지난번이 마지막이길 바랬지만 이번이 정말 마지막이길 바래본다.
전체적인 코드 정리
- 학습은 VSCODE에서 진행했다.
import matplotlib.pylab as plt
import numpy as np
import os
import cv2
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Flatten, Dense
from tensorflow.keras import applications
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.layers import LSTM
from sklearn.utils import shuffle
from imageio import imread-> 필요한 라이브러리 임포트
train_dir='video/3frame/traindata'
valid_dir='video/3frame/validationdata'
batch_size = 128-> 학습 데이터 경로와 batch size 지정
def bring_data_from_directory():
datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = datagen.flow_from_directory(
train_dir,
target_size=(224, 224),
batch_size=batch_size,
class_mode='categorical',
shuffle=True,
classes=['fine', 'hello', 'wait'])
validation_generator = datagen.flow_from_directory(
valid_dir,
target_size=(224, 224),
batch_size=batch_size,
class_mode='categorical',
shuffle=True,
classes=['fine', 'hello', 'wait'])
return train_generator,validation_generator-> 지정된 경로에서 데이터 가져오는 함수
def load_VGG16_model():
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224,224,3))
print("Model loaded")
print(base_model.summary())
return base_model-> 모델 load 함수
def extract_features_and_store(train_generator,validation_generator,base_model):
x_generator = None
y_lable = None
batch = 0
for x,y in train_generator:
if batch == int(1470/batch_size):
break
print("predict on batch:",batch)
batch+=1
if x_generator is None:
x_generator = base_model.predict_on_batch(x)
y_lable = y
else:
x_generator = np.append(x_generator,base_model.predict_on_batch(x),axis=0)
y_lable = np.append(y_lable,y,axis=0)
x_generator,y_lable = shuffle(x_generator,y_lable)
np.save(open('video_x_VGG16.npy', 'wb'),x_generator)
np.save(open('video_y_VGG16.npy','wb'),y_lable)
x_generator = None
y_lable = None
batch = 0
for x,y in validation_generator:
if batch == int(640/batch_size):
break
print("predict on batch validate:",batch)
batch+=1
if x_generator is None:
x_generator = base_model.predict_on_batch(x)
y_lable = y
else:
x_generator = np.append(x_generator,base_model.predict_on_batch(x),axis=0)
y_lable = np.append(y_lable,y,axis=0)
x_generator,y_lable = shuffle(x_generator,y_lable)
np.save(open('video_x_validate_VGG16.npy', 'wb'),x_generator)
np.save(open('video_y_validate_VGG16.npy','wb'),y_lable)
train_data = np.load(open('video_x_VGG16.npy', 'rb'))
train_labels = np.load(open('video_y_VGG16.npy', 'rb'))
train_data,train_labels = shuffle(train_data,train_labels)
validation_data = np.load(open('video_x_validate_VGG16.npy', 'rb'))
validation_labels = np.load(open('video_y_validate_VGG16.npy', 'rb'))
validation_data,validation_labels = shuffle(validation_data,validation_labels)
train_data = train_data.reshape(train_data.shape[0], train_data.shape[1] * train_data.shape[2], train_data.shape[3])
validation_data = validation_data.reshape(validation_data.shape[0], validation_data.shape[1] * validation_data.shape[2], validation_data.shape[3])
return train_data,train_labels,validation_data,validation_labels->VGG16을 통해 feature를 추출하고 저장하는 함수
def train_model(train_data,train_labels,validation_data,validation_labels):
model = Sequential()
model.add(LSTM(256,dropout=0.2,input_shape=(train_data.shape[1], train_data.shape[2])))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(3, activation='softmax'))
sgd = SGD(lr=0.00005, decay = 1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='categorical_crossentropy', metrics=['accuracy'])
callbacks = [ EarlyStopping(monitor='val_loss', patience=10, verbose=0), ModelCheckpoint('video_3_LSTM_1_1024.h5', monitor='val_loss', save_best_only=True, verbose=0) ]
epochs = 500
history=model.fit(train_data,train_labels,validation_data=(validation_data,validation_labels),batch_size=batch_size,epochs=epochs,callbacks=callbacks,shuffle=True,verbose=1)
return history-> 모델 학습하는 함수
def test_on_whole_videos(train_data,train_labels,validation_data,validation_labels):
parent = os.listdir("video")
x = []
y = []
count = 0
output = 0
count_video = 0
correct_video = 0
total_video = 0
base_model = load_VGG16_model()
model = train_model(train_data,train_labels,validation_data,validation_labels)
# model = 'video_3_LSTM_1_1024.h5'
for video_class in parent[1:]:
print(video_class)
child = os.listdir("video" + "/" + video_class)
for class_i in child[1:]:
sub_child = os.listdir("video" + "/" + video_class + "/" + class_i)
for image_fol in sub_child[1:]:
if (video_class == 'class_4' ):
if(count%4 == 0):
image = cv2.imread("video" + "/" + video_class + "/" + class_i + "/" + image_fol)
image = cv2.resize(image , (224,224))
x.append(image)
y.append(output)
#cv2.imwrite('/Users/.../video/validate/' + video_class + '/' + str(count) + '_' + image_fol,image)
count+=1
else:
if(count%4 == 0):
image = cv2.imread("video" + "/" + video_class + "/" + class_i + "/" + image_fol)
image = cv2.resize(image , (224,224))
x.append(image)
y.append(output)
count+=1
x = np.array(x)
y = np.array(y)
x_features = base_model.predict(x)
correct = 0
answer = model.predict(x_features)
for i in range(len(answer)):
if(y[i] == np.argmax(answer[i])):
correct+=1
print(correct,"correct",len(answer))
total_video+=1
if(correct>= len(answer)/2):
correct_video+=1
x = []
y = []
count_video+=1
output+=1
print("correct_video",correct_video,"total_video",total_video)
print("The accuracy for video classification of ",total_video, " videos is ", (correct_video/total_video))-> 학습 후 동영상으로 테스트 해볼 수 있는 함수
def plot_loss_acc(history,epoch):
loss, val_loss = history.history['loss'], history.history['val_loss']
accuracy, val_accuracy = history.history['accuracy'], history.history['val_accuracy']
fig, axes = plt.subplots(1,2,figsize=(12,4))
axes[0].plot(range(1, epoch+1), loss, label = 'Training')
axes[0].plot(range(1, epoch+1), val_loss, label = "Validation")
axes[0].legend(loc='best')
axes[0].set_title('Loss')
axes[1].plot(range(1, epoch+1), accuracy, label = 'Training')
axes[1].plot(range(1, epoch+1), val_accuracy, label = "Validation")
axes[1].legend(loc='best')
axes[1].set_title('Accuracy')
plt.show()-> 학습 결과 그래프로 보여주는 함수
if __name__ == '__main__':
train_generator,validation_generator = bring_data_from_directory()
base_model = load_VGG16_model()
train_data,train_labels,validation_data,validation_labels = extract_features_and_store(train_generator,validation_generator,base_model)
history = train_model(train_data,train_labels,validation_data,validation_labels)
plot_loss_acc(history, 259)train_generator,validation_generator = bring_data_from_directory()
base_model = load_VGG16_model()실행 결과
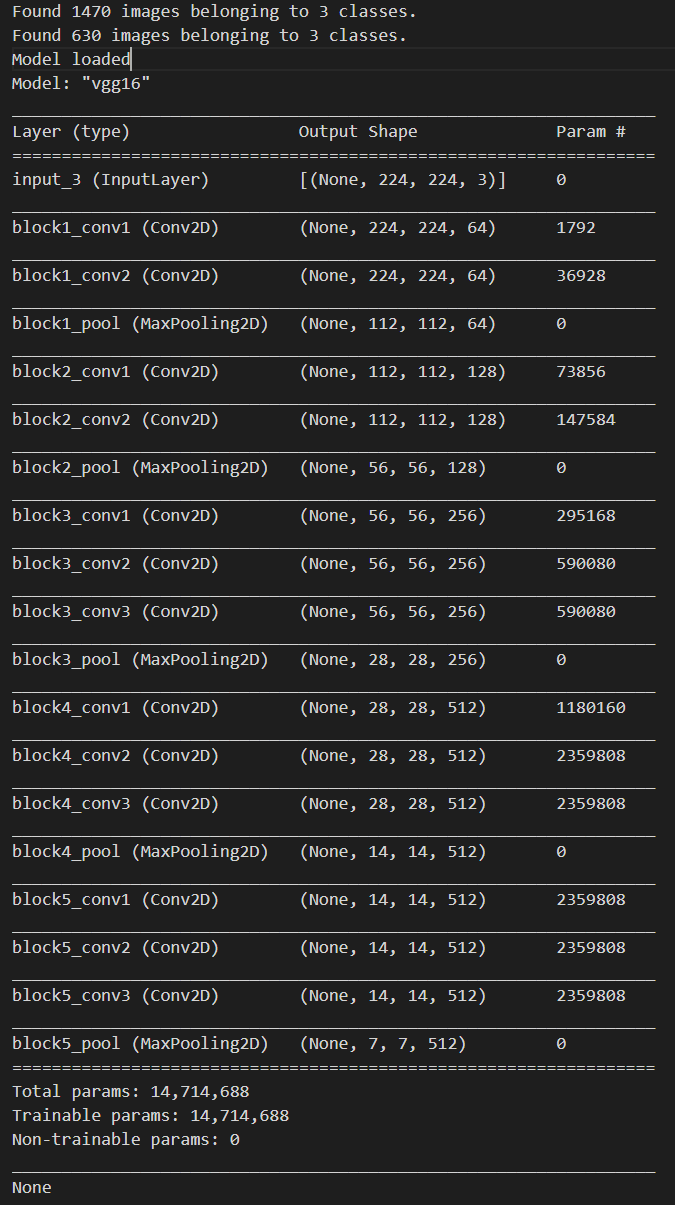
train_data,train_labels,validation_data,validation_labels = extract_features_and_store(train_generator,validation_generator,base_model)실행 결과
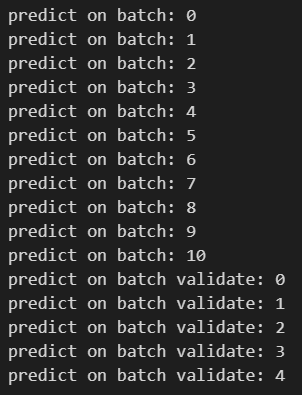
history = train_model(train_data,train_labels,validation_data,validation_labels)실행 결과
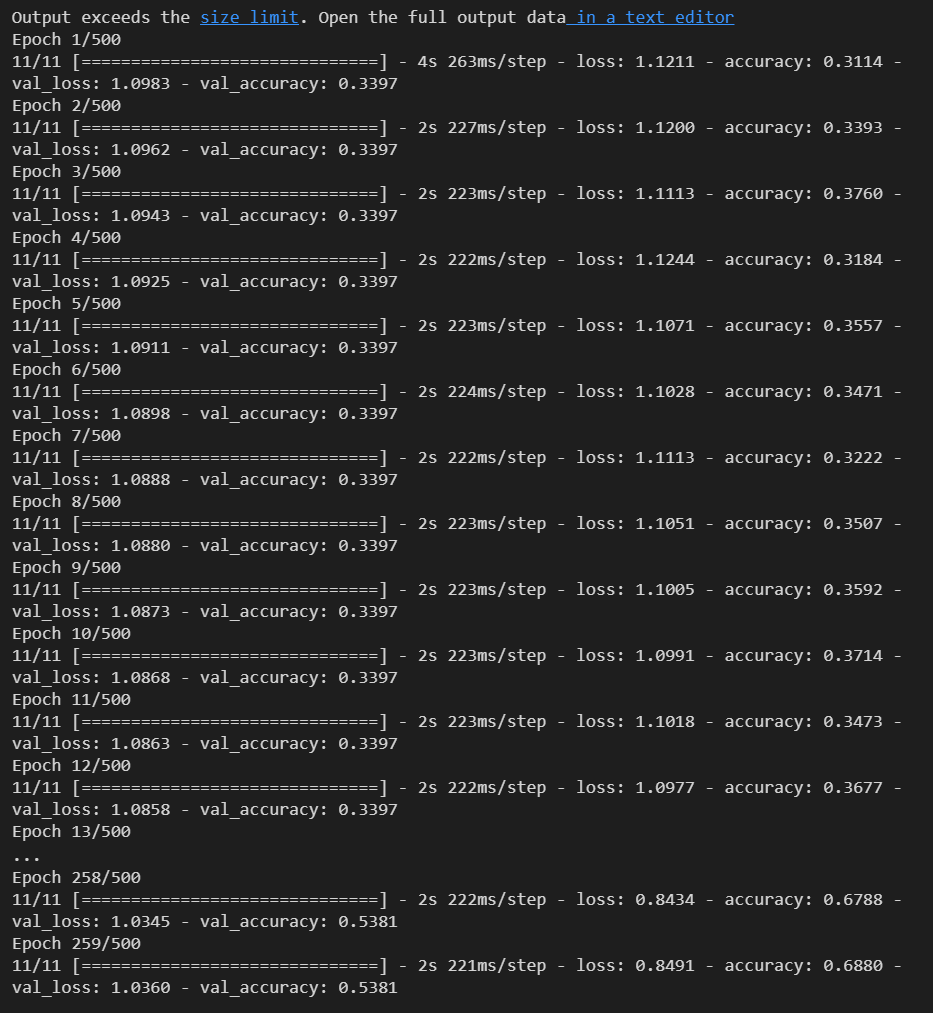
plot_loss_acc(history, 259)실행 결과

데이터셋 INPUT
-
데이터는 다음과 같은 경로로 구성되어 있었다. 그런데 어떻게 각 파일 별로 라벨링을 해서 학습을 진행하는지에 의문이 들어서, 처음에는 한 폴더만 지정하여 단어 하나만 진행하려고 했었다.
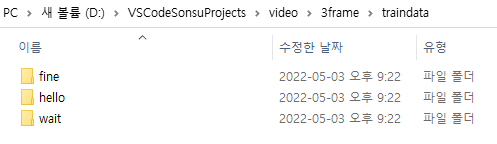
-
같이 진행하는 미서님의 도움으로 다음 코드에서 각 폴더마다 라벨링 한다는 설명을 들었다.
def bring_data_from_directory(): datagen = ImageDataGenerator(rescale=1. / 255) train_generator = datagen.flow_from_directory( train_dir, target_size=(224, 224), batch_size=batch_size, class_mode='categorical', shuffle=True, classes=['fine', 'hello', 'wait']) validation_generator = datagen.flow_from_directory( valid_dir, target_size=(224, 224), batch_size=batch_size, class_mode='categorical', shuffle=True, classes=['fine', 'hello', 'wait']) return train_generator,validation_generator -
따라서 다음과 같이 경로를 지정하여 진행했다.
train_dir='video/3frame/traindata' valid_dir='video/3frame/validationdata'
trouble shooting
- 함수 extract_features_and_store의
train_data = np.load(open('video_x_VGG16.npy'))에서 인코딩 에러가 났다.UnicodeDecodeError: 'utf-8' codec can't decode byte 0x93 in position 0: invalid start byte- 미서님의 도움으로 'rb'를 추가하여 해결했다.
train_data = np.load(open('video_x_VGG16.npy', 'rb'))
-
함수 train_model의
model.fit(train_data, train_labels, validation_data=(validation_data, validation labels), batch_size=batch_size, nb_epoch=nb_epoch, callbacks=callbacks, shuffle=True)에서 다음과 같은 오류들이 났다.-
TypeError: fit() ot an unexpected keyword arguent 'nb_epoch
https://www.codeleading.com/article/16195738314/
nb_epoch는 옛날에 쓰이던 것이고 최근에는 epochs를 사용한다고 한다. -
ValueError: Shapes (128, 3) and (128, 5) are incompatiblehttps://www.sysnet.pe.kr/2/0/12822
사실 대개의 경우 이 오류는 model.fit에 전달한 X_train, Y_train과 validation_data에 전달한 값들의 차원이 신경망의 units와 맞지 않기 때문에 발생합니다.위의 글과 미서님의 도움으로 model에 추가한 Dense layer에 출력 뉴런의 수를 확인했고, 값이 5로 되어있었다. 나는 3개의 class로 분류하였기 때문에 이를 3으로 수정해주었다.
-
함수 plot_loss_acc를 추가하면서 여러가지 오류에 직면했다. 아무래도 기존에 있던 코드가 아니라 그래프를 그리기 위해 다른 코드를 참고했더니 변수명이 다른 점 등 작은 오류가 발생하였다.
-
epoch를 500으로 지정했는데 2-3xx에서 학습이 완료되는 결과가 나왔고, 코드에 대한 이해도가 높지 않은 상태여서 그 이유를 알아내기까지 조금 긴 시간이 걸렸다.
https://tykimos.github.io/2017/07/09/Early_Stopping/
val_loss가 낮아지다가 다시 증가하는 시점이 있는데 이때 과적합이 발생했다고 볼 수 있고, 그 시점에서 epoch를 멈춰주는 것이 EarlyStopping 이었다.
하지만 그래프를 그리려면 멈춰진 epoch를 받아와야하는데 그 방법을 찾지 못해서history = model_train(...)을 하고 다음 셀에서plot_loss_acc(history, {앞에서 끝난 epoch값})을 실행했다.
-
결과
- 현재 그래프를 그리는 것까지 완료한 상태이지만 training_acc는 최종적으로 0.6xx정도로 끝났고 validation_acc는 상승하다가 다시 낮아지는 형태를 띄고 있었다.
뭔가 이상하다는 생각이 들어 다시 찾아봤는데 https://nittaku.tistory.com/289 -> 해당 링크에서는 EarlyStopping이 validation set의 accuracy가 멈추거나 낮아지는 지점에서 stop한다고 한다. 찾아본 블로그 두개의 말이 달라서 이는 다음시간에 더 진행해보기로 하였다.
다음시간에 진행 할 부분
😎 EarlyStopping에 대해 공부하기

안녕하세요 수어 인식 프로젝트 진행 중인 학생입니다. LSTM으로 진행해 보고 성능 향상을 위해 작성해 주신 내용 및 코드 참고하고 있는데 궁금한 점이 생겨 댓글 남깁니다! 데이터 셋이 어떻게 구성되어 있는지 궁금합니다. "fine"에 해당하는 수어 영상을 프레임 단위로 나눈 이미지의 집합일까요? (코드 올려주셔서 감사합니다:)