Hash 원리
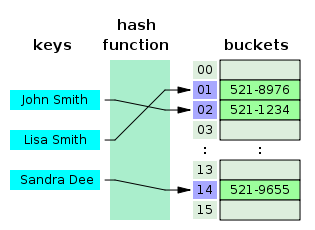
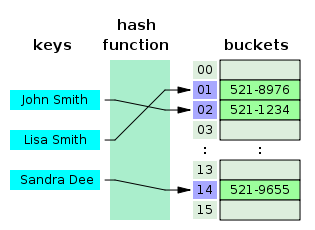
해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조이다. 해시 테이블이 빠른 검색속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문이다. 해시 테이블은 각각의 Key값에 해시함수를 적용해 배열의 고유한 index를 생성하고, 이 index를 활용해 값을 저장하거나 검색하게 된다. 여기서 실제 값이 저장되는 장소를 버킷 또는 슬롯이라고 한다.
값을 저장하기 위해 index = X.hashCode() % M(배열 크기); 지정한다.
해시맵의 초기 용량은 16이고 75%이상 차면 용량을 2배로 늘리는 작업이 일어난다. 용량이 큰 경우 초기 용량을 크게 잡아줘야 성능이 좋다.
예를 들어 우리가 (Key, Value)가 ("John Smith", "521-1234")인 데이터를 크기가 16인 해시 테이블에 저장한다고 하자. 그러면 먼저 index = hash_function("John Smith") % 16 연산을 통해 index 값을 계산한다. 그리고 array[index] = "521-1234" 로 전화번호를 저장하게 된다.
이러한 해싱 구조로 데이터를 저장하면 Key값으로 데이터를 찾을 때 해시 함수를 1번만 수행하면 되므로 매우 빠르게 데이터를 저장/삭제/조회할 수 있다. 해시테이블의 평균 시간복잡도는 O(1)이다.
💡 각각의 Key값은 해시함수에 의해 고유한 index를 가지게 되어 바로 접근할 수 있으므로 평균 O(1)의 시간복잡도로 데이터를 조회할 수 있다. 하지만 데이터의 충돌이 발생한 경우 Chaining에 연결된 리스트들까지 검색을 해야 하므로 O(N)까지 시간복잡도가 증가할 수 있다.여기서 1/m 확률로 같은 공간을 사용하게 되는데 이걸 해시 충돌이라고 부르고 open addressing 과 Separate Chaining 두가지 방식으로 자료구조를 관리한다.
open addressing
해시 충돌이 발생하면, (즉 삽입하려는 해시 버킷이 이미 사용 중인 경우) 다른 해시 버킷에 해당 자료를 삽입하는 방식 이다. 버킷이란 바구니와 같은 개념으로 데이터를 저장하기 위한 공간이라고 생각하면 된다. 다른 해시 버킷이란 어떤 해시 버킷을 말하는 것인가?
공개 주소 방식이라고도 불리는 이 알고리즘은 Collision 이 발생하면 데이터를 저장할 장소를 찾아 헤맨다. Worst Case 의 경우 비어있는 버킷을 찾지 못하고 탐색을 시작한 위치까지 되돌아 올 수 있다. 이 과정에서도 여러 방법들이 존재하는데, 다음 세 가지에 대해 알아보자.
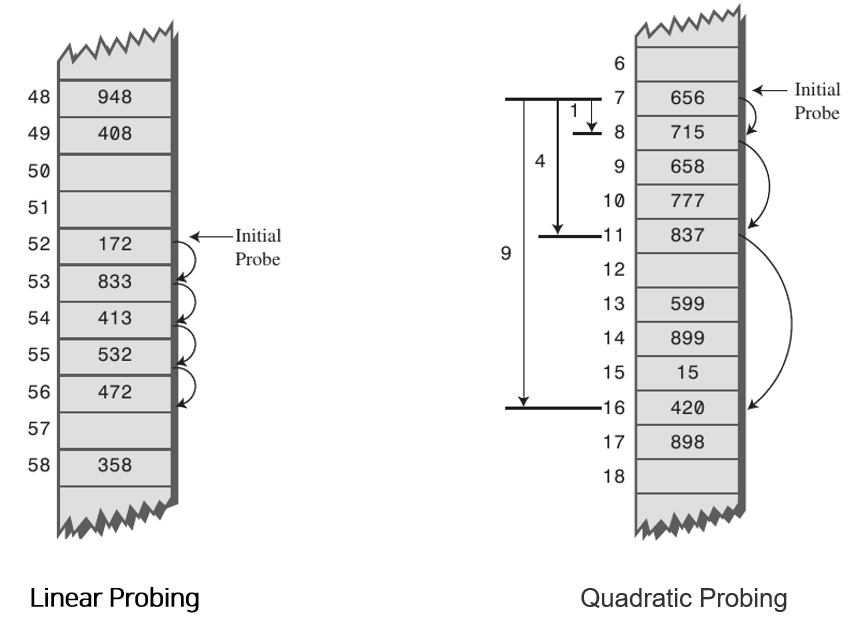
- Linear Probing 순차적으로 탐색하며 비어있는 버킷을 찾을 때까지 계속 진행된다.
- Quadratic probing 2 차 함수를 이용해 탐색할 위치를 찾는다.
- Double hashing probing 하나의 해쉬 함수에서 충돌이 발생하면 2 차 해쉬 함수를 이용해 새로운 주소를 할당한다. 위 두 가지 방법에 비해 많은 연산량을 요구하게 된다.
Open Addressing에서 데이터를 삭제하면 삭제된 공간은 Dummy Space로 활용되는데, 그렇기 때문에 Hash Table을 재정리 해주는 작업이 필요하다고 한다.
Separate Chaining
일반적으로 Open Addressing 은 Separate Chaining 보다 느리다. Open Addressing 의 경우 해시 버킷을 채운 밀도가 높아질수록 Worst Case 발생 빈도가 더 높아지기 때문이다. 반면 Separate Chaining 방식의 경우 해시 충돌이 잘 발생하지 않도록 보조 해시 함수를 통해 조정할 수 있다면 Worst Case 에 가까워 지는 빈도를 줄일 수 있다. Java 7 에서는 Separate Chaining 방식을 사용하여 HashMap 을 구현하고 있다. Separate Chaining 방식으로는 두 가지 구현 방식이 존재한다.
💡 보조 해시 함수(supplement hash function)의 목적은 `key`의 해시 값을 변형하여 해시 충돌 가능성을 줄이는 것이다. `Separate Chaining`방식을 사용할 때 함께 사용되며 보조 해시 함수로 Worst Case 에 가까워지는 경우를 줄일 수 있다.- 연결 리스트를 사용하는 방식(Linked List) 각각의 버킷(bucket)들을 연결리스트(Linked List)로 만들어 Collision 이 발생하면 해당 bucket 의 list 에 추가하는 방식이다. 연결 리스트의 특징을 그대로 이어받아 삭제 또는 삽입이 간단하다. 하지만 단점도 그대로 물려받아 작은 데이터들을 저장할 때 연결 리스트 자체의 오버헤드가 부담이 된다. 또 다른 특징으로는, 버킷을 계속해서 사용하는 Open Address 방식에 비해 테이블의 확장을 늦출 수 있다.
- Tree 를 사용하는 방식 (Red-Black Tree) 기본적인 알고리즘은 Separate Chaining 방식과 동일하며 연결 리스트 대신 트리를 사용하는 방식이다. 연결 리스트를 사용할 것인가와 트리를 사용할 것인가에 대한 기준은 하나의 해시 버킷에 할당된 key-value 쌍의 개수이다. 데이터의 개수가 적다면 링크드 리스트를 사용하는 것이 맞다. 트리는 기본적으로 메모리 사용량이 많기 때문이다. 데이터 개수가 적을 때 Worst Case 를 살펴보면 트리와 링크드 리스트의 성능 상 차이가 거의 없다. 따라서 메모리 측면을 봤을 때 데이터 개수가 적을 때는 링크드 리스트를 사용한다.
데이터가 적다는 것은 얼마나 적다는 것을 의미하는가? 앞에서 말했듯이 기준은 하나의 해시 버킷에 할당된 key-value 쌍의 개수이다. 이 키-값 쌍의 개수가 6 개, 8 개를 기준으로 결정한다. 기준이 두 개 인것이 이상하게 느껴질 수 있다. 7 은 어디로 갔는가? 링크드 리스트의 기준과 트리의 기준을 6 과 8 로 잡은 것은 변경하는데 소요되는 비용을 줄이기 위함이다.
한 가지 상황을 가정해보자. 해시 버킷에 6 개 의 key-value 쌍이 들어있었다. 그리고 하나의 값이 추가되었다. 만약 기준이 6 과 7 이라면 자료구조를 링크드 리스트에서 트리로 변경해야 한다. 그러다 바로 하나의 값이 삭제된다면 다시 트리에서 링크드 리스트로 자료구조를 변경해야 한다. 각각 자료구조로 넘어가는 기준이 1 이라면 Switching 비용이 너무 많이 필요하게 되는 것이다. 그래서 2 라는 여유를 남겨두고 기준을 잡아준 것이다. 따라서 데이터의 개수가 6 개에서 7 개로 증가했을 때는 링크드 리스트의 자료구조를 취하고 있을 것이고 8 개에서 7 개로 감소했을 때는 트리의 자료구조를 취하고 있을 것이다.
자바 HashTable, HashMap 차이
- 중복 키에 대한 처리
- 해시 테이블 - 초기 값 유지 / 해시 맵 - 두번쨰 값 덮어버림
- 쓰레드 세이프한 해시 테이블
- 해시 테이블 함수는 synchronized가 걸려있어 멀티 스레드 환경에서 데이터 주작에 대한 일관성 보장.
- ‘Colleactions.synchronizedMap’처럼 synchronized를 래핑하는 함수를 활용하면 HashMap도 충분히 스레드 세이프하게 동작 가능
- 쓰레드 세이프한 구현체인 ConCurrentHashMap을 사용해도 괜춘(null 키도 허용x)
- 단, synchronized 처리 없는 해시 맵 속도가 압도적 빠름
- 해시맵은 키에 널 값 허용
출처
https://mangkyu.tistory.com/102
https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/DataStructure#hash-table
https://nhj12311.tistory.com/512#
