[Python] Sqlalchemy 구조 ORM, Core 에 대해
TL;DR
Python 의 대표적인 ORM 라이브러리 Sqlalchemy에 대해서 알아보기 위한 포스팅
Overview
python 을 이용해서 entity 관리를 하면서 필수적으로 사용하는 라이브러리가 아마 Sqlalchemy이지 않을까 싶을 정도로 대중적으로 사용되고 있다.
그런 Sqlalchemy는 그럼 어떻게 entity 들을 관리하고 있는 것일까?
Sqlalchemy는 자체적으로 layer를 나눠서 관리가 되고 있다.
- SQLAlchemy ORM
- SQLAlchemy Core
- DBAPI ( e.g. psycopg2, PyMySQL etc ... )
위와 같이 3가지 정도의 layer로 나눠지는다. DBAPI 같은 경우에는 Sqlalchemy에 속해있는 부분은 아니나 실제 SQLAlchemy Core layer 와 소통을 하는 부분이기 때문에 연관이 없지는 않다.
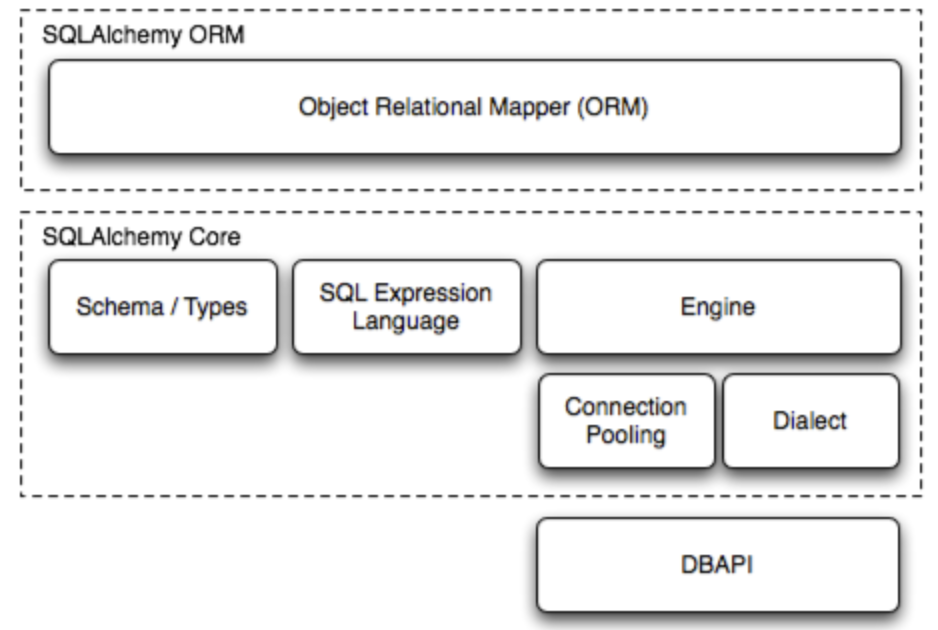
그럼 각각의 Layer에 대해서 좀 더 깊게 보자.
SQLAlchemy ORM
ORM이란?
풀어쓰면 Object Relational Mapper ( ORM )로 데이터베이스에서의 테이블의 데이터와 코드상의 객체와 연결을 지어주는 맵퍼이다.
Sqlalchemy ORM 은 Core의 기능들을 유저가 좀 더 사용하기 쉽게 고수준의 인터페이스를 제공해주는 layer이다. python class를 통해서 데이터베이스의 테이블을 정의하고 관계를 정의해서 관리할 수 있다. 또한 제공되는 함수를 통해서 DML, DDL 명령어를 수행할 수 있다.
Chat GPT 를 통해서 Sqlalchemy ORM을 사용하는 예제를 뽑아 봤다.
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# create an engine to connect to a database
engine = create_engine('postgresql://username:password@host:port/database')
# create a session factory
Session = sessionmaker(bind=engine)
# create a base class for our model classes
Base = declarative_base()
# define a model class
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
email = Column(String)
# create the database tables
Base.metadata.create_all(engine)
# create a new user and add them to the database
session = Session()
new_user = User(name='John Doe', email='john.doe@example.com')
session.add(new_user)
session.commit()
# query for all users in the database
users = session.query(User).all()
for user in users:
print(user.name, user.email)SQLAlchemy Core
Core는 가장 핵심적인 역할을 하는 계층이다. 관계형데이터베이스와의 연결을 관리하고( Connection Pooling, Engine ), 각각의 데이터베이스에 대한 데이터 유형에대한 타입핑 기능( Schema / Types ), SQL문에 대한 프로그래밍 방식 구현 ( SQL Expression Language ) 등을 담당하고 있다.
각각에 대해서 실제 코드를 보면서 알아보자.
Engine
database 와 소통하기 위한 connection을 관리해주는 역할을 해준다. connections pool 을 관리하고 sql 문을 실행하는 기능도 제공되고 Transaction또한 관리를 해주게 된다. engine 을 사용하기 위해서는
위의 ORM 예시에 있는 코드 처럼
# create an engine to connect to a database
engine = create_engine('postgresql://username:password@host:port/database', pool_size=20)
# create a session factory
Session = sessionmaker(bind=engine)engine 객체를 만들어 줘야 한다. engine 과 binding 시켜서 session을 만들어서 사용을 할 수도 있다. engine, session 모두 내장되어 있는 함수를 통해서 sql statement 를 실행시킬 수 있는데 이러한 점이 사용자가 데이터베이스의 종류에 무관하게 코드의 일관성을 유지할 수 있게 해주는 부분이다. ( 일부 Configuration에 대한 변경은 필요함 )
session을 사용하는 이유는 engine 보다 고수준 API로 error handling에 더 견고하고 engine 보다 multithread, multiprocessing 작업에 더 safe 하게 동작하기 때문에 session의 사용이 권장된다.
Connection Pooling
Connection pool 은 engine 에서 관리가 된다. engine 을 처음 생성할 때 pool 에 대한 option들을 parameter로 설정할 수 있다.
connection pool은 연결의 재사용을 위해서 pre-established 된 연결들을 사용되어도 가지고 유지하고 있다.
engine 에서 connection의 사용이 필요하다면 우선 pool에 재사용이 가능한 connection이 있다면 가져오게 되고 없다면 engine 에서 새로운 connection을 만들게 된다. 사용된 connection은 다시 connection pool로 반납되게 되고 그 다음 사용자가 connection 을 재사용하게 된다.
Dialect
특정 database 와의 상호작용을 위한 서포트를 해주게 된다. 데이터베이스마다 제공되어 지는 기능들이 모두 다르고 지정할 수 있는 데이터 타입등도 판이하다. 따라서 이를 사용자가 일괄적이 사용을 할 수 있도록 adaptor 로서의 역할을 한다고 볼 수 있다.
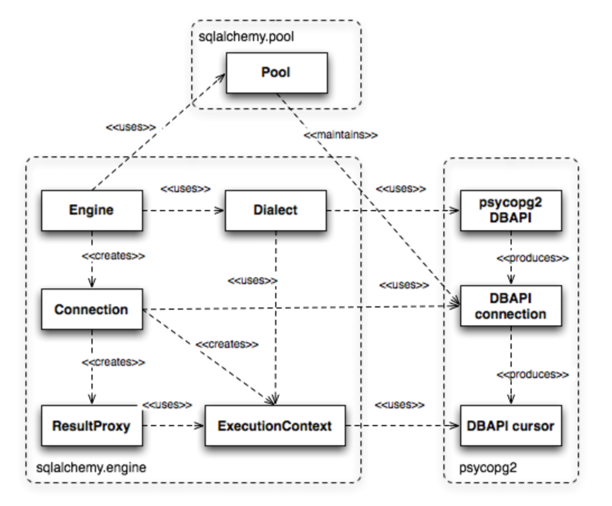
ResultProxy, ExecutionContext라는 개념이 나오게 되는데
ResultProxy란 engine의 실행결과에 대한 정보를 담고있는 객체로 이해하면 된다. 부가적인 기능들이 제공되는데 fetchone, fetchall 이라던가 columns에 대한 정보를 얻을 수 있는 keys 기능도 제공해준다.
또한 결과 값을 다 사용했다면 close()를 통해서 memory를 반환처리할 수 있다.
ExecutionContext 는 해당 작업이 실행된 connection의 id 라던가 last row 의 id등과 같은 metadata 정보를 담고 있는 객체이다.
from sqlalchemy import create_engine, select, Table, Column, Integer, String, MetaData
engine = create_engine('postgresql://user:password@localhost/mydatabase')
metadata = MetaData(bind=engine)
mytable = Table('mytable', metadata,
Column('id', Integer, primary_key=True),
Column('name', String),
Column('age', Integer),
)
stmt = select([mytable])
result_proxy = engine.execute(stmt)
# iterate over rows
for row in result_proxy:
print(row)
# fetch a single row
row = result_proxy.fetchone()
print(row)
# fetch all rows as a list
rows = result_proxy.fetchall()
print(rows)
# get the ExecutionContext object
context = result_proxy.context
print(context)Schema / Type
위에 예제들에서도 많이 살펴본 Table, Column, Schema 등이 Schema / Type 이다
from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData, Numeric
engine = create_engine('postgresql://user:password@localhost/mydatabase')
metadata = MetaData(bind=engine)
mytable = Table('mytable', metadata,
Column('id', Integer, primary_key=True),
Column('name', String),
Column('price', Numeric(precision=10, scale=2)),
)
이외에도 group_by, join, order_by등 다양한 기능들을 사용할 수 있다.
Reference
