
Multi-Task Learning(MTL)이란?
여러 관련 task에 포함된 유용한 정보를 활용하여 모든 task의 전반적인 성능을 향상시키는 목표를 가진 머신 러닝의 학습 패러다임이다.
MTL 동기
MTL의 중요한 동기는 데이터 희소성 문제를 완화하는 것이다.
각 task에 대해 더 정확한 학습자를 얻기 위해 Data Augmentation 정신으로 모든 task에 대한 데이터를 모은다. 단일 task 학습과 비교하면 다른 학습 task에서 더 많은 데이터를 활용한다.
기존의 방식과 차이
1. MTL vs. 전이 학습
둘은 비슷하면서 상당한 차이가 있다.
- MTL에서는 서로 다른 task 간의 구분이 없으며 모든 task의 성능을 향상시키는 것이 목표이다.
- 전이 학습은 source task의 도움을 받아 target task의 성능을 향상시키는 것이므로 target task가 source task보다 더 중요한 역할을 한다.
knowledge transfer 관점에서, 전이 학습에서의 knowledge transfer은 source task에서 target task까지이지만, 다중 과제 학습에서은 모든 task 쌍 간에 지식 공유가 있다.
![]() A survery on Multi-task learning(IEEE Transaction KDE,2021)
A survery on Multi-task learning(IEEE Transaction KDE,2021)
2. MTL vs. multi-label learning / multioutput regression
- MTL은 서로 다른 task는 서로 다른 데이터를 보유한다.
- 다중 레이블 학습 및 다중 출력 회귀 분석은 서로 다른 task는 동일한 데이터를 보유한다.
![]() A survery on Multi-task learning(IEEE Transaction KDE,2021)
A survery on Multi-task learning(IEEE Transaction KDE,2021)
3. MTL vs. multi-view learning
- multi-view 학습은 각 데이터 포인트가 각각 기능 세트로 구성된 여러 view와 연관되어 있다.
서로 다른 view가 서로 다른 기능 세트를 가지고 있더라도, 모든 view를 함께 사용하여 동일한 task에 대해 학습한다. 때문에 multi-view 학습은 MTL과 다른 다중 기능 세트를 가진 단일 task 학습에 속한다.
![]() A survery on Multi-task learning(IEEE Transaction KDE,2021)
A survery on Multi-task learning(IEEE Transaction KDE,2021)
MTL 종류
1. Homogeneous-feature MTL vs. Heterogeneous-feature MTL
이 때, 각 training set이 같은 feature space에 놓여 있다면 homogeneous-feature MTL이라고 한다. 그렇지 않은 경우는 heterogeneous-feature MTL이라고 하는데, heterogeneous MTL과 구분해야한다.
2. Homogeneous MTL vs Heterogeneous MTL
두 MTL의 구분은 각 task의 학습 방법의 단일성이 결정한다.
- 각 task들이 동일하게 supervised learning(classification)을 사용한다면, homogeneouse MTL이라고 할 수 있다.
- 만약 그렇지 않고 각 task들이 classification과 regression 혹은 supervised와 semi-supervised or reinforcement learning 같이 다른 학습 방법을 사용한다면 heterogeneous MTL이라고 부른다.
특별한 설명이 없다면 기본은 homogeneous-feature MTL과 homogeneous MTL이다.
MTL 해결해야할 문제
1. 공유 시기
- Task를 언제까지 공통으로 학습시킬 것인가?
- Task 간에 언제 지식을 전달할 것인가?
2. 공유 대상
일반적으로 공유 대상에는 feature, instance, parameter 3가지가 있다.
- feature: 서로 다른 task 간의 공통 feature을 배우는 것을 목표로 한다.
- instance: 유용한 데이터 instance를 식별한 다음 식별된 instance를 통해 지식을 공유하려고 한다.
- parameter: 정규화와 같은 일부 방법으로 다른 task에서 모델 parameter를 학습하는 데 도움을 주기 위해 task에서 모델 parameter(예: 선형 모델의 bias 또는 심층 모델의 weight)를 사용한다.
기존 MTL 연구는 주로 feature 기반 및 parameter 기반 방법에 중점을 두고 있으며, instance 기반 방법에 속하는 task는 거의 없다.
3. 공유 방법
task 간 지식을 공유할 수 있는 구체적인 방법을 말한다.
Feature-based MTL
- feature learning approach : 얕은 모델 또는 깊은 모델을 기반으로 여러 task에 대한 공통 feature representation을 학습하는 데 중점을 두는데, 여기서 학습된 공통 feature representation은 원래 feature representation의 부분 집합 또는 변환일 수 있다.
Parameter-based MTL
- low-rank approach : 여러 task의 관련성을 task의 parameter matrix의 낮은 순위로 해석한다.
- task clustering apprach : 각각 유사한 task를 포함하는 task cluster를 식별하는 것입니다.
- task relation learning approach : 데이터에서 task 간의 양적 관계를 자동으로 학습하는 것을 목표로 한다.
- decomposition approach : 모든 task의 모델 parameter를 둘 이상의 구성 요소로 분해하며, 이는 다른 정규자에 의해 불이익을 받는다.
Parameter Sharing Method
Sharing Method는 크게 weight를 모두 공유하는 hard-parameter sharing과 feature나 weight의 정보를 공유(그대로 복사x)하는 soft-parameter sharing이 존재합니다.
- Hard-parameter sharing: Shared feature network + task-specific network로 구성이 되며, task가 서로 많이 다를 경우, shared feature network의 깊이가 얕아져서 다른 task-specific하게 동작하게 합니다. Negative Transfer 현상이 빈번히 발생하며, 해당 network는 그 task끼리의 조합에만 유효한 경우가 대부분입니다. (Adhoc network)
![]() An overview of multi-task learning in deep neural networks (arXiv preprint arXiv:1706.05098, 2017)
An overview of multi-task learning in deep neural networks (arXiv preprint arXiv:1706.05098, 2017)
- Soft-parameter sharing: 주로 feature sharing을 하며, task 별로 network를 각각 가지기 때문에 메모리를 많이 먹고, 적절한 network를 구성하였을 때, task별로 capacity가 달라 overfitting이 특정 task에만 일어나는 단점이 존재하기도 한다.
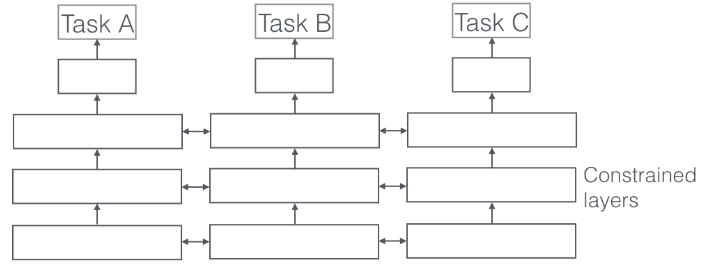 An overview of multi-task learning in deep neural networks (arXiv preprint arXiv:1706.05098, 2017)
An overview of multi-task learning in deep neural networks (arXiv preprint arXiv:1706.05098, 2017)
MTL 추후 연구 방향
-
서로 무관한 task끼리 MTL을 할 때 각 task의 성능을 저해하는 것에 대한 자세한 연구가 필요하다.
-
딥 러닝에서의 MTL방식은 많이 제안되었지만 모든 task가 관련될 때 강력하지만, 성능이 크게 저하될 수 있는 노이즈가 많고 특이치 작업에 취약하다. 유연하고 강력한 심층 작업 모델을 설계하는 연구가 필요하다.
-
비지도 학습, 준지도 학습, 능동 학습, 다중 시점 학습 및 강화 학습 과제와 MTL의 연구가 진행되어야 한다.
Reference
- https://mapadubak.tistory.com/40
- https://3neutronstar.tistory.com/3
- Zhang, Yu, and Qiang Yang. "A survey on multi-task learning." IEEE Transactions on Knowledge and Data Engineering (2021).
- Ruder, Sebastian. "An overview of multi-task learning in deep neural networks." arXiv preprint arXiv:1706.05098 (2017).
