우리가 데이터분석을 할 때 복잡한 데이터프레임을 특정한 값을 기준으로 묶어서 봐야하는 순간이 온다. 예를 들어 기상 데이터를 분석한다고 치면, 날짜별 또는 도시별로 값을 묶어서 통계를 내야할 필요가 있다. 이 때 사용할 수 있는 방법이 Groupby를 사용하는 것이다.
Groupby는 데이터프레임의 같은 값을 하나로 묶어서 통계 결과를 확인하기 위해 사용한다.
그룹화 하는 과정은 다음과 같다.
- Split : 그룹별로 데이터를 나눈다.
- Apply : 각 그룹별로 집계 함수를 적용한다.
- Combine : 그룹별 집계 결과를 하나로 합친다.
사용법은 간단하다. 데이터프레임을 묶고 싶은 컬럼을 기준으로 groupby를 사용하면 된다.
df.groupby('column_name')
앞서 말했듯이 groupby는 통계 결과를 확인하기 위해 사용한다. groupby만 사용하면 데이터를 그룹화하여 모으는 것이 아닌, 데이터프레임으로 그룹을 생성하는 과정까지 진행한다. 따라서 뒤에 통계함수를 사용해줘야 우리가 원하는 값으로 정리하여 결과를 확인할 수 있다.
groupby 내부 메소드는 다음과 같다.
내부 메소드 : count, size, sum, mean, std, var, min, max
# 데이터 수 확인
airline_group.count()
# 평균값 확인
airline_group.mean()
# 특정 col만 확인
airline_group.mean()[['price']]
# groupby를 활용하여 다중 인덱싱 설정
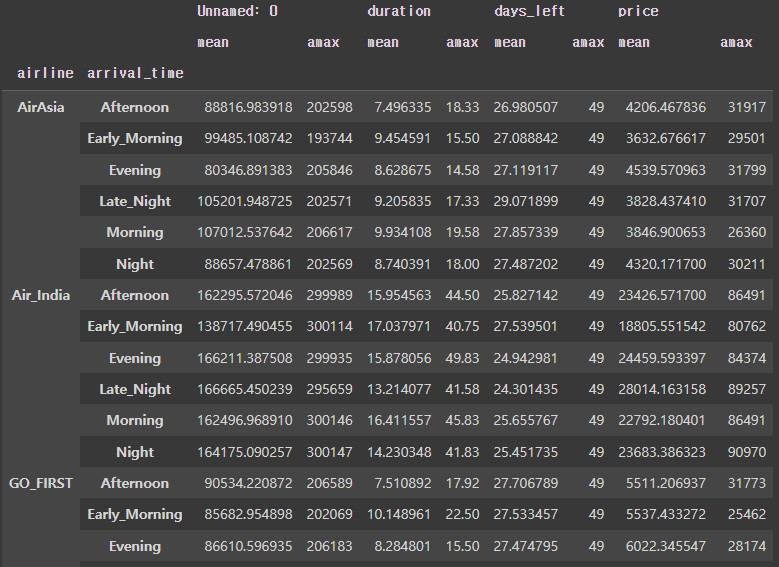
flight.groupby(['airline', 'arrival_time']).mean()mean 함수의 결과는 다음과 같다.
이처럼 groupby에 통계 함수를 같이 쓰면 우리가 원하는 데이터프레임의 형태로 결과가 출력된다. 또한 하나의 컬럼이 아닌 여러 개의 컬럼으로 다중 인덱싱을 설정할 수도 있다.
이렇게 다중 인덱싱한 결과를 새로운 데이터프레임으로 저장할 수도 있다.
# 여러 개의 컬럼을 groupby하여 새로운 데이터프레임으로 생성
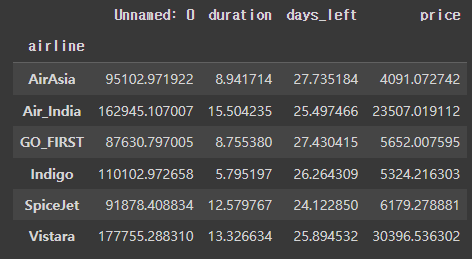
mul_airline_group = flight.groupby(['airline', 'arrival_time'])
mul_airline_group.mean()
# groupby 후 원하는 데이터만 불러오기
flight.groupby(['airline', 'arrival_time']).mean().loc[[('AirAsia', 'Evening')]]- Index로 Groupby 하기
index를 사용하여 그룹화할 때 level을 설정할 수 있음
- set_index : 칼럼을 인덱스로 변경하는 경우에 사용, 기존의 인덱스를 제거하고 칼럼 중 하나를 인덱스로 설정
- reset_index : 인덱스를 초기화
이때 level의 의미는 index의 깊이라고 생각하면 된다.
flight.set_index(['airline', 'arrival_time'])을 기준으로 보면, level은 index로 설정한 column이다. 즉, level=0 -> airline, level=1 -> arrival_time이 된다.
level[0,1] -> [airline, arrival_time], level[1,0]-> [arrival_time, airline]이 되는 것이다.
# set_index로 인덱스 설정하기
flight.set_index(['airline', 'arrival_time'])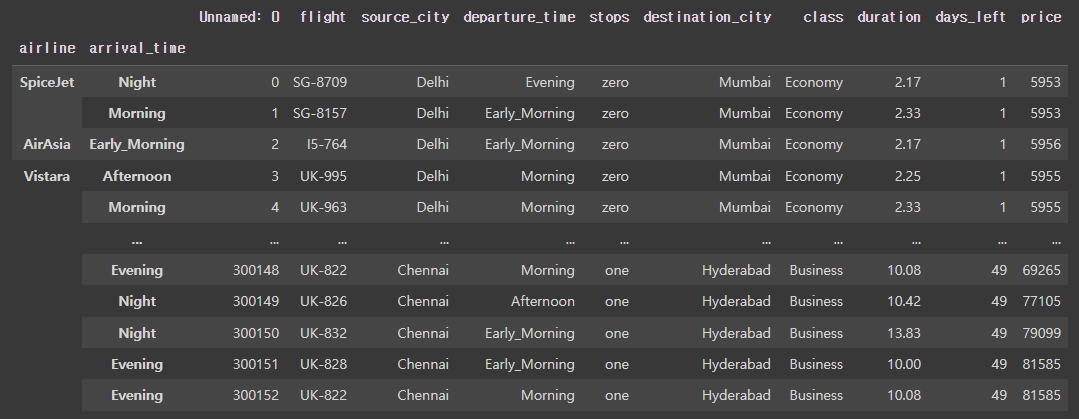
이 결과는 'airline'과 'arrival_time'을 기준으로 인덱스를 설정했을 뿐, 그룹화된 결과가 아니다.
# 다중 인덱스를 세팅 후 해당 인덱스 기준으로 groupby
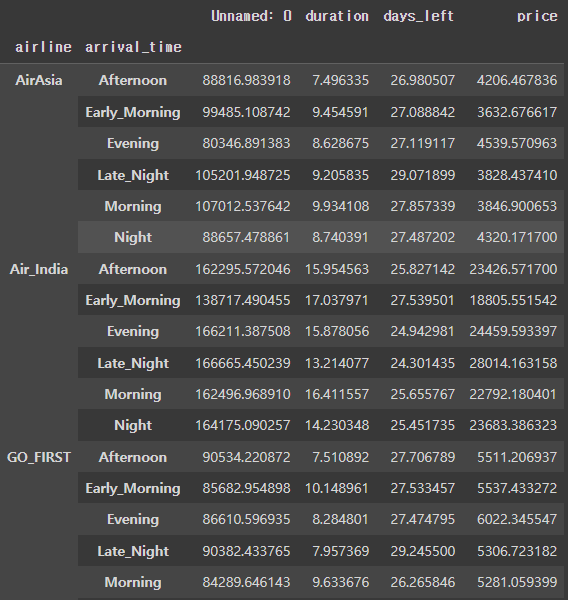
flight.set_index(['airline', 'arrival_time']).groupby(level=[0]).mean()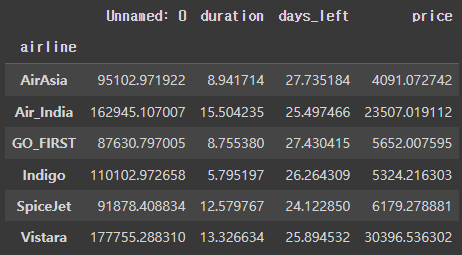
level이 0이므로 'airline'을 기준으로 그룹화된 것을 확인할 수 있다.
다음은 level[0,1]을 사용하여 groupby 해보겠다.
# 인덱스로 모두 선택하여 groupby
flight.set_index(['airline', 'arrival_time']).groupby(level=[0,1]).mean()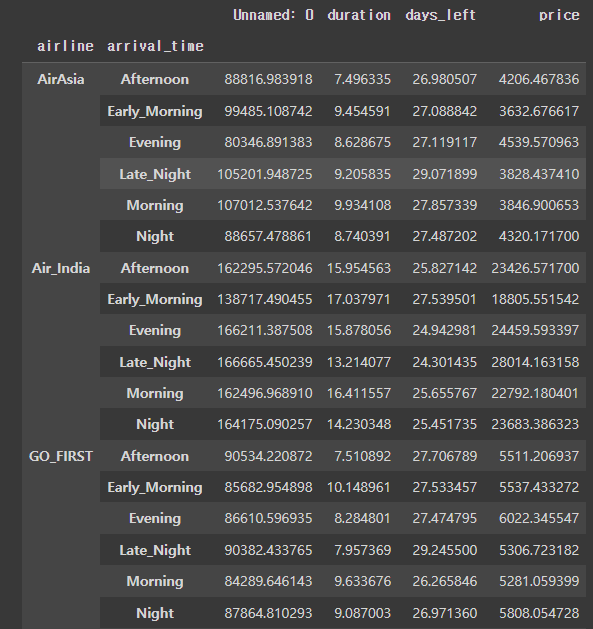
- Aggregate 함수를 사용하여 통계 집계하기
Aggregate를 사용하면 여러 개의 통계 함수를 사용하여 통계 결과를 한 눈에 볼 수 있다.
# aggregate method를 이용하여 groupby 후 mean과 max를 확인해보자.
flight.set_index(['airline', 'arrival_time']).groupby(level=[0,1]).aggregate([np.mean, np.max])