
Advanced Aggregation Feature
Ranking
select ID, rank() over (order by GPA desc) as s_rank from student_gradesorder by 절을 적용할 수 있다.
select ID, rank() over (order by GPA desc) as s_rank
from student_grades order by s_rankgap을 없애고 싶으면 dense_rank 사용
select ID, dense_rank() over (order by GPA desc) as s_rank from student_gradesrow number 쓰고 싶으면 row_number 사용
select ID, row_number() over (order by GPA desc) as s_rank from student_grades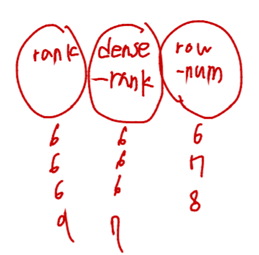
rank 함수 안쓰고 basic SQL aggregation만 쓰면?
select ID, (1+(select count(*)
from student_grade B where B.GPA>A.GPA)) as s_rank from.. 👉 더 작은애가 몇 개인지 세고 +1하는 식.. 매우 비효율적!
Ranking은 partition of data 안에서도 실행될 수 있다.
select ID, dept_name, rank()
over (partition by dept_name order by GPA desc) as dept_rank
from dept_grades order by dept_name,dept_rankSql은 99년도부터 null firsts나 null last 옵션을 허용하고 있다.
select ID, rank() over (order by GPA desc nulls last) as s_rank from student_gradesntile(n)를 사용해서 테이블을 n개의 bucket으로 나눌 수 있다.
select ID, ntile(4) over (order by GPA desc) as quartile from student_grades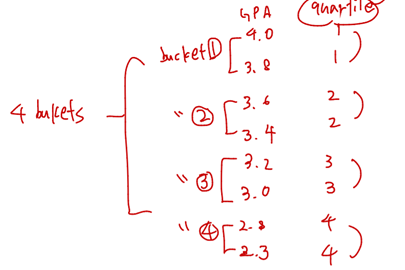
Windowing
Random value들을 Smooth out 하는 데 쓸 수 있다.
select date, sum(value)
over (order by date between rows 1 preceding and 1 following)
from sales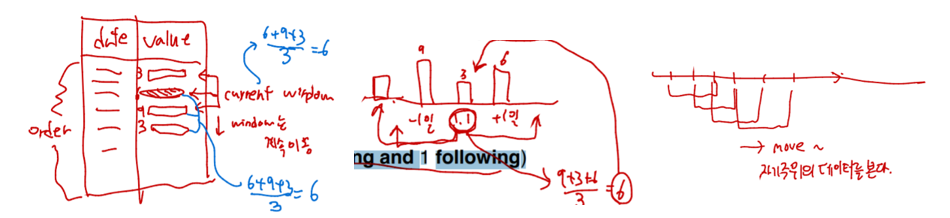
window specifications들의 예시
rows unbounded preceding: 윈도우 시작 위치가 첫번째 row
range between 10 preceding and current row: 현재row ~ 앞에서부터 10개 row
range interval 10 day preceding: 현재 row를 포함하지 않음.
Windowing도 partition 내에서 실행될 수 있다.
select account_number, date_time, sum (value)
over (partition by account_number
order by date_time rows unbounded preceding) as balance
from transaction order by account_number, date_timeOLAP
Online analytical processing(OLAP)
Multidimensional data: dimension attributes와 measure attribute로 모델링될 수 있는 데이터
Measure attribute: 어떤 측정값. Aggregated(집계)될 수 있는 값. Ex) attribute num of the sales relation
dimension attribute:어떤 measure attribute로 볼지 dimension을 정의.
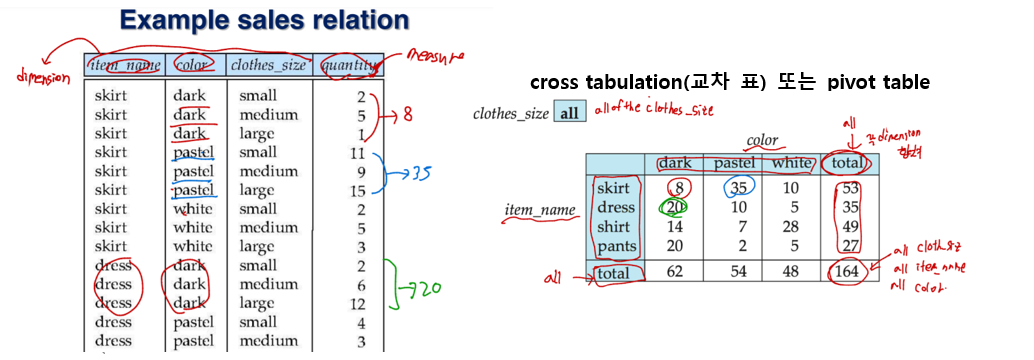
Cross tab의 row header, column header가 각각 dimension attribute. 자리 차지 못하고 남은 dimension attribute 는 listed on top (여기선 clothes_size)
Data Cube
Data cube: multidimensional generalization of a cross tab. N 개의 dimension을 가질 수 있다. Cross tab은 data cube의 view로 쓰일 수 있다.
Cross Tabulation with hierarchy
Cross-tabs can be easily extended to deal with hierarchies.
Drill down: detail-구체화
Roll up: aggregated(high level)- 일반화
Relational Representation of Cross-tabs
Cross tabs은 relations으로 대표될 수 있다.
Extended Aggregation to Support OLAP
Cube는 지정된 칼럼에 대해 모든 조합으로 group by연산을 수행한다.
select item_name, color, size, sum(number)
from sales group by cube(item_name,color,size)면 가능한 조합이 8개. Null value for attributes not present in the grouping.

Online Analytical Processing Operations
Pivoting: cross-tab에서 dimension 변경할때 호출
Slicing: fixed value에 대해서만 cross-tab 생성. Multiple dimensions이 fixed 되어 있는 경우에는 dicing이라고 부름.
Rollup: finer-granularity(detail) to coarser granularity(summary)
Drill down: coarser granularity(summary) to finer-granularity(detail)
