Data Mining 실습문제 - Classification Analysis
지문
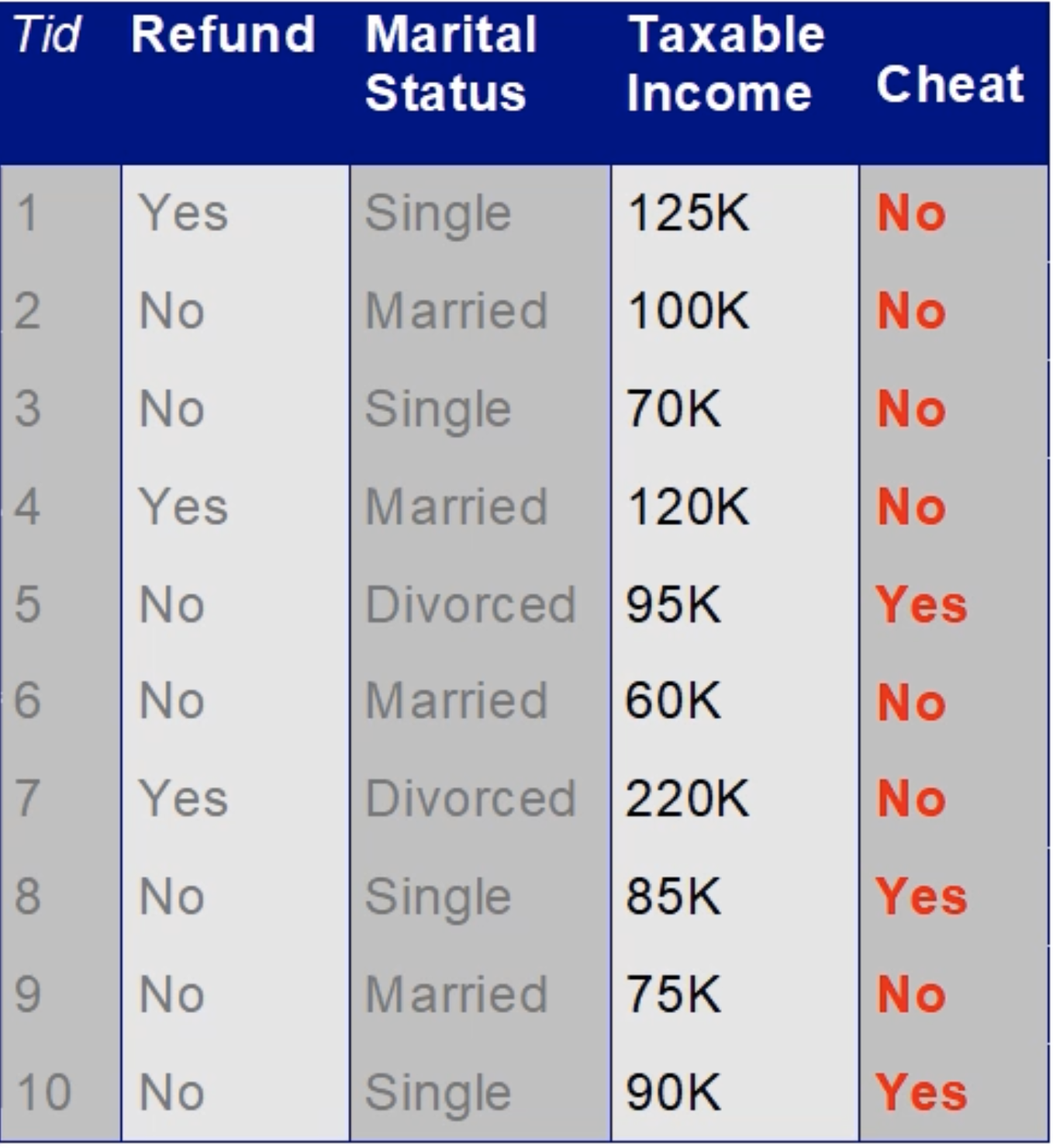
한 은행의 대출 부서에서는 고객의 대출 상환 여부를 예측하기 위해 Classification Analysis를 활용하기로 하고, 다음과 같은 데이터를 수집하였다.
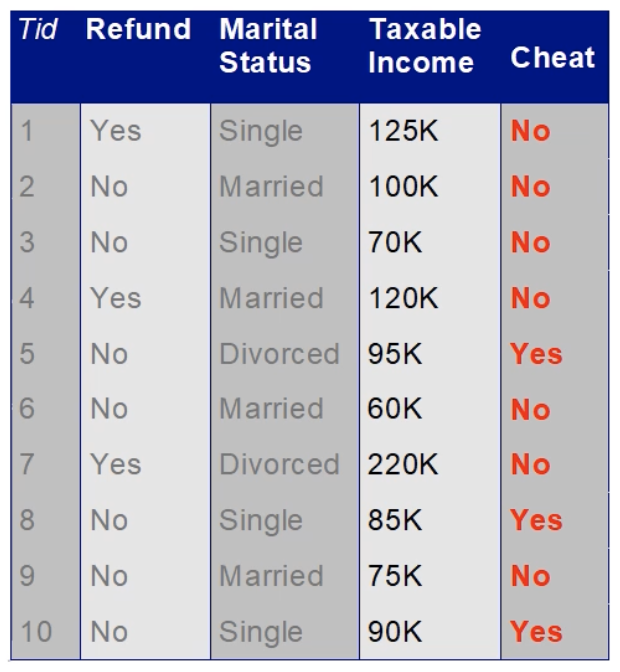
이때 Refund는 세금 환급의 여부를 의미하는 것으로 Yes, No의 Binary Attribute에 해당한다.
Marital Status는 결혼의 여부를 의미하는 것으로 Single, Married, Divorced(이혼) 의 3가지 종류가 존재한다.
Taxable Income은 과세 소득을 의미하는 것으로 Continuous Attribute에 해당한다.
이 데이터를 토대로 Hunt's Algorithm을 사용하여 Decision Tree를 구축하고자 할 때, 물음에 답하시오.
단, Decision Tree에서의 Split 순서는 임의의 알고리즘을 통해 정하였다고 가정하며, 이 문제에서는 고려하지 않는다.
모든 계산 결과는 소수점 아래 3번째 자리까지 반올림하여 나타낸다.
문제 1
Split 1
첫 번째 split condition으로, Refund의 여부를 활용하기로 하였다. 이때 Refund는 Binary Attribute이므로, Yes와 No로 나누어짐이 자명하다.
Refund의 여부를 통해 Yes와 No로 나누었다고 할 때, 물음에 답하시오.
- Yes, No에 포함된 데이터의 개수를 각각 말하시오
Yes : 3개, No : 7개
- Split 1을 통해 생성된 2개의 child node를 각각 다시 나누어야 할 필요가 있는가? 그렇지 않다면 이유를 말하시오.
refund가 yes인 노드의 경우 모든 label이 No이므로, 더 이상 나눌 필요가 없다.
- Split 1에 대한 GINI 값을 parent node, 각각의 child node 에 대해 모두 구하시오.
parent : 0.42, c1(refund = yes) : 0, c2(refund = no) : 0.49
- GINI 값에 기반한 GAIN 값을, 3번의 결과를 통해 구하시오.
GAIN = 0.42 - (0.3 0 + 0.7 0.490) = 0.077
- Split 1 에 대한 Entropy 값을 parent node, 각각의 child node에 대해 모두 구하시오.
parent : - 3/10 lg(3/10) - 7/10 lg(7/10) = 0.881
child1(refund = yes) : 0, child2(refund = no) : -3/7 lg(3/7) -4/7 lg(4/7) = 0.985 - Entropy 값에 기반한 GAIN 값을, 5번의 결과를 통해 구하시오.
GAIN = 0.881 - 0.30 - 0.70.985 = 0.1915
- Split 1에 대한 Classification Error 값을 parent node, 각각의 child node에 대해 모두 구하시오.
parent : 1-max(3/10, 4/10) = 0.6
child1(refund = yes) : 1-max(0/3, 3/3) = 0, child(refund = no) : 1-max(3/7, 4/7) = 0.429 - Classification Error 값에 기반한 GAIN 값을, 7번의 결과를 통해 구하시오.
GAIN = 0.6 - 3/10 0 - 7/10 0.429 = 0.300
Split 2
두 번째 Split Condition으로 Marital Status를 사용하기로 하였다. 이때 Marital Status에는 3가지 값이 있으므로, 이를 3개의 Multi-way Split으로 나눌 지 아니면 2가지의 Split으로 나눌 지 결정해야 한다. 우리는 아래의 3가지 방법 중 하나를 선택하기로 하였다.
- c1 = {Single}, c2 = {Divorced}, c3 = {Married}
- c1 = {Single, Divorced} / c2 = {Married}
이때 다음 물음에 답하시오.
- 여기서는 Entropy에 기반한 GainRAIO 값을 통해 더 나은 Split condition을 찾고자 한다. 먼저 1번 split 방법에 대해 Information Gain을 계산하시오
entropy(parent) : 0.985 / entropy(c1) : 0.918 / entropy(c2) : 0 / entropy(c3) : 0
Information Gain : 0.985 - 3/70.918 - 1/70 + 3/7*0 = 0.591 - 2번 split 방법에 대해 Information Gain을 계산하시오.
entropy(c1) : 0.811, entropy(c2) : 0
Information Gain : 0.985 - 4/70.811 - 3/70 = 0.522 - 1번과 2번의 결과값을 비교하고, 이 값을 통해 더 나은 split condition을 결정할 수 있는지 논하시오.
1번의 Gain이 2번의 Gain보다 크지만, 이는 split의 개수를 고려하지 않은 결과이므로 이 값으로는 결정할 수 없다.
- 1번 split 방법에 대한 GainRATIO를 계산하시오.
SplitINFO : -3/7lg(3/7) 2 - 1/7*lg(1/7) = 1.449
GainRATIO : Information Gain / SplitINFO = 0.591 / 1.449 = 0.408 - 2번 split 방법에 대한 GainRATIO를 계산하시오.
SplitINFO : 0.985이므로 GainRATIO : 0.522 / 0.985 = 0.530
- 4번과 5번의 결과값을 비교하고, 이 값을 통해 더 나은 split condition을 결정할 수 있는지 논하시오.
2번 방법의 SplitINFO가 더 크므로, 2번 방법을 선택한다. 이 방법은 split의 수를 고려하는 방법에 해당하므로, split의 수가 서로 다른 경우에 split condition을 결정해야 하는 이번 문제에 있어 올바른 measure에 해당한다. 따라서 신뢰가능하다.
- 최종적으로 어떤 split이 더 나은 것인지 말하시오.
2번
Split 3
Split 2를 통해 {Married}는 모두 같은 label을 가지게 되었으므로, c1인 {Single, Divorced}에 대해서만 추가 split을 진행하면 되는 상황이다.
현재 사용할 수 있는 attribute는 Taxable income이 유일하고, 이는 continuous attribute에 해당한다. 이때 우리는 이 attribute를 일정한 기준을 잡아, 해당 기준보다 큰지 작은지의 여부로 2가지로 구분하기로 하였다. 이번 챕터에서는 해당 값을 결정하는 것이 최종 과제가 된다.
우리는 split 기준값의 후보들로, 각 sample의 Taxable Income을 오름차순으로 나열하였을 때의 사잇값들을 사용하기로 하였다. 이때 물음에 답하시오.
(해당 값을 고르는 알고리즘은 교재의 과정을 기반으로 진행합니다)
- Split의 대상이 되는 값들의 Taxable Income을 작은 값부터 나열하시오.
70, 85, 90, 95
- 후보가 될 수 있는 값들을 모두 나열하시오
65, 77, 87, 92, 100 (교재 참고, 약간씩 달라질 수 있으므로 대략적인 의미가 맞으면 맞는 것으로 하자)
- 2번의 후보들 중 split 값을 정하기 위해서는, 각각의 split 기준으로 나눈 결과에 대한 이 값을 계산하여 비교하여야 한다. 이것은 무엇일까?
Child 에 대한 Impurity Measure. 어차피 Parent의 Impurity Measure은 모두 동일하므로, Child끼리만 비교하여 가장 작은 값을 선택하면 된다.
- 이 예제에서는 굳이 모든 split 기준에 대해 Impurity Measure를 구하지 않아도, 기준이 되는 값이 자명하게 정해진다. 해당 값을 말하시오.
- 이떄 child의 Impurity Measure이 0이 된다.
문제 2
만일 위의 데이터를 토대로 Decision Tree를 구축하고자 할 때, 첫 번째 Split Condition으로 Taxable Income을 사용하게 되었다고 가정하자.
이번 경우에는 1번 문제와는 다르게, 대상이 되는 split 기준 값이 많게 된다. 이 경우에 물음에 답하시오.
- 모든 record의 Taxable Income을 오름차순으로 나열하시오.
60, 70, 75, 85, 90, 95, 100, 120, 125, 220
- Split의 후보 값들을 차례로 나열하시오.
55, 65, 72, 80, 87, 92, 97, 110, 122, 172, 225
- Split의 기준값이 87이 되는 경우에 대해, GINI(child)를 계산하시오.
87 이하 (c1): Yes 1명, No 3명 / 87 초과 (c2): Yes 2명 No 4명
따라서 GINI(c1) = 0.375, GINI(c2) = 0.444이므로, GINI(child) = 4/10 0.375 + 6/10 0.444 = 0.416이 된다. - 3번에서 87에 대한 GINI 값을 계산하기는 했으나, 실제로는 해당 후보들 중 2개의 값에 대한 GINI 값을 구하여 비교하면 된다. 어떤 원리인지 설명하고, 해당 값이 무엇인지 말하시오.
Split 기준을 계속해서 큰 값으로 늘려나갈 때, 이동하는 record의 label이 바뀌는 지점에서만 GINI 값을 구하여 비교하면 된다. 이는 label이 바뀌는 지점을 기준으로 그 사이의 값들에 대해서는 GINI 값의 그래프가 Concave한 모양을 그리기 때문이다. 따라서 label이 바뀌지 않는 지점에서는 GINI의 최소값이 나오는 것이 불가능하게 된다. 각 record별 label을 나열해 보았을 때, 75 - 85, 95 - 100 구간에서만 이동하는 record의 label이 바뀌게 된다. 따라서 확인해야 하는 split 값은 80, 97이 된다.
- 4번의 정답에 해당하는 값에 대한 GINI(child) 값을 계산하고, 결국 어느 값을 기준으로 Split을 진행해야 하는지 결정하시오.
80 -> GINI(child) : 0.343 / 97 -> GINI(child) : 0.300 이므로, GINI 값이 더 작은 97 쪽을 기준으로 split을 진행한다.
문제 3
다음은 Decision Tree를 구축하는 알고리즘에 대한 pseudo code이다. 물음에 답하시오.
def TreeGrowth(E, F): # E : ???, F : ???
if function1(E, F) = true:
leaf = function2()
leaf.(blank 1) = function3(E)
return leaf
else:
(blank 2) = function4()
(blank 2).test_cond = function5()
let V = {v|v is a (blank3)}
for each v in V:
E(v) = {blank 4}
(blank5) = function6(E(v), F)
(~~~~~~~ blank 6 ~~~~~~~~ )
return root- E, F는 어떠한 집합을 말하며, 위의 지문을 기준으로 할 때 어떤 값을 가지는지 말하시오
E : training record, F : attribute set. 즉 (Refund, Marital State, Taxable Income)이 된다.
- function1이 무엇이고, 어떤 역할을 하는지 말하시오.
stopping_cond. 현재 노드에서 멈추어야 하는지의 여부를 결정한다.
- function2가 무엇이고, 어떤 역할을 하는지 말하시오.
createNode. 노드를 생성하는 역할을 한다.
- function3가 무엇이고, 어떤 역할을 하는지 말하시오
Classify. E의 값들을 기준으로 해당 leaf가 어떠한 label을 가지게 되는지 결정한다.
- blank1에 들어갈 말은 무엇인가?
label
- function4가 무엇이고, 어떤 역할을 하는지 말하시오.
createNode. 역할은 위와 동일
- blank2에 들어갈 말은 무엇인가?
root
- function5가 무엇이고, 어떤 역할을 하는지 말하시오.
find_best_split, 어떤 attribute로, 어떤 값을 기준으로, 몇 개로 나눌 것인지를 모두 결정한다.
- blank3에 들어갈 말은 무엇인가?
root.test_cond에 대해 모든 가능한 값들의 집합을 의미한다.
- blank4에 들어갈 말은 무엇인가?
root.test_cond의 값에 해당하는 record들의 집합을 의미한다.
- function3가 무엇이고, 어떤 역할을 하는지 말하시오.
TreeGrowth. 즉 함수의 재귀호출 구조가 된다.
- blank5에 들어갈 말은 무엇인가?
child
- blank6에 들어갈 말은 무엇인가?
child를 root의 자손으로 추가하고, 엣지를 label한다.
