YOLO라고 불리는 You Only Look Once 논문에 대해서 읽었다. YOLO는 계속해서 진화하여 V8까지 나왔는데, 그중에서 초석인 V1논문에 대해서 작성해보도록 하겠다.
Abstract
기존에 있는 object detection model들은 (여기서는 R-CNN, DPM으로 비교를 많이 함) detection을 수행하기 위해서 classifier 문제로 해결한다. 반면에 YOLO는 detection을 위해서 regression 문제를 이용해서 문제를 해결한다.
또한 Detection pipeline이 single neural network이기 때문에 end-to-end에 최적화 될 수 있으며, bounding box와 class probabilities를 한 번에 predict 할 수 있다.
이 논문에서 YOLO는 빠르다는 장점을 계속해서 어필한다. YOLO는 45fps를 처리하며, Fast YOLO는 155fps를 처리한다. 반면에 다른 detection model보다는 localization error가 더 많이 발생하는데 single neural network로 처리하기 때문이다. (정확도가 낮기 때문에 빠르다는 장점을 계속 어필하는 것 같기도 하다.)
Introduction
DPM은 sliding window 방식(bounding box가 전체적인 이미지를 훑는 방식)으로, R-CNN은 region proposal 방식(object가 있을법한 영역을 표시하는 방식)으로 object detection을 수행한다. 이 두 방식은 모두 classification을 수행하고 bounding box를 만드는 방식이다. 이러한 여러개의 pipelines은 각각의 component들을 따로 따로 훈련되기 때문에 최적화하는데 느리고 어렵게 한다. (These complex pipelines are slow and hard to optimize because each individual component must be trained separately.)

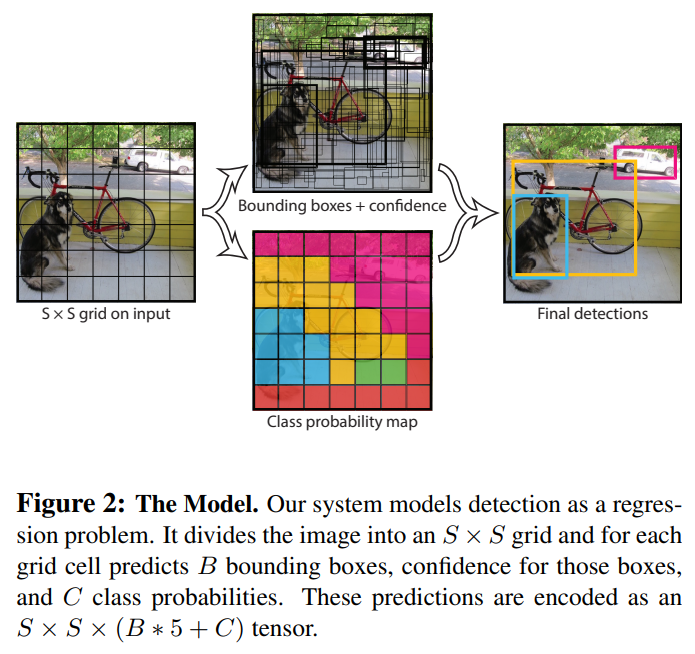
YOLO는 single convolution network로 동시에 여러개의 bounding box와 그 box들에 대한 class probabilities를 만든다. 위에 그림을 보면 YOLO Detection system을 볼 수 있다.
(1) 448x448로 이미지를 resize한다.
(2) single convolution network에 실행시켜서 여러개의 bounding box와 class probabilities를 만든다.
(3) Non-max suppression 알고리즘을 이용해서 bounding box를 class당 하나만 만든다.
- Non-maximum suppression 알고리즘이란?
여러개의 bounding box중에서 신뢰도가 높은 것을 남기는 알고리즘이다.
Bounding box의 집합을 B, B의 confidence score를 S, overlap threshold의 값을 N이고, 최종적으로 남길 bounding box list인 D를 output으로 알고리즘을 실행한다.
- 각 cell마다 특정 confidence score가 낮은 box 버린다.
-> 완전히 쌩뚱맞은 box를 버리는 작업 - B중에서 confidence score가 가장 높은 bounding box를 선택한다. 이 box를 B에서 삭제하고 output인 D에 넣는다.
-> 해당 box는 최종적으로 화면에 나올 box이다. 해당 box와 B에 있는 다른 box와 비교를 통해 IOU를 얻는다. - D에서 confidence score가 가장 높은 것을 선택하고 해당 box와 IOU를 비교하여 N보다 크면 해당 box를 B에서 제거한다.
-> 처음엔 왜 낮은 값이 아닌 높은 값을 제거하나 생각했는데, 이미 나올 bounding box는 정해져있기 때문이라는 답을 얻었다. 나올 box는 정해져 있는데 B의 box와 D의 box의 IOU가 높다는 것은 비교를 당한 B의 box도 해당 class의 bounding box라는 의미이다. 하나의 class에는 하나의 bounding box만을 남겨놔야하므로, 비교 당한 B box를 지워야 해당 class에 대한 bounding box를 하나만 나타낼 수 있다. (쉽게 얘기해서 D에 있는 box 하나만 남겨야 함) - 다시 B로 가서 높은 box를 D에 넣고 해당 과정을 다시 반복한다.
- B가 없을 때까지 반복한다.
이를 슈도코드로 나타내면 아래와 같다.

가 output인 D에 해당하고 B는 B, 는 B에 있는 bounding box값 (x, y, w, h, confidence score)
임계값()을 설정하는 것이 까다롭기 때문에 이를 보완하기 위해서 Soft-NMS 방식이 있다. (나중에 공부할 것!)
이제 논문에서 말하는 YOLO의 장점에 대해서 얘기해보도록 하겠다.
1. YOLO는 매우매우 빠르다. (First, YOLO is extremely fast.)
이 논문에 강력하게 주장하는 장점으로 YOLO는 detection을 regression problem으로 정의하기 때문에 복잡한 pipeline이 없다. 때문에 single neural network를 이용하며 초당 45frame을 처리할 수 있다. Fast YOLO 초당 150frame이 가능하며 이는 real-time system에서 처리가 가능한 속도이다. 다른 real-time system과 비교하면 mean average precision(mAP)가 2배는 높다. (아래에 Table 1)
2. YOLO는 예측을 할 때 이미지를 국소적으로 보는 것이 아닌 전체적인 이미지를 본다. (Second, YOLO reasons globally about the image when making predicitons.)
Sliding window 방식(DPM)과 region proposal 방식(R-CNN)달리 YOLO는 전체적인 이미지를 본다. 때문에 문맥적(contextual)으로 정보를 파악할 수 있고, 이로 인해 배경을 class로 인식하는 background error가 R-CNN보다 낮다.
3. YOLO는 일반화된 object의 representations를 학습할 수 있다. (Third, YOLO learns generalizable representations of objects.)
YOLO는 자연(natural)과 예술(artwork)image에 대해서 R-CNN과 DPM보다 더 높은 성능을 보인다.
-> Generalization(일반화): 개별적인 것이나 특수한 것이 전체에 두루 통하는 것으로 되다. 또는 그렇게 만들다. -> 피카소의 그림이나 뭉크의 그림과 같이 현실주의적인 그림이 아닌 추상적인 그림을 생각해보자. 사람을 그린다고 했을 때, 사람이 그림마다 다르고, 표현이 다르다는 것을 알 수 있다.(눈이 입에 붙어있거나 코가 옆에 달려있거나 등등) YOLO는 이 그림들을 일반적인 사람으로 학습을 할 수 있다는 말이다.
Unified Detection
YOLO를 unified model이라고 하는데, 이는 bounding box와 class probability를 동시에 예측하기 때문인 것 같다.
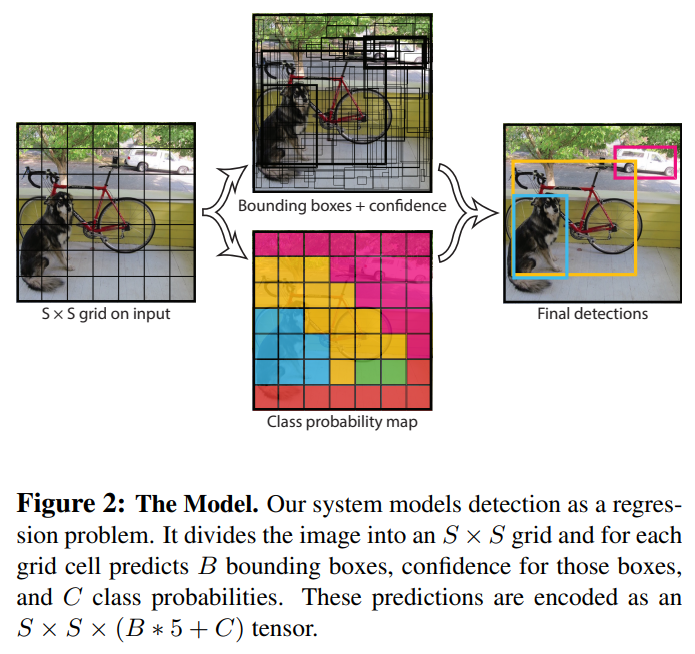
Input image를 SxS개의 grid cell로 나눈다. 만약 object의 중심이 어떤 grid cell에 있다면, 해당 grid cell을 'responsible'하다고 정의한다.
각각의 grid cell은 B개의 bounding box를 만들고 해당 box의 confidence score를 예측한다.
Confidence score는 Pr(object) * IOU로 정의한다. (Pr(object)는 object가 없으면 0, 있으면 1의 값을 갖는다.)
- IOU 는 정답인 ground truth와 예측값인 pred의 bounding box를 가지고 평가하는데, 두 bounding box의 intersection(교집합)을 union(합집합)으로 나눈다.
-> 궁금한 것: ground truth는 정답값인데, real-time이나 새로 들어오는 image에 대해서의 ground truth는 주어지지 않는데, 도대체 어떻게 정의가 되고 계산이 되는 것인가?? -> 예측 과정에서는 ground-truth 없이 오로지 학습된 가중치 값들로만 예측을 진행한다.
만약 object가 grid cell에 없다면 Pr(object)는 0이기 때문에 해당 confidence score도 0이다.
각각의 bounding box B는 5개의 값을 갖는다; Object가 있을시, 해당 object의 중심 좌표인 (x, y), 전체적인 이미지를 기준으로 예측한 width와 height, 마지막으로 confidence 값을 갖는다. (x, y, w, h, confidence score)
각각의 grid cell은 C의 조건부 확률(Pr(Class|Object))을 갖는다. Pr(Class|Object)는 물체가 있을 때 그 물체가 어떤 class인지 예측하는 값이다. B의 개수와 상관없이 각각의 grid cell마다 class probabilities의 한 세트를 가지고 있다. -> 한 개의 값을 가지는게 아니라 class개수만큼 Pr(Class|Object)을 가지고 있는 것 -> S x S x (B * 5 + C) tensor에서 C에 해당하는 값
At test time(모르는것: test time이 무엇인가?? train과정의 반대를 뜻하는 건지 모르겠음), Pr(Class|Object)의 값에 confidence 값을 곱하게 되는데 이는 class-specific confidence score (Pr(class) * IOU)값을 얻게 된다.
-> Pr(Class|Object) * Pr(object) * IOU = Pr(class) * IOU
이 값은 box에서 나타나는 각각의 class가 나타날 확률과 예측한 box가 얼마나 잘 들어맞는지를 나타낸다.
예시를 통해서 보면
S = 7 -> 각각의 grid box는 7x7 = 49개이다.
B = 2 -> 각각의 grid cell이 2개의 bounding box를 만든다. (총 S x S x B개 만큼의 bounding box가 생성, 여기서는 98개)
C = 20 -> 20개의 class가 있다.
따라서 최종 결과 값은 S x S x (B * 5 + C) tensor -> 7 x 7 x (2 * 5 + 20) tensor값을 갖는다.
각각의 grid cell에 대해서 bounding box B개씩 5개의 결과 (x, y, width, height, confidence score)를 가지고 C개의 Pr(Class|Object)를 갖는다.
Network Design

YOLO의 network는 GoogLeNet에서 영감을 받아서 제작하였으며, inception modules을 사용하는 대신에 1x1 convolution을 사용하였다. 24개의 convolution layers와 2개의 Fully Connected Layers를 사용하여 총 26개의 Single Neural Network를 사용하였다. (Fast YOLO는 24개의 convolution 대신에 9개의 convolution을 사용하였다.)
Convolution layers에서 image의 features를 추출하고 Fully connected layers에서 output의 probabilities와 coordinates값을 예측한다. 최종적으로 위에서 언급한대로 7x7x30의 tensor를 갖는 것을 알 수 있다.
Training
먼저 pretrain을 통해 features 추출하기 위해서 20개의 convolution layers를 사용하고 이어서 average pooling layer와 FC layer 1개를 사용하였다. 반면에 ImageNet은 classification을 위한 dataset이다. 따라서 pretrained model을 object detection model로 바꾸어야 한다. 이를 위해 weight가 random하게 초기화 된 4개의 convolution layers와 2개의 FC layers를 통해서 detection을 수행한다.
(4개의 convolution layers가 feature 추출이 아닌 detection을 하는지 어떻게 아는지 모르겠음 -> 추후 NOC 논문을 통해서 공부할 것)
세분화된 정보를 얻기 위해서 244x244를 448x448로 해상도를 증가 -> 더 크게, 세세한 특징을 얻기 위해서 사용
앞서 언급한대로 마지막 layer에는 class probabilities와 bounding box의 좌표를 예측하는데, bounding box의 x, y, height, width는 모두 0~1사이로 정규화가 된다.
-> Object들이 어떠한 곳에서든 나올 수 있기 때문
마지막 layer에는 linear activation(y=x)을 사용하고 나머지 layers는 Activation Function으로 Leaky ReLU를 사용
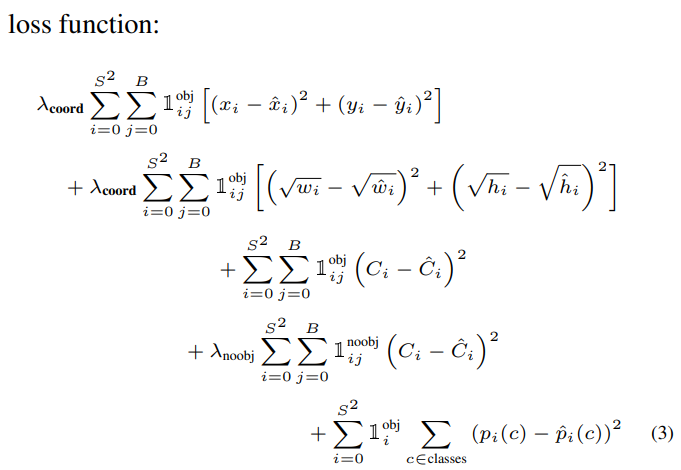
Loss function으로는 SSE기반으로 YOLO model에 맞게 수정하였다.
SSE를 사용하는 이유는 최적화하기 쉽다는 것이지만, mAP를 최대화하려는 목표와는 완벽하게 일치하지 않는다.
(We use sum-squared error because it is easy to optimize, however it does not perfectly align with our goal of maximizing average precision.)
-> Localization error와 classification error가 같으면 안되는데 기존 SSE는 이 둘을 같게 계산하기 때문
-
는 object가 있을 때에 가중치이고, 는 object가 없을 때에 가중치이다.
-> 모든 grid cell들이 object를 포함하지 않는데 object를 포함할때와 포함하지 않을때와 가중치를 다르게 주어야 함. Object가 없는 grid cell이 훨씬 많기 때문에 object가 있는 경우의 가중치가 훨씬 더 커야한다. 같으면 model을 불안정하고 일찍 수렴하게끔 만듦. -
width와 height의 값에는 각각 루트를 씌운다.
-> bounding box의 크기에 따라서 IOU의 값의 변화율이 다르기 때문이다. Bounding box가 크면 조금 겹칠 때 IOU값이 작은데, bounding box가 작으면 조금만 겹쳐도 IOU값이 커지게 된다. 이를 개선하기 위해서 루트를 씌워주었다. -
: i번째 grid cell의 confidence score
-
: i번째 cell에 j번째 responsible한 bounding box인지 (가장 높은 IOU값을 가지는 bounding box)
-
: i번째 cell에 object가 있는지 (0 또는 1)
-
: i번째 grid cell에서 conditional class probability
(1번째 SSE) bounding box를 계산하는 localization loss x, y, w, h
(2번째 SSE) bounding box를 계산하는 localization loss
(3번째 SSE) i번째 grid cell의 bounding box j에 대해서 object가 있을 때, confidence score의 loss
(4번째 SSE) i번째 grid cell의 bounding box j에 대해서 object가 없을 때, confidence score의 loss
(5번째 SSE) i번째 grid cell의 bounding box j에 대해서 object가 있을 때, conditional class probability loss
Inference
훈련단계와 마찬가지로 test image에 대해서 detection을 예측하는 것은 하나의 network evaluation만 해주면 된다. PASCAL VOC에 대해서 YOLO는 98개의 grid box를 만들고 각각의 box에 대해서 class probabilities를 예측해주면 된다.
하나의 object를 여러 cell들이 localization할 수 있는데(multiple detections), 이는 위에서 언급한 NMS 알고리즘으로 해결할 수 있다.
Limitations of YOLO
-
YOLO는 하나의 grid cell에 대하여 하나의 class에 대한 예측을 가진다. 때문에 Spatial constraints문제를 갖게 되는데 이는 '하나의 grid cell은 오직 하나의 object만 detection 할 수 있으므로 하나의 grid에 두 개 이상의 object가 붙어있다면 detection하기 힘들다'는 의미이다. 예를 들어, 새 무리들(flocks of birds)과 같이 여러개의 작은 objects들이 하나의 cell에 붙어있으면(nearby) 전부 예측하기는 힘들다.
-
YOLO는 입력된 data를 가지고 bounding box를 예측하기 때문에 새로운 비율/구성을 가진 값은 예측하기 힘들다.
-
Loss function에서 작은 bounding box와 큰 bounding box에 같은 가중치()를 곱한다는 문제가 있다. 더 작은 bounding box의 loss가 큰 bounding box보다 IOU에 더 민감하게 영향을 주기 때문에 localization에 안 좋은 영향을 준다.(Incorrect localizations)
Comparison to Other Detection Systems & Experiment
앞에서 계속 언급했던 sliding window방식의 Deformable parts models(DPM), region proposal 방식의(selective search) R-CNN을 중점적으로 설명했다.
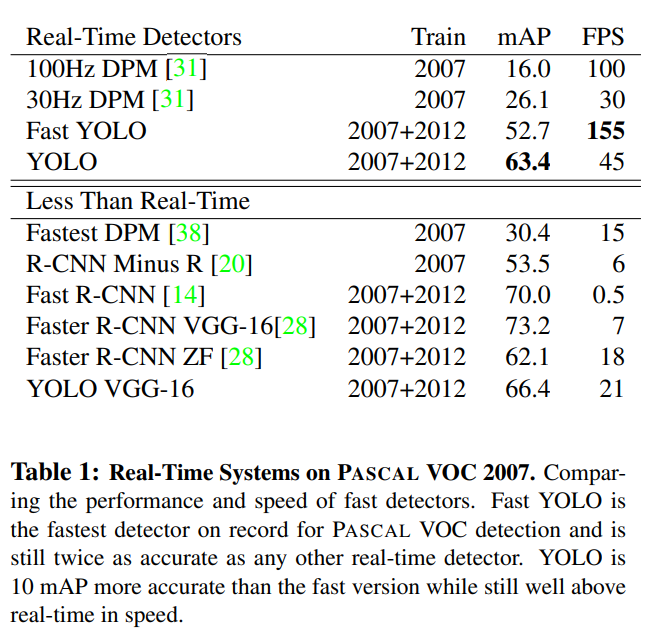
위 표를 통해서 real-time detection model 중에서는 mAP가 가장 높은 것을 알 수 있으며, fps도 굉장히 빠른 것을 알 수 있다.
- real-time은 실시간 처리로서 30fps이상부터 사용이 가능하다.
밑에 VGG-16과 결합한 YOLO model도 준수한 mAP를 기록하는 것을 볼 수 있다.

위 결과를 보면 YOLO 보다는 Fast R-CNN의 correct 비율이 더 높은 것을 알 수 있다. 하지만 뒤에 배경을 class로 인식하는 Background error는 YOLO가 3배나 적은 것을 알 수 있다. 이는 YOLO가 single network로써 image의 contextual information을 보기 때문이다.
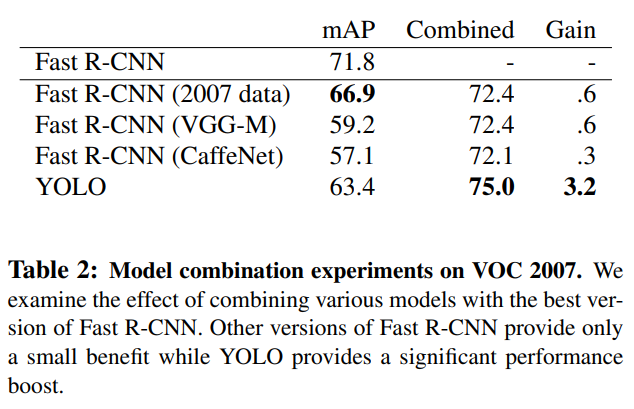
Fast R-CNN과 YOLO를 합치게 되면 3.2%의 성능향상이 나온 것을 알 수 있다.
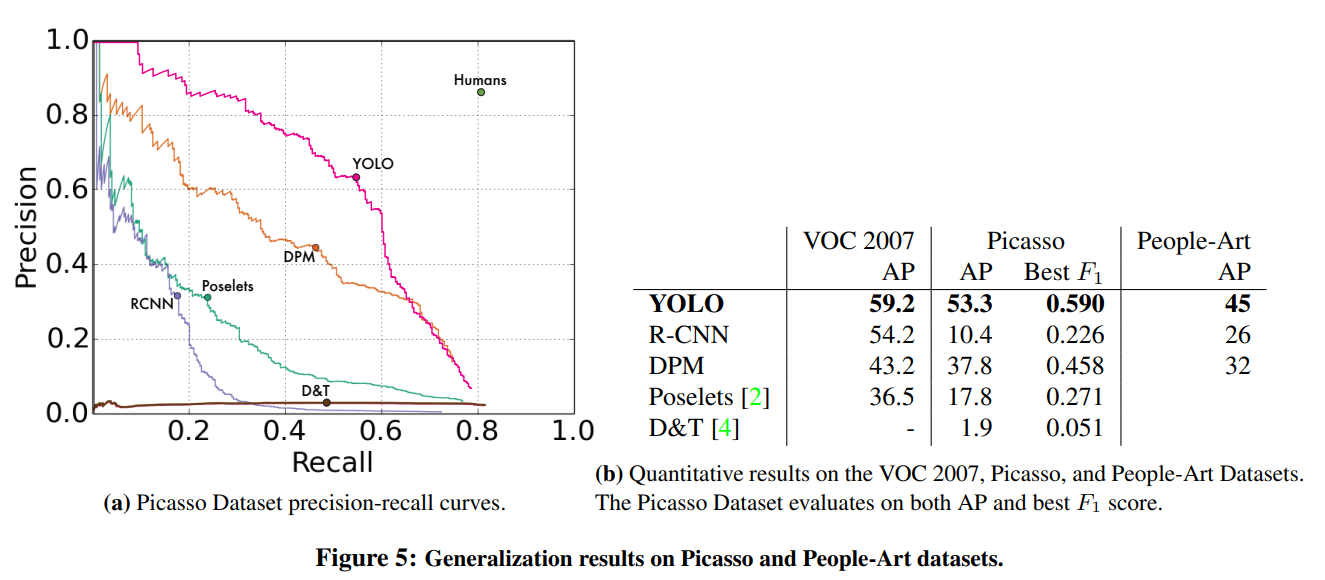
또한 YOLO가 좋은 것이 다른 model들보다 artwork에 대해서는 가장 좋은 성능을 갖는다. 이는 장점 3번에서도 언급했듯이, generalizable representations of objects에 대해서 학습을 할 수 있기 때문이다.

위에 결과처럼 bounding box와 classification이 같이 나오는 것을 알 수 있다.
Conclusion
YOLO는 object detection을 위해서 통합된 model이다. Single neural network로 구성되어서 속도가 굉장히 빠르다는 장점이 있지만 다른 model들 보다는 mAP가 떨어지는 것을 알 수 있다. YOLO는 real-time object detection에서 SOTA에 등록되었다고 한다. 또한 일반화를 잘 할 수 있어, 새로운 도메인에서도 적용 가능하다.
느낀점
원래는 segmentation으로 분야를 정하려고 했는데 detection에 대한 관심이 생겨서 우선 detection을 공부해보려고 한다. 모르는 것이 너무 많아서 걱정이다. 또한 YOLO 논문을 3일만에 읽었다고 하니깐 랩실 사람들이 논문 그렇게 읽는거 아니라고 하셨다. 시험도 보고 질문도 받았는데 내가 너무 대충 공부한게 느껴졌다. 그 과정이 왜 그런지 탐색하고 하나하나 찾아보니 이해가 안되는 많은 내용을 이해하게 되었다.
대충 넘어가는 공부를 하는 것 보다는 꼼꼼하게 공부하고 모르면 알 때까지 공부하는 습관을 가져야겠다.
요번주를 통해서 느낀점
0. 대충 공부하지 않기!
1. 다음 논문은 R-CNN 읽기. R-CNN을 읽고 다시 YOLO 읽어보기
2. 공부는 사람이 있는 곳에서 하기 -> 기숙사나 방에서 혼자x
3. 많은 시간 투자하기
4. 바쁘게 살기..,..! 게을러지지 말자
다음주도 화이팅~
