12.1 서비스 배포: 언어에 특정한 패키징 포맷 패턴
언어에 특정한 패키징 포맷 패턴: 언어에 특정한 패키지 형태로 프로덕션에 배포
12.1.1 장점
- 배포가 빠르다
- 호스트에 서비스 복사해 그냥 시동하는 것이므로 빠르다.
- 리소스를 효율적으로 활용할 수 있다.
- 여러 서비스 인스턴스가 머신과 OS를 공유하므로 리소스를 효율적으로 활용할 수 있다.
12.1.2 단점
- 기술 스택을 캡슐화 할 수 없음
- 서비스별로 런타임 버전이 정해져 있으므로 정확히 구분해 설치해야 한다
- 서비스 인스턴스가 소비하는 리소스를 제한할 방법이 없음
- 한 프로세스가 전체 CPU/memory 다 소모하면?
- 여러 서비스 인스턴스가 동일 머신에서 실행될 경우 서로 격리할 수 없음
- 하나가 오작동하면 다른 하나 영향 받음
- 서비스 인스턴스를 어디에 둘지 자동으로 결정하기 어려움
- CPU/메모리 리소스는 한정되어 있고 각 서비스에서 효율적으로 활용하는 방향으로 배정해야 하는데, 이러한 점들을 자동으로 결정하기 어렵다. VM 기반의 클라우드 및 컨테이너 오케스트레이션 프레임워크는 이런 일을 자동으로 처리한다.
12.2 서비스 배포: 가상 머신 패턴
가상 머신 패턴: 서비스를 VM 이미지로 묶어 프로덕션에 배포한다. 각 서비스 인스턴스가 하나의 VM 이다.
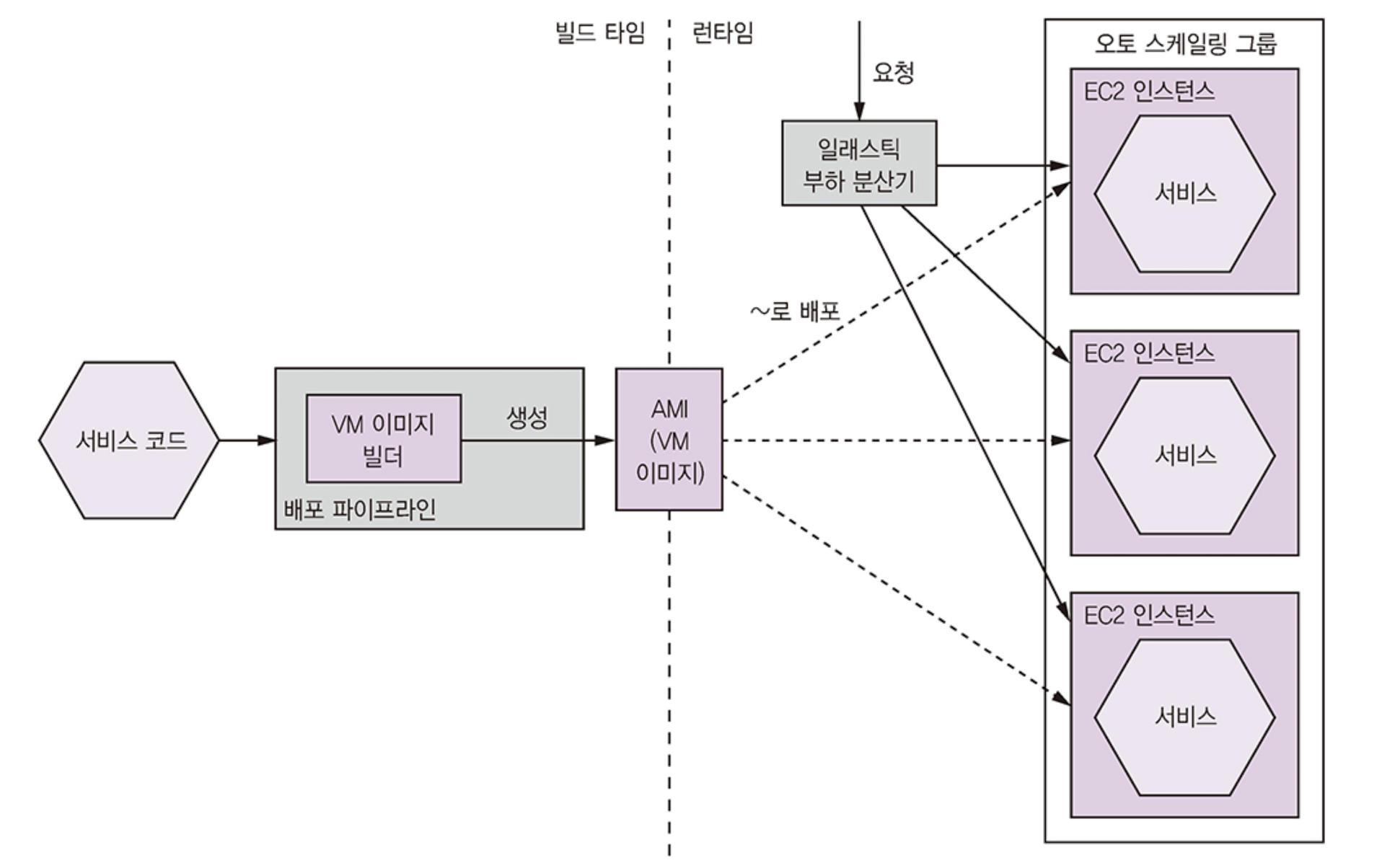
실행 가능한 jar/war 파일 복사해서 사용, 12.1 방식과 다를 건 없지만 클라우드를 활용한다는 점이 다름
12.2.1 장점
- VM 이미지로 기술 스택을 캡슐화
- 서비스와 연관된 디펜던시를 모두 VM 이미지에 담을 수 있다.
- 서비스 인스턴스 격리
- 성숙한 클라우드 인프라 활용
- VM을 스케줄링하며 VM 간 부하 분산 등 자동 확장 등 부가 기능 활용가능
12.2.2 단점
- 리소스를 효율적으로 활용할 수 없음
- IaaS 가상 머신은 대부분 VM 크기가 한정되어 있어 VM을 활용하기 어렵다. 가벼운 서비스(node.js, go)라면 비효율적인 배포 방식임
- 배포가 비교적 느림
- VM 이미지는 대부분 커서 빌드 시간이 걸리고, 네트워크를 통해 이동하는 데이터양도 많다.
- 시스템 관리 오버헤드 발생
- OS/런타임 패치를 해야한다.
12.3 서비스 배포: 컨테이너 패턴
컨테이너 패턴: 서비스를 컨테이너 이미지로 묶어 프로덕션에 배포한다. 각 서비스 인스턴스가 곧 하나의 컨테이너다.
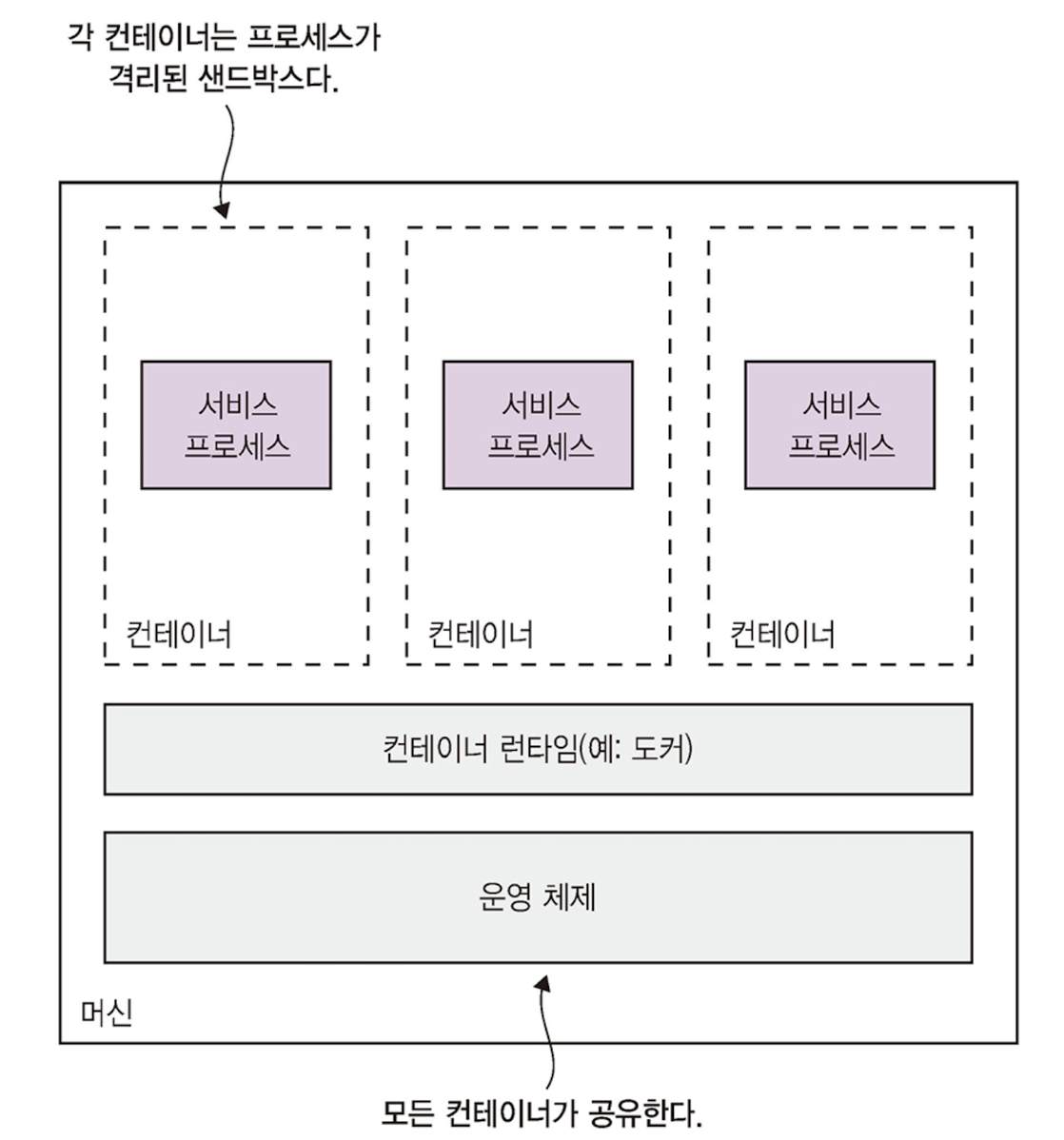
프로세스 입장에서 컨테이너는 마치 자체 머신에서 실행되는 것처럼 실행된다.
12.3.1 도커로 배포
- 도커 이미지 빌드
- 도커 이미지를 레지스트리에 푸시
빌드한 이미지를 태그 한 후, 레지스트리에 푸시 - 도커 컨테이너 실행
run 커맨드로 레지스트리 이미지를 당겨 온 후, 컨테이너가 생성/실행된다. 그리고 도커 파일에 지정된 java -jar 커맨드가 실행된다.
책 예시는 run이지만 단일 서비스가 드물고 머신 충돌까지 처리할 수 없어 docker compose 사용하자
docker compose 역시 단일 머신에 국한되므로 도커 오케스트레이션 프레임워크가 필요하다.
12.3.2 장점
- 기술 스택의 캡슐화
- 서비스 인스턴스 격리
- 서비스 인스턴스의 리소스 제한
12.3.3 단점
- 컨테이너 이미지 직접 관리
- OS/runtime 패치도 정기적 필요
12.4 쿠버네티스
- 도커 기반으로 여러 머신을 하나의 서비스 실행 리소스 풀로 전환하는 소프트웨어 계층
- 인스턴스나 머신이 깨지더라도 항상 서비스 인스턴스별 개수가 원하는 만큼 실행되도록 유지
12.4.1 쿠버네티스 개요
쿠버네티스: 도커가 실행되는 여러 머신을 하나의 리소스 풀로 취급하는 도커 오케스트레이션 프레임 워크, N개의 서비스 인스턴스를 실행하라고 지시하면 나머지는 쿠베가 알아서 처리
쿠베의 주요 기능은 다음과 같다.
- 리소스 관리: 여러 머신을 CPU, 메모리, 스토리지 볼륨을 묶어 놓은 하나의 리소스 풀로 취급
- 스케줄링: 컨테이너를 실행할 머신 선택, 유사성 찾아서 여러 컨테이너를 같은 노드에 배치하거나 반대 실행
- 서비스 관리: 마이크로서비스에 직접 매핑되는 서비스를 명명하고 버저닝, 롤링 업데이트가 가능해 롤백도 가능
쿠버네티스 아키텍처
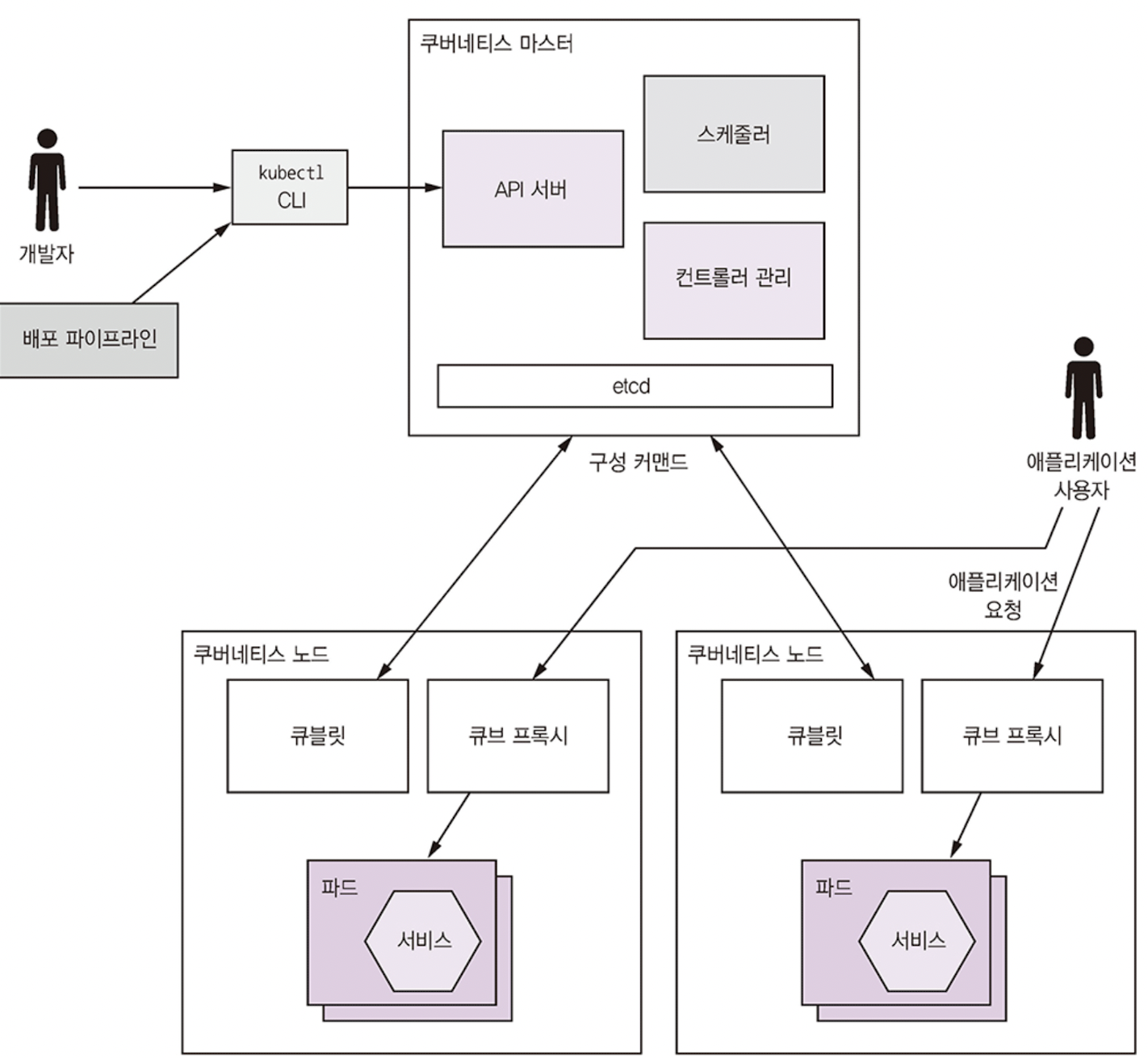
마스터는 다음 컴포넌트를 실행한다.
- API 서버: kubectl CLI에서 사용하는 서비스 배포/관리용 REST API
- etcd: 클러스터 데이터를 저장하는 key-value
- 스케줄러: 파드를 실행할 노드 선택
- 컨트롤러 관리자: 컨트롤러 실행, 컨트롤러는 클러스터가 원하는 상태가 되도록 제어(인스턴스 개수 등)
노드는 다음 컴포넌트를 실행한다.
- kubelet: 노드에서 실행되는 파드를 생성/관리
- kube-proxy: 여러 파드에 부하를 분산하는 등 네트워킹 관리
- Pod: 애플리케이션 서비스
쿠버네티스 핵심 개념
- pod: 기본 배포 단위. IP 주소, 스토리지 볼륨을 공유하는 하나 이상의 컨테이너로 구성
- deployment: 항상 파드 인스턴스를 원하는 개수만큼 실행시키는 컨트롤러
- service: 클라이언트에 정적 네트워크 위치 제공. 서비스 디스커버리 형태를 따름
- config map: 외부화 구성이 정의된 key-value
12.4.2 쿠버네티스 배포: 예시
deployment 정의
kubectl apply -f 위에서설정한deploy.yml위와 같은 apply 커맨드를 쿠베 api 서버에 요청해 deployment, pod를 생성하도록 한다.
쿠버네티스 서비스 생성
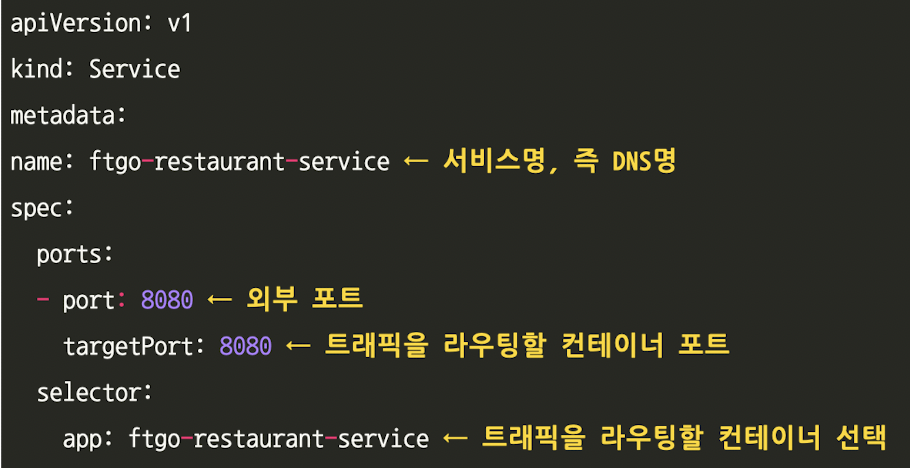
pod ip 주소는 동적 할당되지만 쿠베 내의 서비스 디스커버리 메커니즘으로 안정된 엔드포인트를 제공할 수 있다.
12.4.3 API 게이트웨이 배포
위에서 작성한 쿠베 서비스는 클러스터 내부에서만 접근 가능하다. API 게이트웨이는 클러스터 외부에서도 접근 가능해야 한다.
NodePort 서비스는 광역 클러스터 포트를 통해 클러스터의 모든 노드에 접근할 수 있다. 어떤 클러스터 노드라도 광역 클러스터 포트를 경유한 트래픽은 모두 백엔드 pod로 부하 분산 처리된다.
...
type: NodePort
ports:
- nodePort: 30000
port: 80
targetPort: 8080
selector:
app: ftgo-api-gateway클러스터 내부: http://ftgo-api-gateway, 외부: http://<node-ip-address>:30000
NodePort 서비스를 구성한 후, 인터넷에서 들어온 요청을 노드에 부하 분산하도록 AWS ELB를 구성하면 된다.
12.4.4 무중단 배포
쿠베는 신 버전이 요청 처리 준비가 완료되기 전에 구 버전을 중지하지 않는다.
롤아웃이라는 이력을 관리하기에 다음 커맨드로 이전 버전으로 롤백할 수 있다.
kubectl rollout undo deployment <서비스명>12.4.5 배포와 릴리스 분리: 서비스 메시
- 배포: 서비스를 프로덕션에서 작동시키는 것
- 릴리스: 운영 트래픽을 처리할 수 있게 만드는 것
파드 준비가 끝나고 운영 트래픽이 들어올 때 버그가 발견되어 쿠베가 새 버전을 계속 롤아웃을 할 수 있다. 따라서 새 버전의 서비스를 확실하게 시작하려면 배포와 릴리스는 분리할 필요가 있는데, 이 일을 서비스 메시가 해준다.
Istio 서비스 메시 개요
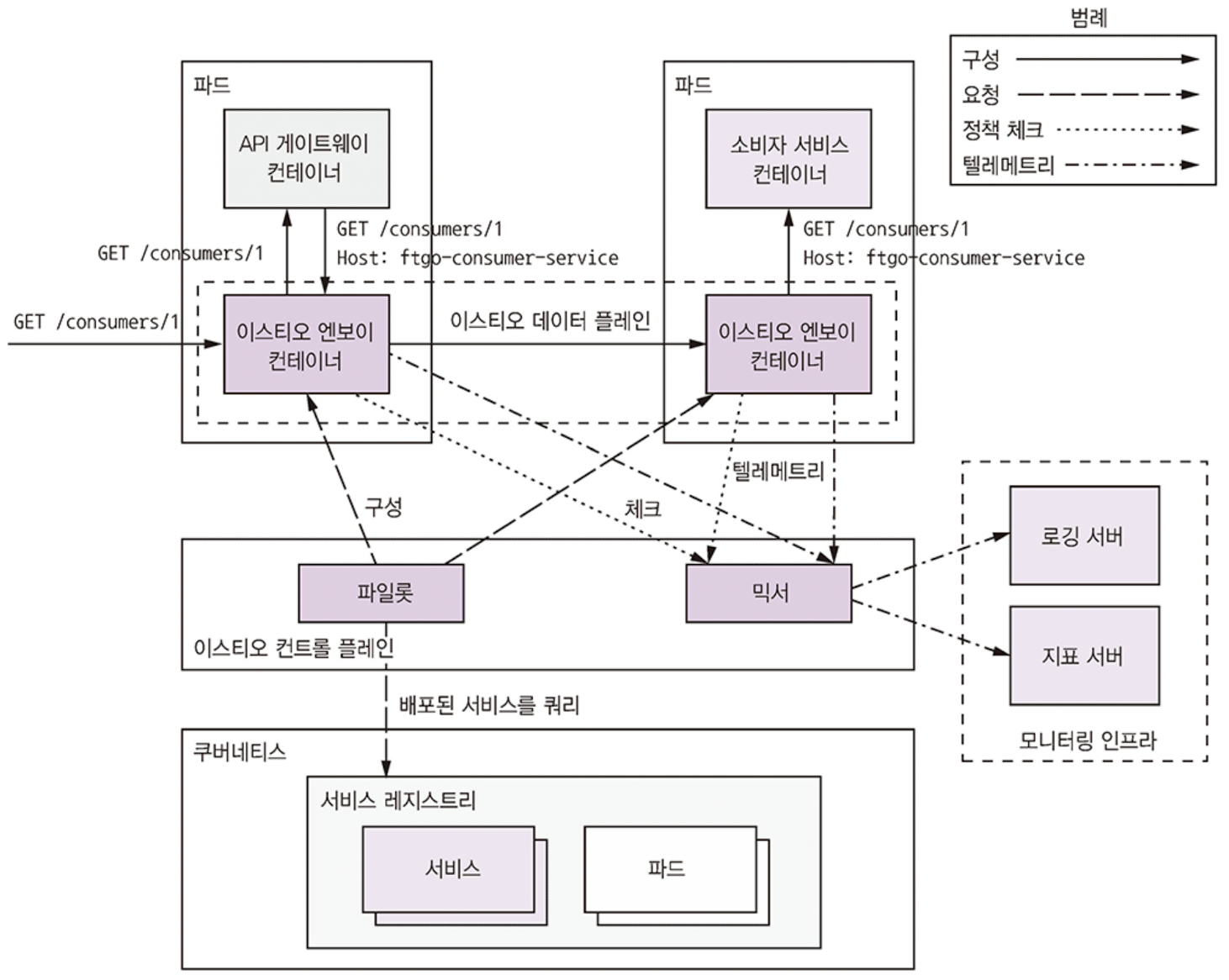
- 컨트롤 플레인: 데이터 플레인이 트래픽을 라우팅하도록 구성하는 등의 관리 역할
- 파일럿, 믹서로 구성됨
- 파일럿: 하부 인프라에서 배포된 서비스 관련 정보 추출, 서비스와 정상 파드 조회
- 믹서:엔보이 프록시에서 텔레메트리를 수집하고 정책 집행
- 데이터 플레인: 서비스 인스턴스별 엔보이 프록시로 구성
- 엔보이: 통신하는 서버
Istio로 서비스 배포

운영 트래픽을 95%, 5% 나눠서 규칙 설정가능하다.
12.5 서비스 배포: 서버리스 패턴
이전 방식들은 1) 컴퓨팅 리소스를 사전에 프로비저닝 필요, 2) 사람이 직접 시스템 관리 라는 단점이 존재하였다. 이제는 서버리스 솔루션이 있다.
12.5.1 AWS 람다를 이용한 서버리스 배포
서버리스 배포: 퍼블릭 클라우드에서 제공하는 서버리스 배포 메커니즘을 이용해 서비스 배포
서비스를 배포하려면 애플리케이션을 zip, zar로 묶고 AWS람다에 업로드한다. AWS 람다는 들어온 요청을 처리하기에 충분한 개수만큼 인스턴스를 자동 실행한다.
12.5.2 람다 함수 개발
public interface RequestHandler<I, O> {
public O handleRequest(I input, Context context);
}12.5.3 람다 함수 호출
1. HTTP 요청 처리
- AWS API 게이트웨이가 HTTP 요청을 람다 함수로 라우팅
- API 게이트웨이는 람다 함수를 HTTPS 끝점으로 표출하고 HTTP 요청이 들어오면 이를 람다 함수로 전달해 HTTP 응답 객체를 반환하는 HTTP 프록시 역할
2. AWS 서비스에서 생성된 이벤트 처리
- S3 버킷에 객체 생성, DB 테이블의 데이터 항목이 생성/수정/삭제, SES를 통해 이메일 수신 등 이벤트가 생성되면 람다 함수가 처리되도록 트리거
3. 람다 함수 스케줄링
- 크론 같은 스케줄러를 람다 함수가 주기적으로 호출되도록 설정
4. 웹 서비스를 요청해 람다 함수 호출
- 웹 서비스를 요청할 때 람다 함수명과 입력 이벤트 데이터를 지정하고, 람다함수를 호출한다.
12.5.4 람다 함수의 장점
- 다양한 AWS 서비스와의 연계
- 시스템 관리 업무가 많이 경감됨
- 저수준의 시스템 관리는 신경 쓸 필요 없다. (OS, 런타임 패치 등)
- 탄력성
- 부하 처리에 필요한 개수만큼 인스턴스 실행
- 사용량만큼 과금
- 실제로 요청을 처리하기 위해 소비한 리소스만큼 비용 지불
12.5.5 람다 함수의 단점
- long-tail latency
- 람다는 코드를 동적으로 실행하므로 AWS가 인스턴스를 프로비저닝하고 애플리케이션을 시동하기까지 오랜 시간이 걸린다. 따라서 요청에 따라 많이 지연되는 경우도 있다.
- 제한된 이벤트/요청 기반 프로그래밍 모델
- 서드파티 메시지 브로커에서 유입된 메시지를 소비하는 서비스와 같이 실행 시간이 긴 서비스를 배포할 용도는 아니다.
12.6 REST 서비스 배포: AWS 람다 및 AWS 게이트웨이
REST 끝점마다 하나씩 배정된 람다 함수들로 구성, AWS API 게이트웨이는 HTTP 요청을 람다 함수들로 라우팅한다.
12.6.1 음식점 서비스를 AWS 람다 버전으로 설계
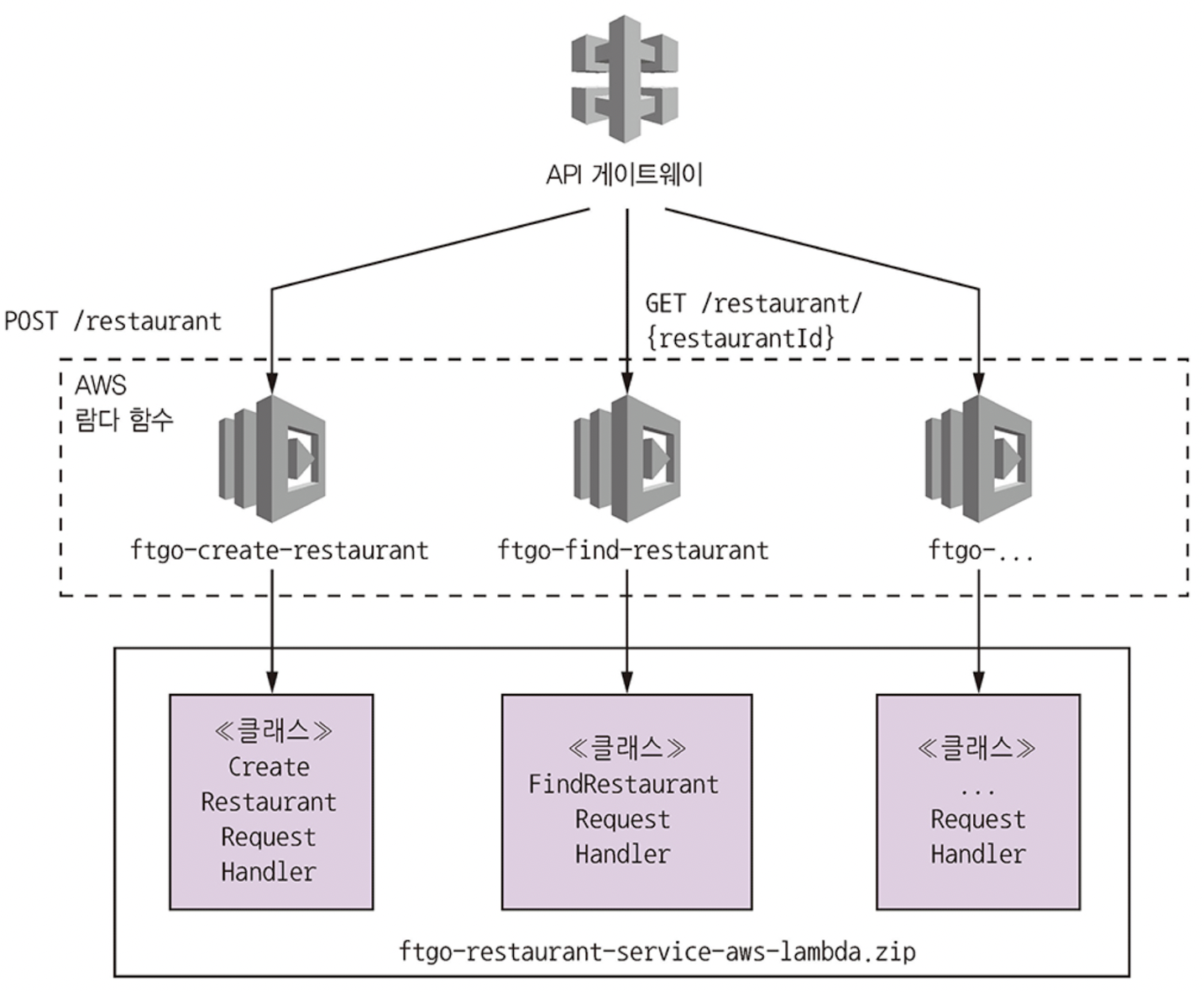
스프링 MVC 컨트롤러 대신 AWS 람다 요청 핸들러 클래스가 있다.
구현체
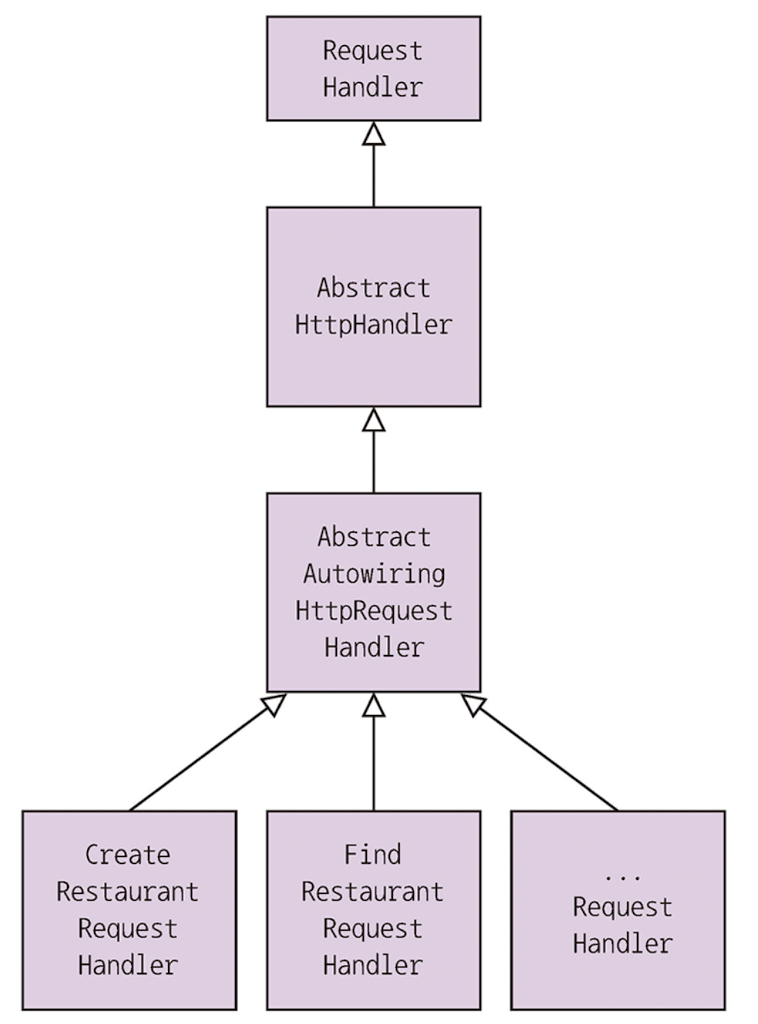
- AbstractHttpHandler: 예외 잡음
- AbstractAutowiringHttpRequestHandler: 요청 처리에 필요한 디펜던시 주입
이 책의 구현체인 FindRestaurantRequestHandler의 handlerHttpRequest()는 APIGatewayProxyRequestEvent를 매개변수로 받아 service 계층을 호출해 APIGatewayProxyResponseEvent를 반환한다.
디펜던시 주입
AbstractHttpHandler의 beforeHandling() 을 재정의해 요청 핸들러에 디펜던시를 자동와이어링으로 주입한다.
12.6.2 zip 파일로 서비스 패키징
그래이들 패키징으로 zip 파일로 패키징
task buildzip(type: Zip) {
//어쩌구저쩌구
}12.6.3 서버리스 프레임워크로 람다 함수 배포
오픈 소스 서버리스 프로젝트가 있으며, 람다 함수와 REST 끝점이 기술된 serverless.yml파일만 작성하면 서버리스가 대신 람다 함수를 배포하고 이 함수들로 요청을 라우칭하는 API 게이트웨이를 생성/구성 한다.
