스토리지 엔진
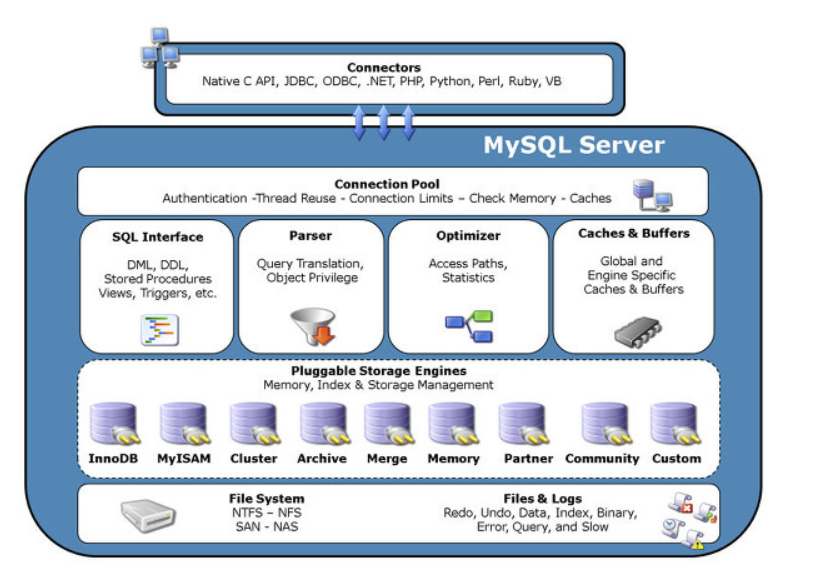
MySQL 서버에서 디스크에 데이터를 저장하거나 읽는 역할을 수행하는 것이 스토리지 엔진이며, 나머지는 MySQL 엔진이다.
MyISAM vs InnoDB
둘 다 MySQL의 스토리지 엔진이다.
MySQL 5.5 버전 이후에는 InnoDB를 기본 스토리지 엔진으로 사용한다.
InnoDB는 트랜잭션 처리가 필요하고, 대용량의 데이터를 다루는 부분에서 효율적이다.
MyISAM은 트랜잭션 처리가 필요 없고, Read 기능이 많은 서비스일수록 효율적이다.
InnoDB
commit, rollback, 장애 복구, 외래 키 등을 지원한다.
다수의 사용자 동시접속에 퍼포먼스를 내도록 설계되었다.
메인 메모리 안에 데이터 캐싱과 인덱싱을 위한 버퍼풀을 관리한다.
테이블과 인덱스를 테이블 스페이스에 저장하고, 테이블 스페이스는 서버파일이나 디스크 파티션으로 구성된다.
MyISAM
가볍다.
전체 문장 검색, 고성능 스토리지 밀 복구를 지원한다.
테이블에 ROW COUNT를 가지고 있어 SELECT count(*)명령시 빠르다
한 사람이 글을 쓰면 다른 많은 사람이 읽는 방식에 최적의 성능을 제공한다.
테이블과 인덱스를 각각 분리된 파일로 관리한다.
풀 텍스트 인덱스를 지원한다.
row level locking을 지원하지 못하기 때문에 CRUD 시 해당 테이블 전체에 lock이 걸린다.
InnoDB
그럼 본격적으로 InnoDB에 대해 알아보도록 하자.
먼저 MySQL 공식 홈페이지를 보면 다름과 같은 표가 있다.
InnoDB Recovery
point in time recovery
InnoDB database를 복구하려면 MySQL server를 binary logging이 가능하도록 실행시켜야 한다.
Recovery from Data Corruption or Disk Failure
가장 먼저, corrupted되지 않은 백업을 찾는다.
이후, binary log를 이용하여 backup이후의 변경된 값들을 다시 적용한다.
어떤 경우에는 몇개의 corrupt된 테이블만 복구하면 되는데, 이런 경우에는 CHECK TABLE을 이용하여 해당 테이블이 corrupt되었는지 확인할 수 있다.
하지만 CHECK TABLE이 모든 종류의 corrupt를 확인하는 것은 아니다.
디스크에 있는 데이터는 괜찮지만, file cache에 있는 데이터가 corrupt된 경우가 있다. 이런 경우에는 컴퓨터를 재부팅하는 것이 도움이 된다.
InnoDB Crash Recovery
MySQL의 예상치 못한 종료로 인한 복구 방법이다.
- Tablespace discovery
redo log application이 필요한 tablespace를 찾는 과정이다. - Redo log application
Redo log application은 initialization때, connection을 수락하기 전에 하는 동작이다.
모든 수정이 flush 되거나 redo log file이 사라졌을때 스킵한다.
InnoDB는 redo log를 스캔하여 in-memory table을 수정한다. - Roll blak of incomplete transactions
incomplete transactions는 예상치 못한 종료 시나 fast shutdown 시에 동작하고 있던 transaction이다. - Change buffer merge
change buffer에 있는 수정사항들을 적용한다. - Purge
더 이상 active transactions에게 보이지 않는 delete-marked 표시된 record를 삭제한다.
Tablespace Discovery During Crash Recovery
tablespace discovery란, checkpoint이후에 작성된 redo log를 적용해야 하는 tablespace를 판별하는 일을 말한다.
Buffer pool
InnoDB는 자신만의 buffer pool을 가지고 있다.
이러한 buffer pool은 메인 메모리에서 접근한 table과 index data를 캐싱한다.
이 캐시는 많은 정보를 담고 있는데, processing의 속도를 높여준다.
dedicated database server에서는 보통 80% 이상의 물리 메모리를 buffer pool에 할당한다.
효율적인 사용을 위해 linked list로 관리되며, LRU 정책을 따른다.
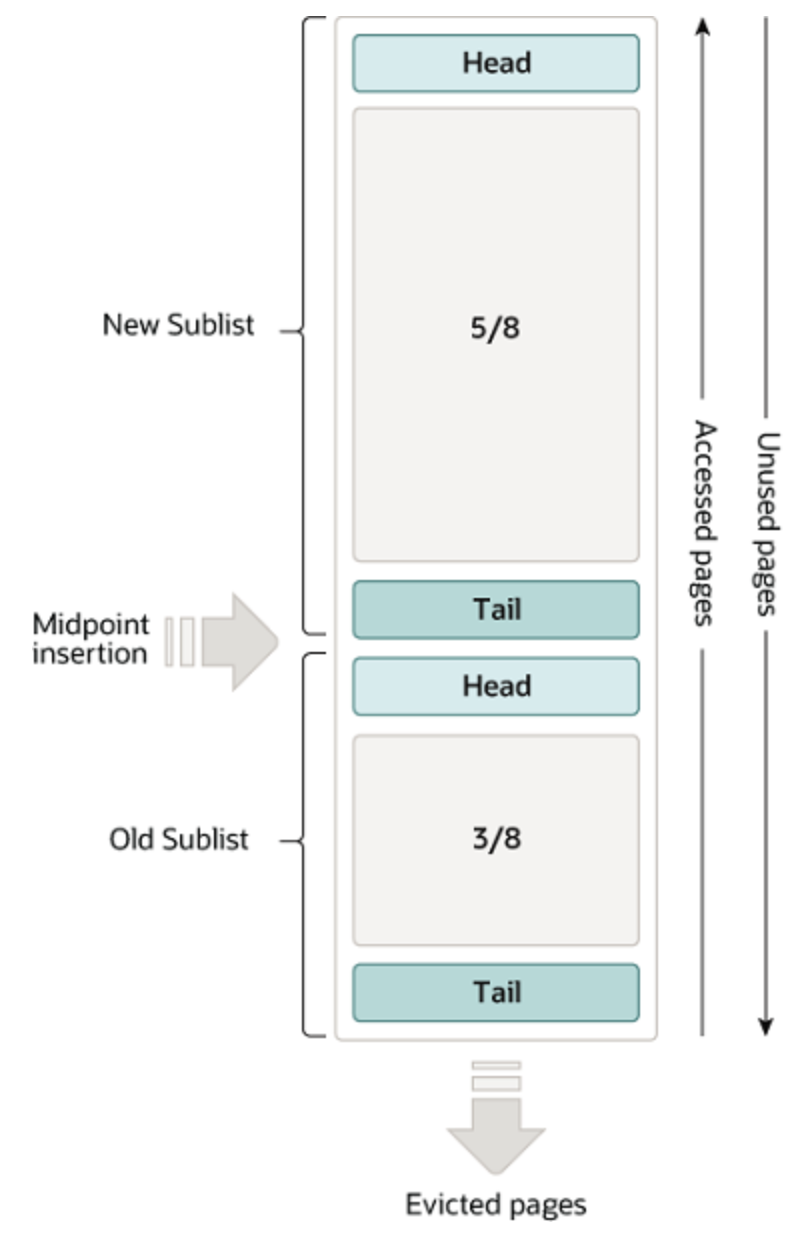
3/8은 old sublist이며, 3/5는 new sublist이다.
InnoDB가 페이지를 읽어 buffer pool에 들어간다면, midpoint에 저장된다.
old sublist에 있는 정보를 access하면, new sublist의 head에 저장된다.
설정
- buffer pool의 크기는 크게 설정해야 한다.
적당히 크게 설정해야 paging이 필요하지 않으며, disk에서 읽어오는 횟수를 최대한 줄일 수 있다. - 메모리가 충분하다면, biffer pool을 분리하여 운용할 수 있다.
- 자주 사용하지 않는 데이터를 대량으로 버퍼 풀로 가져오는 일이 있을 수 있다. 이는 buffer pool scan resistance로 buffer pool에서 필요한 데이터가 paging당하는 것을 막을 수 있다.
- background flush가 발생하는 시기를 조정할 수 있다.
- 워밍업 시간이 길어지지 않도록 현재 버퍼 풀 상태를 유지할 수 있다.
SHOW ENGINE INNODB STATUS의BUFFER POOL AND MEMORY섹션에서 확인할 수 있다.
외래키
Identifiers
외래키는 다음과 같은 규칙을 지켜야 한다.
- 정의된 symbol값만 가질수 있다.
- symbol이 정의되지 않았다면, 또는 symbol이 CONSTRAINT keyword에 포함되지 않는다면, constraint name은 자동적으로 생성된다.
- symbol이 정의되었다면, 유일한 데이터베이스여야 한다.
Conditions and Restrictions
- parent와 child 테이블은 같은 스토리지 엔진을 사용해야 한다. 임시 테이블은 사용할 수 없다.
- foreign key와 referenced key를 연결할 때는 비슷한 데이터 타입을 가져야 한다.
string의 길이는 일치하지 않아도 된다. - foreign key는 본인 테이블을 지정할 수 없다.
- MySQL은 foreign key와 referenced key에 index를 생성한다.
foreign key check 시 table scan을 하지 않아도 된다. - 외래키의 index는 prefixes는 불가능하다.
- 등등
Referential Actions
부모 테이블의 변화는 일치하는 자식 테이블에 영향을 준다.
`On UPDATE와 ÒN DELETE를 따로 설정할 수 있다.
- CASCADE
부모 테이블의 row의 삭제나 변경하면 자식 테이블의 일치하는 열이 삭제나 변경된다. - SET NULL
부모 테이블의 row를 삭제하거나 변경하면 일치하는 자식 테이블의 foreign key를 null로 변경한다. - RESTRICT
부모 테이블에서 삭제하거나 수정하는 것을 막는다. - NO ACTION
SQL에 있는 키워드. MySQL에서는 RESTRICT와 동일하게 동작한다. - SET DEFAULT
MySQL parser에 정의되어 있지만, InnoDB는 해당 정의를 reject한다.
데이터 검사
데이터가 disk나 메모리에서 corrupted되면, checksum mechanism이 확인하여 경고를 준다.
Clustered and Secondary Indexes
InnoDB는 row의 데이터를 저장하는 clustered index를 가지고 있다.
일반적으로 clustered index는 primary key와 동일하다.
primary key를 정의하면, InnoDB는 clustered index로 사용한다.
primary key를 정의하지 않는다면, InnoDB는 적합한 column을 찾아 clustered index로 사용한다.
만약 primary key에 적합한 unique하고 non-null인 collumn이 없다면 새로운 column을 생성한다.
clustered Index를 이용한 speed up
clustered index를 통한 접근은 매우 빠르다.
만약 페이지가 크다면, clustered index architecture가 disk I/O operation을 저장한다.
Secondary Indexes relate to the Clustered index
InnoDB에서는 secondary index는 primary key에 대한 정보를 가지고 있다. InnoDB는 이 primary key에 대한 정보를 이용하여 clustered index의 정보를 찾는다.
Change buffer
Adaptive hash index
Table and Page Compression
Data-at-Rest Encryption
Online DDL Operations
File-Per-Table Tablespaces
Row Formats
Integration with MySQL Performance Schema
참고자료
https://velog.io/@gillog/DBInnoDB-VS-MyISAM
https://dev.mysql.com/doc/refman/8.0/en/innodb-introduction.html
