍼 잔여량(rwnd) 알려줘서 sender의 sending rate 조정.
만약 rwnd가 0이면? 주기적으로 empty segment 보내 확인
3.5 (3)Connection management
2- way handshake: 만약 상대가 보인다면(ex:전화) 괜찮지만, TCP 같은 경우는 오해로 인해 여러 불상사 생길 수 있음
3-way handshake
step1: TCP SYN segment 전송(SYNbit=1, 어플리케이션 계층 데이터는 포함x) ISN(Inital Seq Num)을 2^32-1 중 하나 선택
step2:서버 호스트에 TCP SYN segment 도착하면, 답장 위해 서버의 ISN 선택. ACKnum=클라의 ISN(Seqnum)+1로 설정. SYNbit=1,Ackbit=1
step3:클라는 답장 위해...SYNbit=0, Acknum=서버의 ISN+1, Ackbit=1
연결 끊을때
TCP는 full duplex 통신을 하기때문에 클라의 send/recv 버퍼, 서버의 send/recv 버퍼 둘 다 닫아야 함
클라가 FIN segment보내면 (이제 클라는 받기만 가능) 서버는 그에 대한 확인 segment 보내고, 클라가 그에 대한 확인 ack 보냄.
클라는 RTT 시간 정도, 서버는 max num of retry 정도는 기다려 보고 종료.
3.6 Principles of congestion control
congestion: too much datta too fast for network → long queueing delay, lost packet(버퍼 오버플로우)
원인
-
link bandwidth
sending rate>라우터 outbut 버퍼의 R이면 혼잡 -
finite output 버퍼 in 라우터
만약 버퍼가 무한이어도 큐잉 딜레이는 존재. (대신 loss는 없음) 하지만 버퍼는 유한이므로 loss, delay 모두 존재 -
multi hop
네트워크가 더 많은 일을 해야함. 만약 중간에 loss되면 이제껏 bw 차지하며 온게 다 허사가 됨..
cwnd로 컨트롤하자!
3.7 TCP congestion control
두가지 방법
- network assisted
- end to end
network assisted congestion
2bit짜리 ECN bit를 둬서 congestion 알림. 이걸 받은 receiver TCP는 ack에 ECE flag bit 설정(ex: ECN=11이면 혼잡...)
요즘엔 잘 안쓰는 방법
End to End
flow control overview
네트워크를 혼잡하지 않게 하면서 가능한 모든 자원(bw)쓰자! congestion 생길때까지 sending rate(cwnd)올리다가, 생기면 팍 떨구고 다시 congestion 생길때까지 올리고...
※cwnd는 dynamic
※대략적인 sending rate = cwnd/RTT
TCP slow start
initally cwnd=1MSS로 시작.
ack 당 2배씩 증가(1→2→4→8..) ssthresh에 도달할때까지 증가! ssthresh에 도달하면 Congestion Avoidance(CA)모드로 바뀜. CA모드에선 RTT마다 cwnd가 1MSS씩 증가한다. (=ack마다 MSS/cwnd 증가)
※ssthresh란?slow start threshold! ssthresh는 처음엔 OS가 세팅하고 이후엔 cwnd/2로 세팅.
이 slow start에도 두가지 방식이 있다.
- RENO
- Tahoe
TCP Reno
timeout loss 인 경우 → enter SS state
ssthresh=cwnd/2
새로운 sstresh에 도달하면 CA모드로 변환
3 dup ack loss 인 경우 → enter CA state
cwnd=cwnd/2한 다음 RTT당 MSS씩 linear하게 증가.
ssthresh=cwnd/2
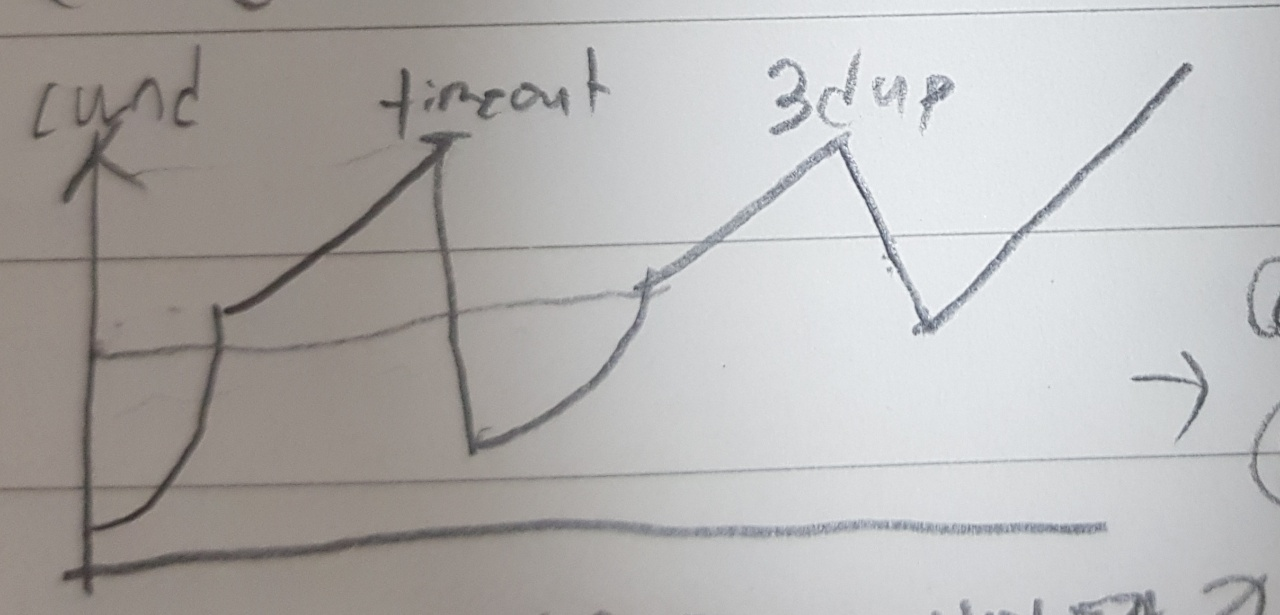
TCP Tahoe
timeout인지 3 dup loss인지 구별 안함.
RENO의 timeout처럼 동작한다.
AIMD: additive increase multiplicative decrease
- additive increase: increase cwnd by 1 MSS every RTT until loss detected
- multiplicative decrease: cut cwnd in half after loss
TCP Fairness
R이 똑같고 RTT가 같아야 공평하게 보낼 수 있다. 하지만... UDP때문에 사실상 not fair. 또한 TCP만 있다고 쳐도, non-persistent with parallel로 연결한다면 tcp 커넥션을 여러 개 얻을 수 있는 어플리케이션들이 있기 때문에 tcp(소켓)입장에선 공평할지 몰라도 L5 어플 입장에선 불공평하다.
