알고리즘
1.알고리즘 - 선택정렬

배열에서 작은 값을 갖는 데이터를 선택하여, 앞으로 보내는정렬min 값을 찾아야하기 때문에 배열의 끝까지 탐색을 해야한다.위와 같은 배열이 존재 했을 때, 먼저 index 0 부터 배열의 마지막 인덱스 까지 가장 적은 값(min)을 갖는 데이터를 찾는다.min 값과
2.알고리즘 - 삽입정렬
배열의 앞 요소 부터 차례대로 이미 정렬된 배열 부분과 비교하여, 맞는 위치를 찾아 삽입맞는 위치에 삽입된 요소는 정렬 되어있다.위와 같은 배열이 존재할때,요소 1(index 1)을 index 0과 비교하여 작으면, swap 한다.요소 2(index 2)를 index
3.알고리즘 - 버블정렬
서로 인접한 두 요소를 비교하여, 정렬하는 알고리즘큰 수 부터, 오른쪽에 정렬된다.인접한 두 수를 비교하여, 크기 순으로되어있지않으면, 스왑한다.위와같은 배열이 존재할때,1번째 요소와 2번째 요소를 비교, 크기순으로 스왑2번째 요소와 3번째 요소를 비교, 크기순으로 스
4.알고리즘 - 퀵정렬
분할 정복 알고리즘의 하나로, 평균적으로 매우 빠른 알고리즘 이다.분할 정복문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략대개 순환 호출을 이용하여 구현된다. 5, 1, 2, 8, 7, 3, 9, 6, 10, 4 위와
5.알고리즘 - 합병 정렬
분할 정복 알고리즘이며, 안정적인 정렬이서 최악, 최선의 경우에도 시간복잡도는 N \* log N를 갖는다.합병정렬은 추가적인 메모리가 필요하다는 단점이 있다.보통 재귀 함수로 구현한다. 5, 1, 2, 8, 7, 3, 9, 6, 10, 4 리스트의 같은 깊이의 나눠지
6.알고리즘 - 너비우선 탐색(BFS)
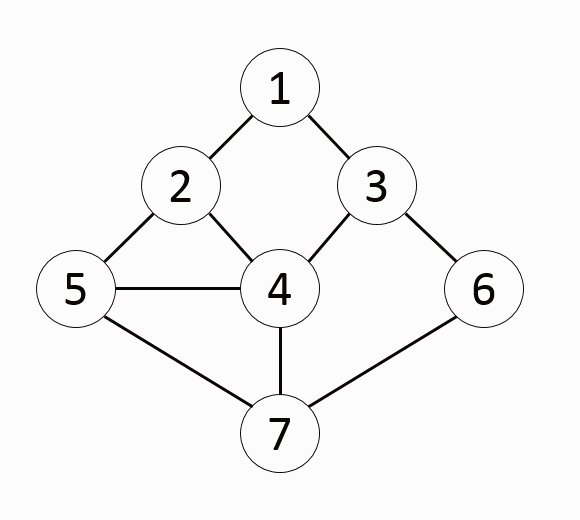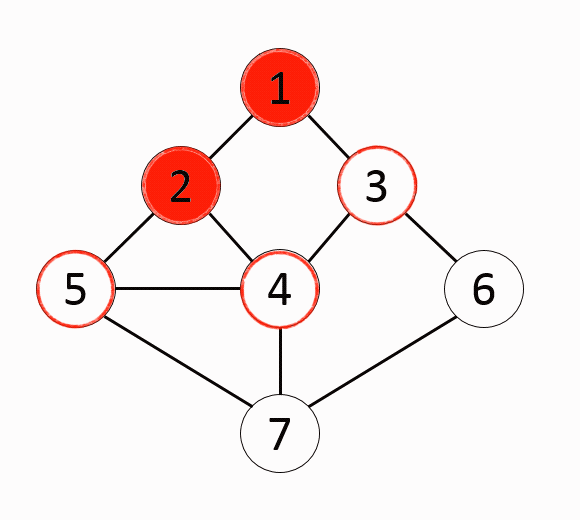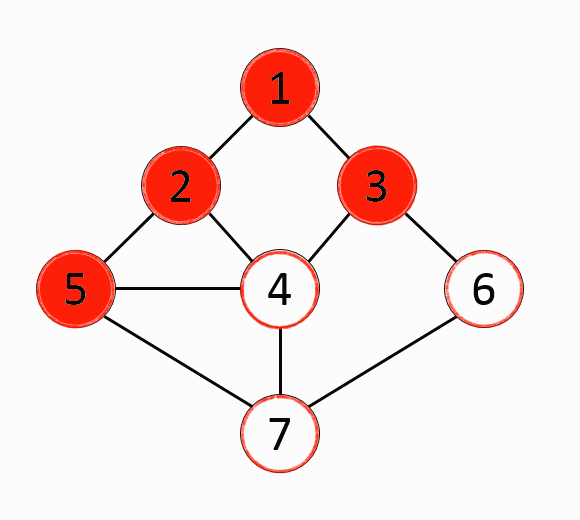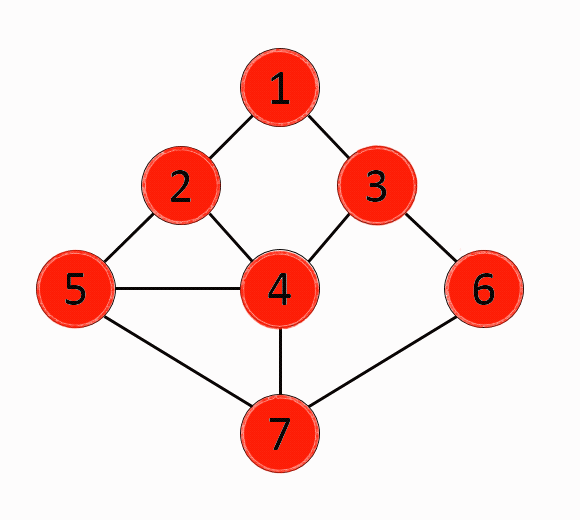
그래프에서 시작 노드에 인접한 노드부터 탐색하는 알고리즘BFS알고리즘은 모든 간선의 비용이 동일한 조건에서 최단 거리를 구하는 문제에 효과적인 알고리즘미로를 빠져나가는 최단 거리 구하는 문제등에서 효과적인 알고리즘시작 노드를 큐(Queue)삽입하고 방문처리큐에있는 노드
7.알고리즘 - 깊이우선 탐색(DFS)
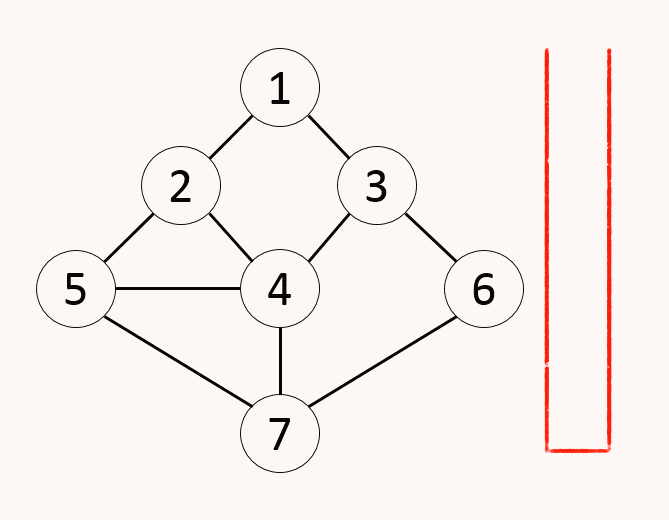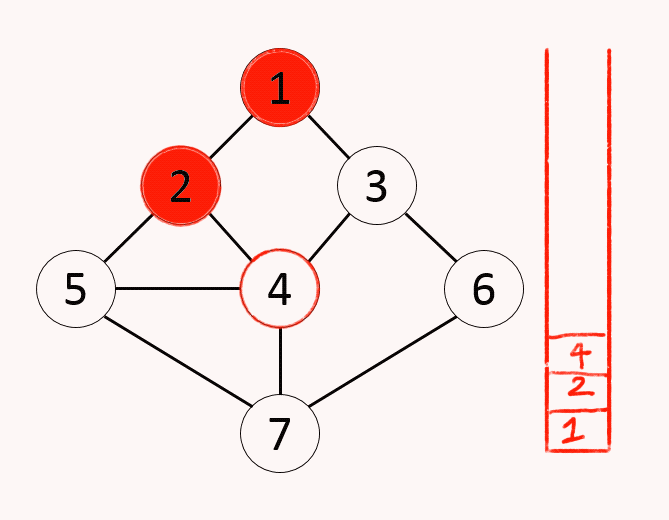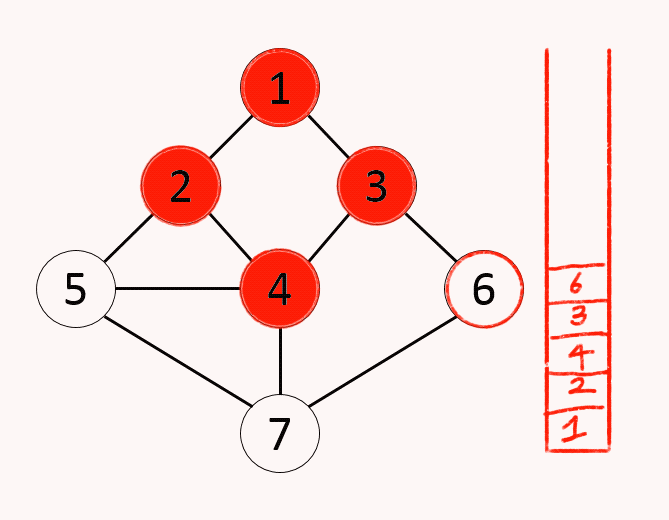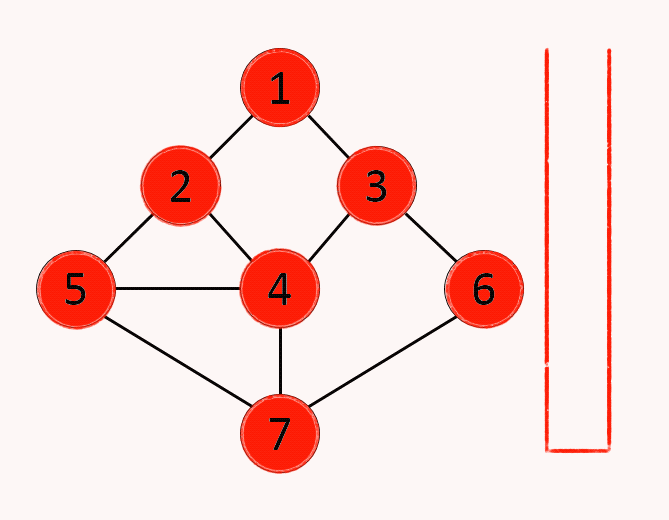
그래프에서 시작 노드에 인접한 노드부터 깊이를 우선하여 탐색하는 알고리즘컴퓨터는 구조적으로 스택의 원리 이용하기에 자료구조 스택없이 구현이 가능(재귀호출)단순 검색 속도 자체는 BFS에 비해 느림스택의 최상단 노드를 확인최상단 노드에게 방문하지 않은 인접 노드가 있으면