google.com을 입력했을 때 벌어지는 일
우리는 단순히 주소창에 google.com을 입력해 google 페이지로 이동하지만
안에서는 생각보다 복잡한 작업들이 벌어진다.
요약
사용자가 웹 브라우저를 통해 google.com을 입력하면 URL 주소 중 도메인 네임 부분을 DNS 서버에서 검색한다. DNS 서버에서 해당 도메인 네임에 해당하는 IP 주소를 찾아 사용자가 입력한 URL 정보와 함께 전달한다. 브라우저는 HTTP 프로토콜을 사용하여 요청 메시지를 생성하고, HTTP 요청 메시지는 TCP/IP 프로토콜을 사용하여 서버로 전송된다. 서버는 response 메시지를 생성하여 다시 브라우저에게 데이터를 전송한다. 브라우저는 response를 받아 파싱하여 화면에 렌더링 한다.
웹 브라우저란?
웹 서버에서 이동하며 쌍방향으로 통신하고 HTML 문서나 파일을 출력하는 그래픽 사용자 인터페이스 기반의 응용 소프트웨어이다. 웹 브라우저는 대표적인 HTTP 사용자 에이전트의 하나이기도 하다.
1. google.com을 브라우저 주소창에 친다.
2. 브라우저는 캐싱된 DNS 기록들에서 www.google.com에 대응되는 IP 주소가 있는지 확인한다.
DNS란?
DNS(Domain Name System)은 URL들의 이름과 IP 주소를 저장하고 있는 데이터베이스다. 인터넷에 있는 모든 URL들에는 고유의 IP 주소가 저장되어 있다. 이 IP 주소를 통해서 해당 웹사이트를 호스팅 하고 있는 서버 컴퓨터에 접근할 수 있다.
CACHE란?
컴퓨터는 사용자의 명령이 입력되면 CPU는 연산을 하고 동작에 필요한 모든 내용이 전원이 유지되는 내내 RAM에 저장된다. 컴퓨터가 발전하면서 CPU의 처리속도가 RAM에 비해 훨씬 빨라져 왔기 때문에 CPU가 RAM에 접근할 때 병목현상이 일어나게 되었다. 이를 방지하고자 CPU와 RAM 사이에 용량은 작지만 속도가 빠른 작은 메모리를 탑재했는데 이것이 바로 캐시다. 캐시에는 CPU 캐시, 디스크 캐시, 브라우저 캐시 등 다양한 종류가 있다.
1. 브라우저 캐시 확인
브라우저는 일정 기간 동안의 DNS 기록들을 저장하고 있기 때문에 컴퓨터는 주소창에 입력된 주소를 브라우저 캐시에서 가장 먼저 확인한다.
2. OS 캐시 확인
브라우저 캐시에서 해당 IP를 발견하지 못했다면, systemcall을 통해서 OS가 저장하고 있는 DNS 기록들의 캐시에 접근한다.
- systemcall: 운영체제의 수준에서 커널 영역을 사용자 모드의 프로그램이 사용할 수 있게 해주는 기능
3. router 캐시 확인
OSI 7계층 중 데이터 통신계층에 있는 라우터에 들어있는 DNS 캐시를 확인한다. router에서도 DNS 주소가 없다면 ISP까지 올라가 확인하게 된다.
4. ISP 캐시 확인
ISP는 인터넷 망을 제공해주는 KT, SKT와 같은 업체를 말하는 것으로, 이러한 ISP들은 DNS 서버를 구축하고 있으며, 마지막 단계이다.
3. ISP의 DNS 서버가 보내는 DNS query
ISP가 제공하는 DNS 서버를 DNS recursor라고 하고 다른 DNS 서버를 name server라고 한다. 어느 곳의 DNS 캐시에서도 DNS 정보를 찾아내지 못했다면 ISP에서 제공하는 DNS 서버(DNS recursor)에서 다른 DNS 서버들로 해당 DNS 정보를 찾으려 DNS query를 보낸다. IP 주소를 찾을 때까지 계속 다른 DNS 서버들을 오가며 찾거나 에러를 내거나 한다.
쿼리로 검색하는 과정은 다음과 같다. 우선 도메인 이름 구조에 기반하여 검색한다.

위 사진을 참고해서 www.google.com 이라는 도메인을 분석 해보면, DNS recursor에서 root name server로 연락을 한다. root name server는 .com 도메인 서버로 접근한다. .com 도메인 서버는 google.com 도메인 서버로 접근한다. google.com 네임서버는 www.google.com에 매칭되는 IP 주소를 찾고 DNS recursor로 보내게 된다
이러한 모든 과정은 작은 패킷으로 전달되는데 이 패킷 안에는 DNS query와 DNS recursor의 IP 주소가 포함된다. 이러한 패킷이 이동할 때에 Routing table을 이용하는데 우리가 알고 있는 라우터에는 이러한 라우팅 테이블이 있어 경로 정보를 등록하고 관리해서 최단 경로를 찾을 수 있다. 이 패킷들이 중간에 유실되면 request fail error가 발생하게 된다.
4. 브라우저와 서버가 TCP connection
TCP/IP란?
컴퓨터들끼리 네트워크로 소통을 할 때 필요한 통신규약을 말한다. IP 주소 지정 방법, 떨어진 상대를 찾기 위한 방법과 그곳에 도달하는 순서, 그리고 웹을 표시하기 위한 순서들에 대해 정의한 규칙이다. 이러한 통신규약에는 여러 가지가 있는데 대표적인 것이 HTTP 프로토콜이고, IP 프로토콜을 사용하는 모든 프로토콜을 총칭하여 TCP/IP 프로토콜이라고 한다.
브라우저가 올바른 IP 주소를 받게 되면 IP 주소에 해당하는 서버와 connection을 빌드하게 된다. 브라우저는 인터넷 프로토콜을 사용해서 서버와 연결이 된다. 인터넷 프로토콜의 종류는 여러가지가 있지만, 웹사이트의 HTTP 요청의 경우에는 일반적으로 TCP를 사용한다.
클라이언트와 서버 간의 데이터 패킷들이 오가려면 TCP connection이 되어야 하는데 TCP/IP three-way handshake라는 프로세스를 통해 클라이언트와 서버 간의 신뢰할 수 있는 connection이 이뤄지게 된다.
- 클라이언트 머신이 SYN 패킷을 서버에 보내고 connection을 열어달라고 물어본다.
- 서버가 새로운 connection을 시작할 수 있는 포트가 있다면 SYN/ACK 패킷으로 대답을 한다.
- 클라이언트는 SYN/ACK 패킷을 서버로부터 받으면 서버에게 ACK 패킷을 보낸다.
이 과정이 끝나면 TCP connection이 완성된다.
5. 브라우저가 웹 서버에 HTTP 프로토콜에 따른 요청을 한다.
TCP로 연결이 되었다면 이제 데이터를 전송하면 된다.
클라이언트의 브라우저는 GET 요청을 통해 서버에게 www.google.com의 웹페이지를 요구한다. 요청을 할 때 비밀 자료들을 포함하든지, from을 제출하는 상황에서는 POST 요청을 사용할 수도 있다. 이 요청을 할 때는 다른 부가적인 정보들도 함께 전달이 된다.
- brower identification(User-Agent헤더)
- 받아들일 요청의 종류(Accept 헤더)
- 추가적인 요청을 위해 TCP connection을 유지를 요청하는 connection 헤더
- 브라우저에서 얻은 쿠키 정보
6. 서버가 request를 처리하고, response를 생성한다.
서버는 웹서버를 가지고 있다.(i.e.Apache,IIS...) 이들은 브라우저로부터 요청을 받고 request handler한테 요청을 전달해서 요청을 읽고, response를 생성하게 된다. Request handler란 ASP.NET, PHP, Ruby 등으로 작성된 프로그램을 의미한다. 이 request handler는 요청과 요청의 헤더, 쿠키를 읽어서 요청이 무엇인지 파악하고 필요하다면 서버에 정보를 업데이트 한다. 그 다음에 response를 특정한 포맷으로(JSON, XML, HTML) 작성한다.
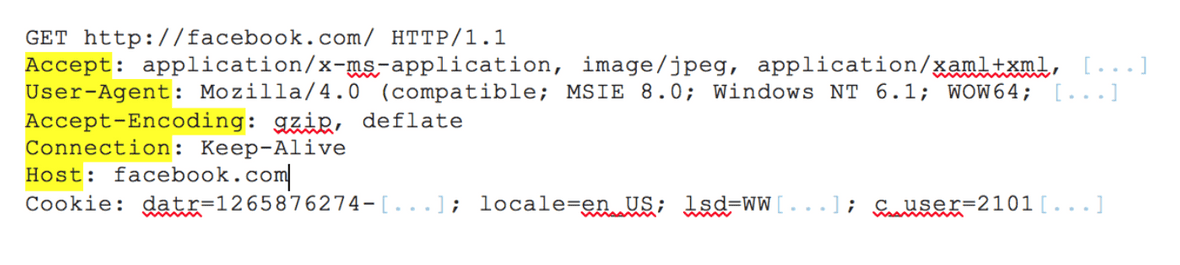
7. 서버가 HTTP response를 보낸다.
서버의 response에는 요청한 웹페이지, status code, compression type(Content-Encoding) - 어떻게 인코딩 되어 있는지, 어떻게 페이지를 캐싱할지(Cache-Control), 설정할 쿠키가 있다면 쿠키, 개인정보 등이 포함된다.
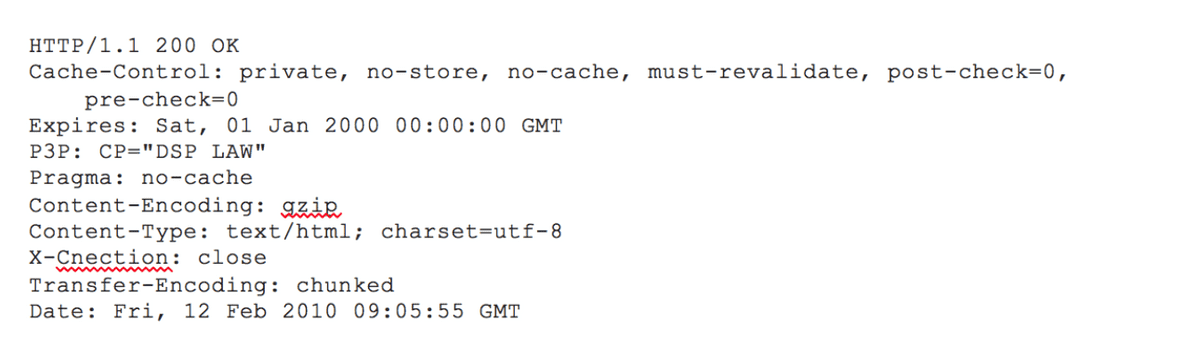
8. 브라우저가 HTML content를 보여준다.
브라우저는 HTML content를 단계적으로 보여준다. 처음에는 HTML의 스켈레톤(기본 틀이라고 보면 될 듯하다)을 렌더링한다. 그 다음에는 HTML tag들을 체크하고 나서 추가적으로 필요한 웹페이지 요소들을(이미지, CSS 스타일시트, Javascript 파일 등) GET으로 요청한다. 이 정적인 파일들은 브라우저에 의해 캐싱이 돼서 나중에 해당 페이지를 방문할 때 다시 서버로부터 데이터를 요청하지 않도록 한다.
이런 과정을 거치고 나서야 www.google.com의 모습이 보이게 된다.
참고
