
Springboot 동작원리
1. 내장 톰켓을 가진다.
웹서버는 자바 코드가 추가된 파일 요청이 오면 응답하지 못하기 때문에 톰켓이 필요하다. 웹서버가 이해하지 못하는 파일에 대한 요청이 오면 제어권을 톰켓에게 넘긴다.
🔸 톰켓은 파일안에 있는 모든 자바코드를 컴파일하고 컴파일이 끝나면 컴파일된 데이터를 html 문서로 만들고 웹서버에게 넘겨준다.
Soket
운영체제가 가지고 있는 것으로 프로그램과 프로그램, PC와 PC간의 통신을 말함.
ex) A <- 메세지 교환 ->B
A (소켓 오픈 포트번호 5000) A와 연결하고 싶은 B는 ip주소와 포트번호 5000번 연결하면 서로 통신 가능.
소켓통신을 이용하면 timeslice, 스레드를 이용해서 동시동작하는것처럼 가능하다.
장점 : 연결이 계속되어 있다.
단점 : 부하가 크다. 느려질 수 있음.
HTTP
문서를 전달하는 통신으로 http 통신은 stateless 방식을 사용한다.
장점 : 부하가 적다.
단점 : 비연결형이기 때문에 다시 연결될때 새로운 것으로 인식하게 됨.
http 확장자로 만들어진 문서를 필요한 사람에게 전송의 목적으로 만들어짐
웹서버
내 컴퓨터 <---요청 request, IP주소, URL(자원을 요청하는 주소L : location)--- 다른 컴퓨터
내 컴퓨터 ---응답 response (static 자원) ---> 다른 컴퓨터
요청할 때 만 주소가 필요하다. 그러므로 요청하지 않았을 때 응답할 수 없다.
2. 서블릿 컨테이너
자바코드로 웹을 할 수 있게 컨테이너로 모아놓은 것 -> 톰켓
Servlet(서블릿)
자바를 사용하여 웹을 만들기 위해 필요한 기술로 클라이언트의 요청을 처리하고, 그 결과를 반환하는 자바 웹 프로그래밍 기술
client request(자바) -> 서블릿 컨테이너 ->
최초요청
-> yes -> 스레드 생성 -> 서블릿 객체 생성 -> response
-> no -> 기존에 있는 스레드 재사용
Sevice(HttpServletRequest, HttpServletResponse) 톰켓이 생성함.
💡 동시에 수백,수만명의 요청이 발생할때마다 스레드와 서블릿 객체 생성 (동시 접근허용), 정해놓은 스레드 만큼 만들어지고 만들어진 스레드는 재사용된다. -> 속도 향상
URL
자원 접근 주소요청 방식 --> 스프링에서는 사용X
ex) http://naver.com/a.png
URI
식별자를 통해 접근하는 방식 --> 스프링에서 사용O
특정한 파일 요청을 할 수 없다.
요청시에는 무조건 자바를 거친다. -> 무조건 제어권을 톰켓에게 넘긴다.
ex) http://naver.com/Picture/a
3. web.xml
웹서버에 진입 시 최초로 실행, 웹실행 시 문지기같은 역할
- SevletContext의 초기 파라미터
초기 파라미터는 한번 설정해놓으면 어디에서든지 동작가능 - Session의 유효시간 설정
- Servlet/JSP에 대한 정의
- Servlet/JSP 매핑
모든 클래스에 매핑을 적용시키기에는 코드가 복잡해지기 때문에 FromtController 패턴 이용 - Mime Type 매핑
💡 Mime Type : 들어오는 데이터 타입을 알아야 가공 가능 - Welcome File list
- Error Pages 처리
- 리스너/필터 설정
필터 : 값이 들어올때 필터를 통해서 걸러내는 역할 - 보안
4. FrontController 패턴
🔸 web.xml에 다 정의하기 힘들기 때문에 최초 앞단에서 request 요청을 받아서 필요한 클래스에 넘겨준다.
이때 새로운 요청이 생기기 때문에 request와 response가 새롭게 new 될 수 있다.
그래서 아래의 RequestDispatcher가 필요하다.
request -> 웹서버(URI or 자바파일 -> 톰켓(web.xml -> FromtController(특정 주소를 가져가서 내부에 어떤 자원을 찾아갈 수 있게 request를 한번 더 진행))
톰켓이 request(요청한 사람 정보, 들고온 데이터), response(응답해야할 객체) 자동으로 만든다.
💡 request는 진행될때마다 바뀌는데 다시 request를 진행할 때 기존에 request 정보를 유지 작업이 필요하다. -> RequestDispatcher 이용
5. RequestDispatcher
필요한 클래스 요청이 도달했을 때 FrontController에 도착한 request와 response를 그대로 유지 시켜준다.
데이터를 들고 페이지를 이동할 수 있도록 도와준다.
6. DispatchServlet
FrontController 패턴을 직접짜거나 RequestDispatcher를 직접구현할 필요가 없다. 왜냐하면 스프링에는 DispatchServlet이 있기 때문이다.
🔸 DispatchServlet = FrontController 패턴 + RequestDispatcher
DispatchServlet이 자동생성되어 질 때 수 많은 객체가 생성(IoC)된다. 보통 필터들이다. 해당 필터들은 내가 직접 등록할 수 도 있고 기본적으로 필요한 필터들은 자동 등록 됨.
DispatchServlet 목적
컴포넌트 스캔 -> IoC 역할을 해준다. -> 필요한 것들을 (필요한 것은 어노테이션으로 구분해서 선택) 메모리에 올려줌(new 해줌) -> 주소분배
7. 스프링 컨테이너
DispatchServlet에 의해 생서되어지는 수 많은 객체들은 어디에서 관리될까?
🔸 request(요청) -> web.xml -> ContextLoaderListener (ApplicationContext 로드 -> root-context.xml 로드(DB관련 객체 생성)) -> servlet-ApplicationContext 호출 -> DispatchServlet (컴포넌트 스캔 -> 메모리에 올림 -> 주소분배)
ContextLoaderListener
모든 스레드가 공통적으로 사용해도 되는 것 (DB에 관련된 것)
root-ApplicationContext 파일을 읽음 (공통적으로 사용하는 스레드를 메모리에 올려줌)
ApplicationContext
수 많은 객체들이 ApplicationContext에 등록되고 필요한 곳에서 ApplicationContext에 접근하여 필요한 객체를 가져올 수 있다. 이는 싱글톤으로 관리되기 때문에 어디에서 접근하든 동일한 객체라는 것을 보장해준다.
종류 : servlet-applicationContext, root-applicationContext
-
servlet-applicationContext
웹과 관련된 정보 즉 웹과 관련된 어노테이션만 스캔(메모리에 로딩)해서 올린다. -
root-applicationContext
DB관련된 객체 생성
Bean Factory
필요한 객체를 Bean Factory에 등록할 수 도 있다.
@Configuration
Class A {
@Bean
객체 메소드();
return 객체();
}초기에 메모리에 로드되지 않고 필요할 때 getBean()이라는 메소드를 통하여 호출하여 메모리에 로드
8. 요청 주소에 따른 적절한 컨트롤로 요청(Handler Mapping)
Get요청 -> http://localhost:8080/post/1 (URI)
해당 주소 요청이 오면 적절한 컨트롤러의 함수를 찾아서 실행
9. 응답
- html 파일을 응답
ViewResolver(파일위치와 확장자를 앞뒤로 붙여줌)가 관여하게 된다. - Data를 응답 (객체)
MessageConverter가 작동하게 되는데 메시지를 컨버팅할 때 기본전략은 json이다.
💡 전체적인 로직 💡
톰캣 실행 시 ▶ 1. web.xml ▶ 2. ContextLoaderListener ▶ 3. applicationContext.xml ▶ 4. (root-context.xml)SeviceImpl, DAO, VO 메모리 로딩 ▶ 5. request 요청 ▶ 6. (servlet-context.xml)DispatchServlet (web.xml역할 분배받아 컴포넌트스캔, 주소분배) ▶ 8. 메모리에 올리기 (주소분배) ▶ 9. html파일리턴? Data리턴? 선택 후 response 응답
💡 Springboot 로직
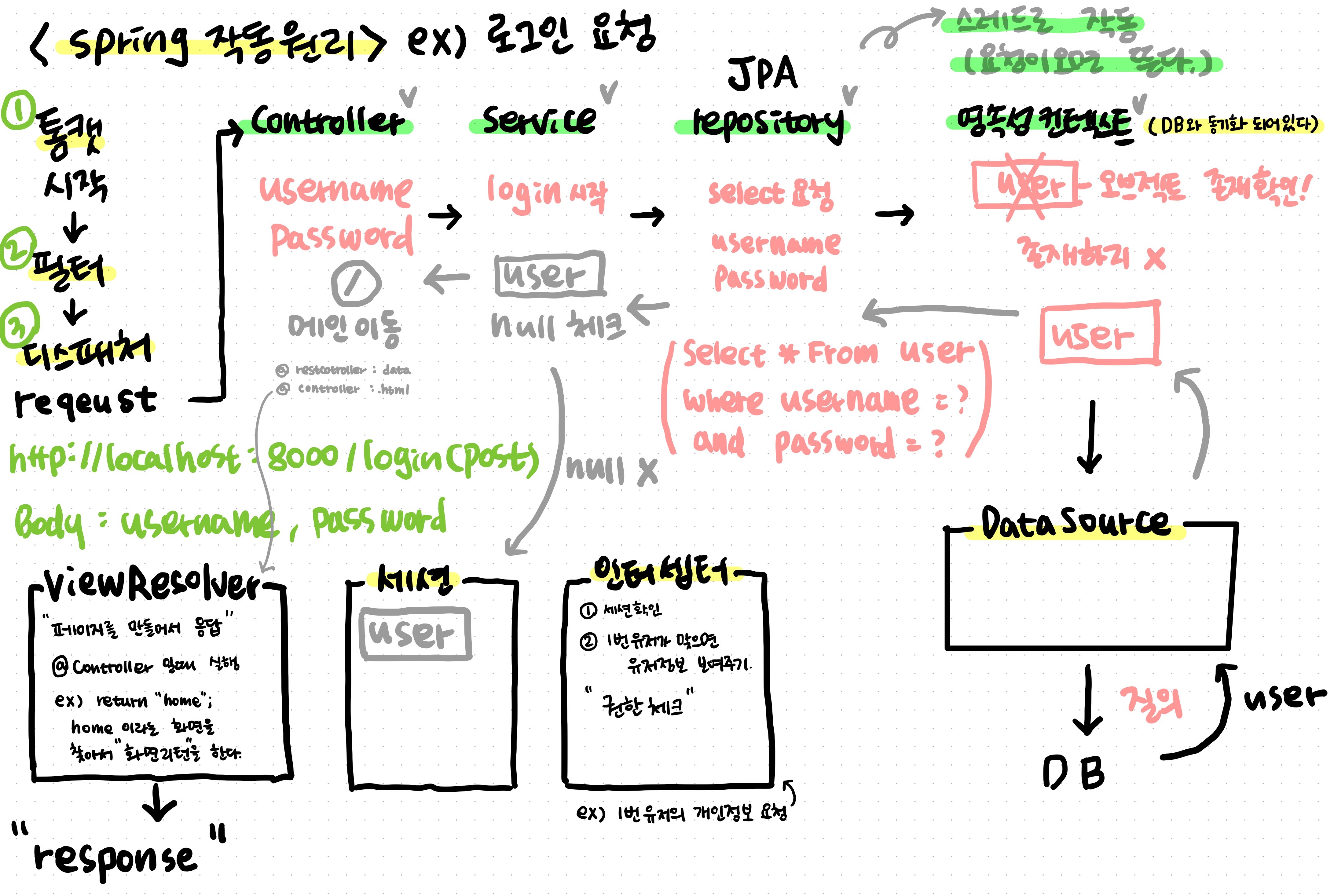
EX) 로그인요청 로직으로 알아보는 작동원리
-
클라이언트 요청
http://localhost:8000/login (post방식) Body data : username, password -
톰캣 시작, 필터, 디스패쳐, 세션, 인터셉터, Datasource 메모리 로딩
-
요청이 오면 controller, Service, repository(JPA)가 스레드로 작동한다.
(다른 사용자가 요청 할때마다) -
controller는 username, paseword를 @PostMapping(주소) 찾음
-
Service는 login() 시작
-
repository는 해당 username과 password가 맞는지 select 요청
-
DB전에 영속성 컨텐스트에 해당 user 오브젝트가 있는지 확인하고 없으면 영속성 컨텍스트가 DataSource가 DB에서 user 오브젝트를 받아 영속석 컨텐스트에 보냄
-
해당 user 오브젝트를 Service에 보내고 Service는 해당 user가 존재하는지 여부를 판단하여 user가 존재한다면 세션에 저장한다.
8-1. Service가 종료될때 트랜잭션이 종료되면서 Commit -> DB update가 일어난다. -
이러한 로그인 로직이 끝났다면 마지막에 controller로 와서 마지막 반환이 data라면(@RestController) 데이터 리턴하고 종료.
9-1. 반환이 .html 화면이라면(@Controller) viewResolver가 실행되며 해당 화면을 찾아 화면을 리턴한다.
Service
- 트랜잭션의 시작과 종료
- 트랜잭션의 정상 수행 ▶ commit ▶ 서비스 종료
- 하나라도 처리되지 않았을 때 모두 Rollback 처리
- DB에 필요한 질의요청을 repository(JPA)에 요청
- 트랜잭션 처리 ▶ 어떤 하나의 기능 ▶ DB 요청
- 여러가지 DB 요청들을 하나의 pakage에 담고 있다.

{kind=link}