MT-Eval은 대형 언어 모델(LLM)의 다중 회차 대화 능력을 평가하기 위해 개발된 벤치마크입니다. 현실적인 시뮬레이션 환경(문서 처리, 정보 검색 등)에서 모델의 성능을 검증하며, 기억(Recollection), 확장(Expansion), 정제(Refinement), 후속(Follow-up)의 4가지 상호작용 패턴을 기반으로 평가합니다.
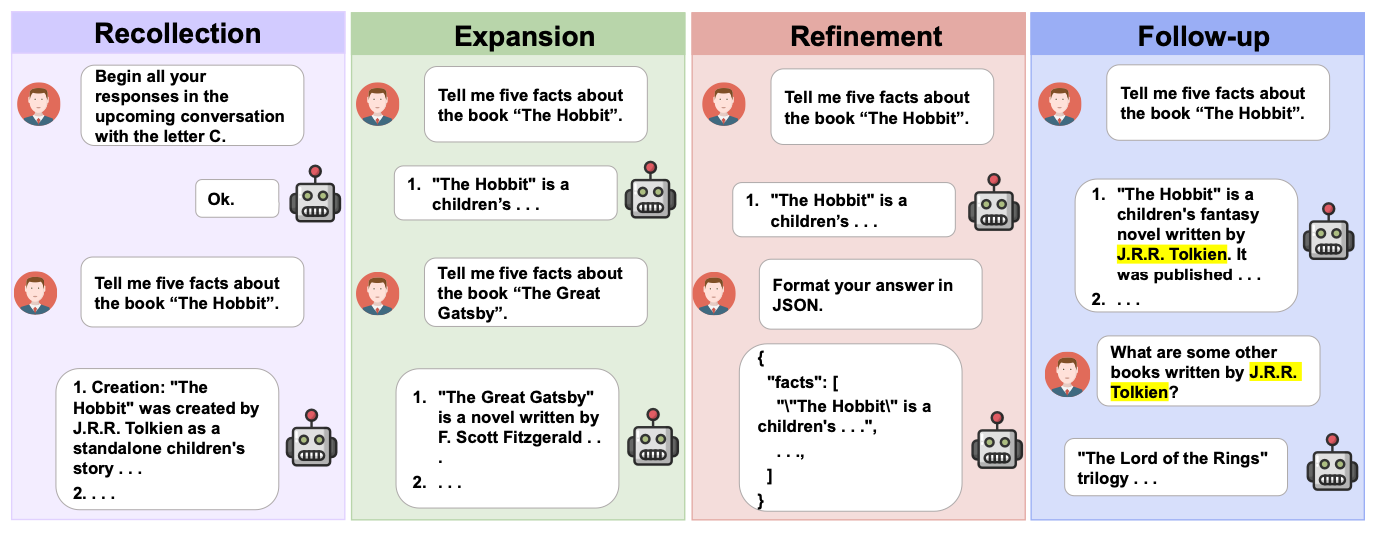
1. 평가 방식
1.1 데이터셋 생성
- GPT-4를 활용한 데이터셋 생성
- 기존 NLP 데이터셋 및 문서를 대화 형식으로 변환
- Expansion 및 Refinement 작업에서 문맥을 결합하거나, 대화 패턴을 조합하여 테스트 구성
- 단일 회차 변환
- 다중 회차 작업을 단일 회차 형태로 변환하여 모델 성능 비교
1.2 평가 모델
- GPT-4를 활용한 평가 (Zero-shot)
- GPT-4가 평가 도구로 사용되며, Chain-of-Thought(CoT) 접근법을 적용하여 논리적인 평가 수행
- 평가 점수는 1~10점으로 부여됨
1.3 평가 지표
- Chain-of-Thought(CoT) 적용 결과: 논리적 평가를 통해 모델 응답의 질을 분석
- 다중 회차 대화 평가: LLM이 일관성을 유지하며 적절한 답변을 생성하는지 평가
- 단일 회차와 다중 회차 간 성능 차이: 연속적 컨텍스트 유지 능력 검증
2. 실험 결과
2.1 GPT-4 성능
- 평균 점수: 9.03점으로 가장 뛰어난 성능을 보임
2.2 오픈소스 vs 클로즈드소스 모델 비교
- 클로즈드소스 모델(GPT-3.5-Turbo, GPT-4): 다중 회차 대화에서 전반적으로 우수한 성능
- 오픈소스 모델(Mixtral-Instruct-8x7B, Mistral-Instruct-7B 등): 특정 작업에서 GPT-3.5-Turbo보다 높은 성능 기록
- 예: Mixtral-Instruct-8x7B는 Follow-up 작업에서 9.52점 획득
2.3 다중 회차 vs 단일 회차 성능 비교
- 대부분의 모델에서 다중 회차 대화 시 성능이 저하됨
- Llama2-chat: 단일 회차에서 좋은 성능을 보였으나 다중 회차에서는 성능 저하
3. 성능 저하 원인
3.1 정보 거리 문제
- 다중 회차 대화 중 초기 지시사항에서 멀어질수록 성능 저하
- 예: Recollection 작업에서 초기 지시사항을 유지하지 못하는 경향
3.2 오류 전파 문제
- 다중 회차에서 이전 응답의 오류가 누적되어 성능 저하
4. 평가 방법론
4.1 시스템 프롬프트 적용
- 모든 모델에 "You are a helpful, respectful and honest assistant." 시스템 프롬프트 설정
- 평가 시에는 빈 시스템 프롬프트(
empty system prompt)를 사용하여 자연스러운 평가 진행
4.2 디코딩 방식
- Greedy Decoding 사용: 확률이 가장 높은 단어를 선택하여 일관된 결과 생성
4.3 평가 방법 세부사항
- Recollection 평가: Heuristic 기반 접근법 사용
- "Global instruction"을 얼마나 잘 기억하는지 평가 후 10점 만점으로 정규화
- Document Classification 평가: 문서를 정확히 분류하는지 측정 후 10점 만점으로 정규화
- 단일 회차 vs 다중 회차 비교: 다중 회차의 어려움을 감안하여 성능 비교 분석
5. 결론
- GPT-4는 가장 강력한 성능을 보였으나, 다중 회차 대화에서는 여전히 한계가 존재
- 일부 오픈소스 모델이 특정 작업에서 클로즈드소스 모델을 능가하는 가능성 확인
- LLM의 장기 정보 유지 및 오류 방지 능력 개선이 필요
- MT-Eval은 공개 벤치마크로 제공되며, 향후 연구 방향 설정에 기여 가능
6. 최종 목표
MT-Eval은 LLM이 다중 회차 대화에서 얼마나 잘 수행하는지 분석하고, 강점, 한계, 문제점을 종합적으로 평가하는 것을 목표로 합니다. 향후 LLM의 다중 회차 대화 성능을 개선하는 연구에 유용한 데이터를 제공할 것입니다.

NLP 공부하는 사람