TL:DR;
queue 길이에 따른 autoscaling이 필요했는데 기존 metrics-api, custom-api로는 커버가 되지 않아서 검색해보다 keda 라는 open-source 프로젝트를 발견했다.
실제 keda를 적용해보면서 필요한 지식들을 정리해보자!
그전에 HPA (Horizontal Pod Autoscaler) 란?
Keda는 궁극적으로 HPA를 이용해서 Deployment, Replicaset, Job 등을 autoscaling 하게 된다. 따라서 HPA가 어떻게 동작하는지에대해 간단하게 알아보자.
HPA는 Kubernetes에서 기본적으로 제공해주는 object이다. Pod의 resource ( cpu, memory ) 들을 확인하고 이를 바탕으로 유저가 세팅해놓은 configuration 값의 임계치를 벗어났을 때 정해진 rule 대로 pod의 갯수를 scale-in, scale-out 하게된다.
그렇다면 해당 resource ( cpu, memory ) 값은 어디서 가져오는가?
kubernetes 의 각 노드에는 기본적으로 kubelet이 존재한다. kubelet 은 api-server 와 통신을 하는 역할을 하거나 해당 node에 특정 명령을 내려주게 되는데 kubelet 에는 cAdvisor라는 Resource Estimater가 존재한다.
Controller Runtime ( Docker, rkt, CoreOS ) 를 통해 각 pod container 의 resource를 cAdvisor가 수집하게된다.
이제 해당 정보를 가져와서 얻을 수 있게 해주는 server 가 metrics-server 이다 AddOn Component로 기본적으로 존재하지는 않고 따로 설치를 해줘야한다. ( AWS EKS 환경 또한 metrics-server가 기본으로 깔려있지는 않음 )
이렇게 설치한 metrics-server 는 각 node의 kubelet 에서 resource 데이터를 가져오게 되고 metrics-api ( kube-apiserver 에서 구동됨 ) 를 통해서 hpa가 해당 정보를 수집하여 볼 수 있도록 만들어 주게 되는 것이다.
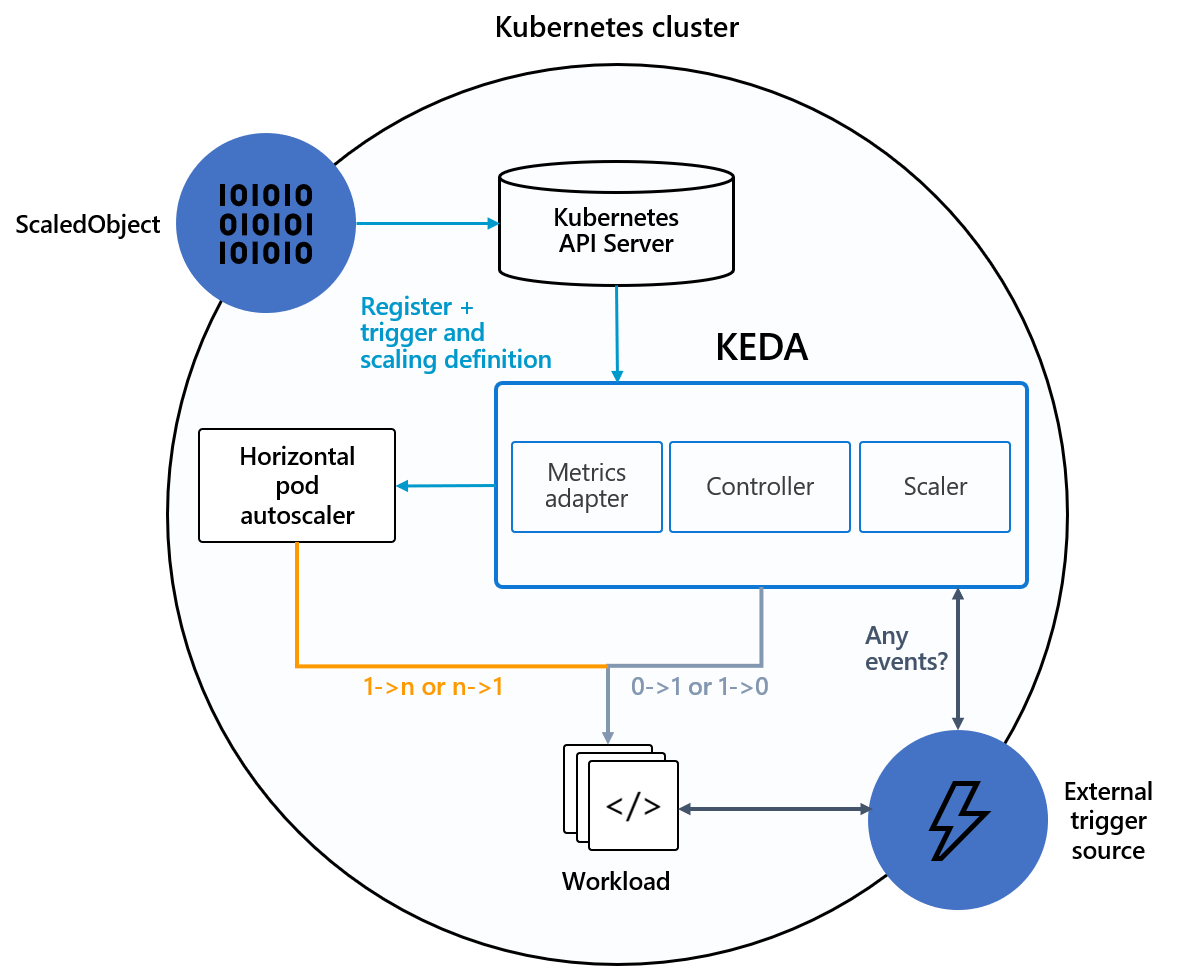
Keda는 HPA를 어떻게 활용하는가?
Keda를 설치하면 Custom object인 scaledobjects, scaledjobs 가 생성된다.
scaledobjects 는 Deployment, statefulset, Custom Resource ( /scale subresource가 정의 돼있어야함 ) 를 autoscaling하는데 사용되고 scaledjobs 는 Job, CronJob등을 autoscaling할 때 사용된다.
scaledobjects의 명세는 아래와 같이 정의할 수 있다.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
idleReplicaCount: 0 # Optional. Default: ignored, must be less than minReplicaCount
minReplicaCount: 1 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
fallback: # Optional. Section to specify fallback options
failureThreshold: 3 # Mandatory if fallback section is included
replicas: 6 # Mandatory if fallback section is included
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
name: {name-of-hpa-resource} # Optional. Default: keda-hpa-{scaled-object-name}
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}참조 하고자하는 target 의 정보를 spec.scaleTargetRef에 작성해주고 나머지 configuration들을 상황에 맞게 작성해주면 된다.
위 설정값중 triggers를 정의한 방식대로 scale in/out이 일어나게 된다.
Triggers
Keda는 작성일 기준 59개의 scaler의 사용이 가능한데 대부분의 유명 프로젝트들은 support하고 있다. ( Kafka, AWS, GCP, redis, prometheus etc... )
여기서 필요한 scaler 의 타입을 설정하고 그에 맞는 metadata를 작성하면 원하는 조건의 autoscaler를 구현할 수 있게 된다.
triggers:
- type: redis
metadata:
address: broker_url
listName: queue_name ( key )
listLength: "1000"실제 redis는 다음과 같이 설정해서 해당 queue의 길이가 1000이 넘게 될 때 autoscaling이 가능하도록 설정하였다.
ScaledObject 와 HPA
위와 같은 설정을 마치고 ScaledObject를 배치시키게 되면 scaledObject를 ref(label, annotation) 하는 HPA 가 생성된다. scaledObject에서 trigger에 설정된 값을 감시하다가 변경이 일어나면 hpa 의 replica 값을 변경시켜서 hpa 가 target 하고 있는 object를 scaling하게 되는 방식이다.
Install Keda
Keda 설치는 helm 을 이용할 수도 있고 제공해주는 sample deployment yaml 파일을 이용해서도 배포가 가능하다. sample deployment.yaml 을 통해서 keda 를 배포해보자
# Including admission webhooks
kubectl apply -f https://github.com/kedacore/keda/releases/download/v2.10.0/keda-2.10.0.yaml
# Without admission webhooks
kubectl apply -f https://github.com/kedacore/keda/releases/download/v2.10.0/keda-2.10.0-core.yaml다음을 통해서 keda yaml 명세를 받을 수 있고 해당 명세를 그대로 사용하거나 사용자에 맞게 설정변경해서 적용할 수도 있다.
# Including admission webhooks
kubectl apply -f keda-2.10.0.yaml
# Without admission webhooks
kubectl apply -f keda-2.10.0-core.yaml다음을 통해 설치가 완료되면 keda resource들이 배포되게 된다.
kubectl get all -n keda
keda resouce 배포가 끝나면 ScaledObject를 배포를 통해서 원하는 deployment에 대한 custom metric을 통한 hpa가 가능하게 된다.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: foo-1
namespace: airflow
spec:
scaleTargetRef:
name: foo-1-deploy
pollingInterval: 3
minReplicaCount: 1
maxReplicaCount: 5
triggers:
- type: redis
metadata:
address: ${BROKER_URL}
listName: default
listLength: "30"
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: foo-2
namespace: airflow
spec:
scaleTargetRef:
name: foo-2-deploy
pollingInterval: 3
minReplicaCount: 1
maxReplicaCount: 1
triggers:
- type: redis
metadata:
address: ${BROKER_URL}
listName: nft_worker
listLength: "1000"
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: foo-3
namespace: airflow
spec:
scaleTargetRef:
name: foo-3-deploy
pollingInterval: 3
minReplicaCount: 1
maxReplicaCount: 3
triggers:
- type: redis
metadata:
address: ${BROKER_URL}
listName: nft_market_worker
listLength: "10"
---Reference

!! 좋은 글 감사합니다