
기존의 한국 블로글들을 살펴보면 간단하게 파일을 업로드만 하고 끝낸 곳들이 많았다. 그래서 나는 좀 더 다양한 실습을 다뤄보고 싶어 외국 사이트들을 참조했다. 한글로도 있으면 좋을듯해 다음과 같은글을 작성한다. 간단한 이론과 실습에 대해서 서술한다. 공부하는 사람임으로 틀린 정보가 있을수도 있다! 틀린 부분은 댓글로 알려주시면 감사합니다. (。・∀・)ノ゙
IPFS 컨텐츠 과정
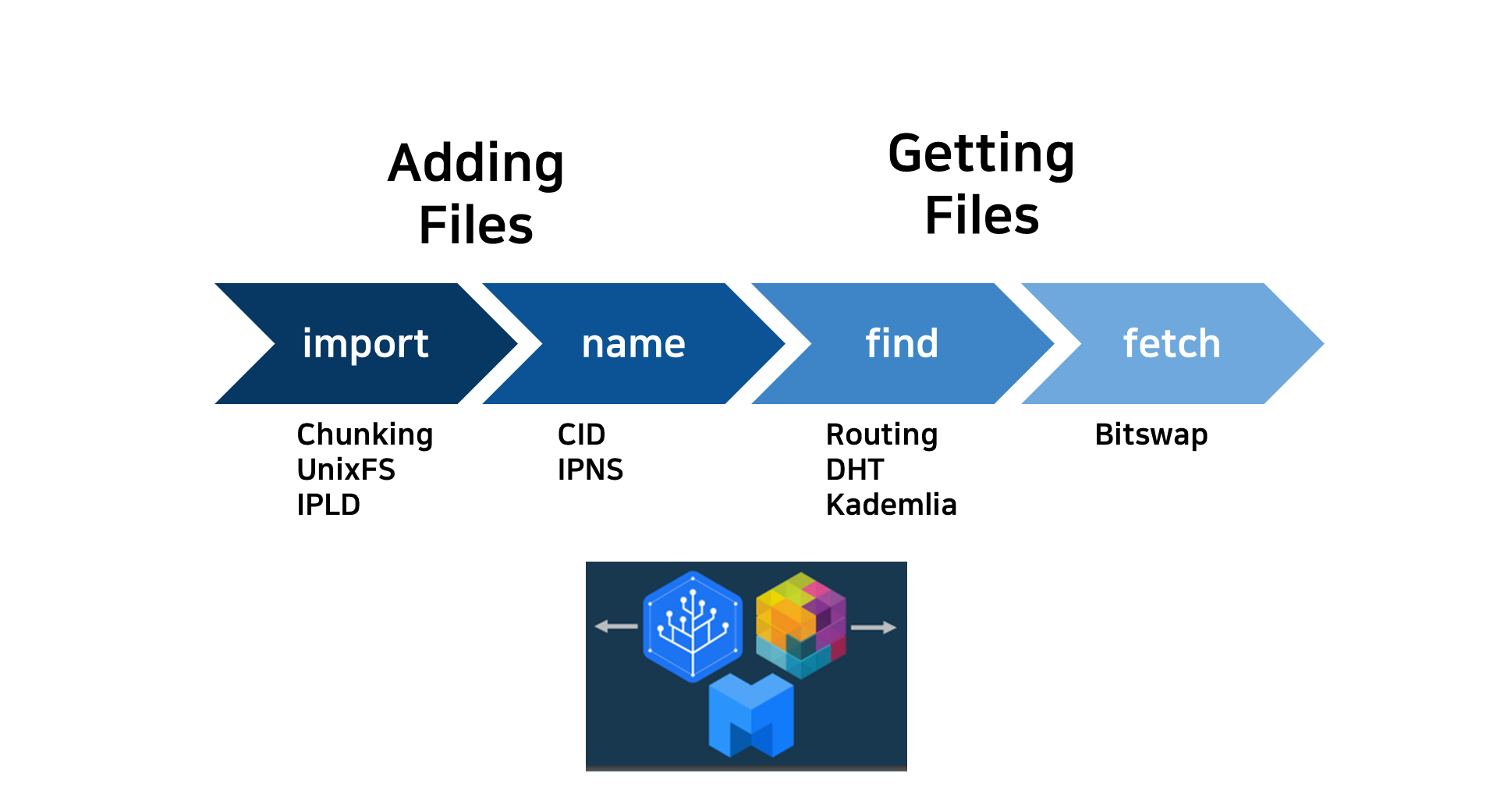
IPFS - Chunking
그림처럼 원본 파일을 chunk 합니다.
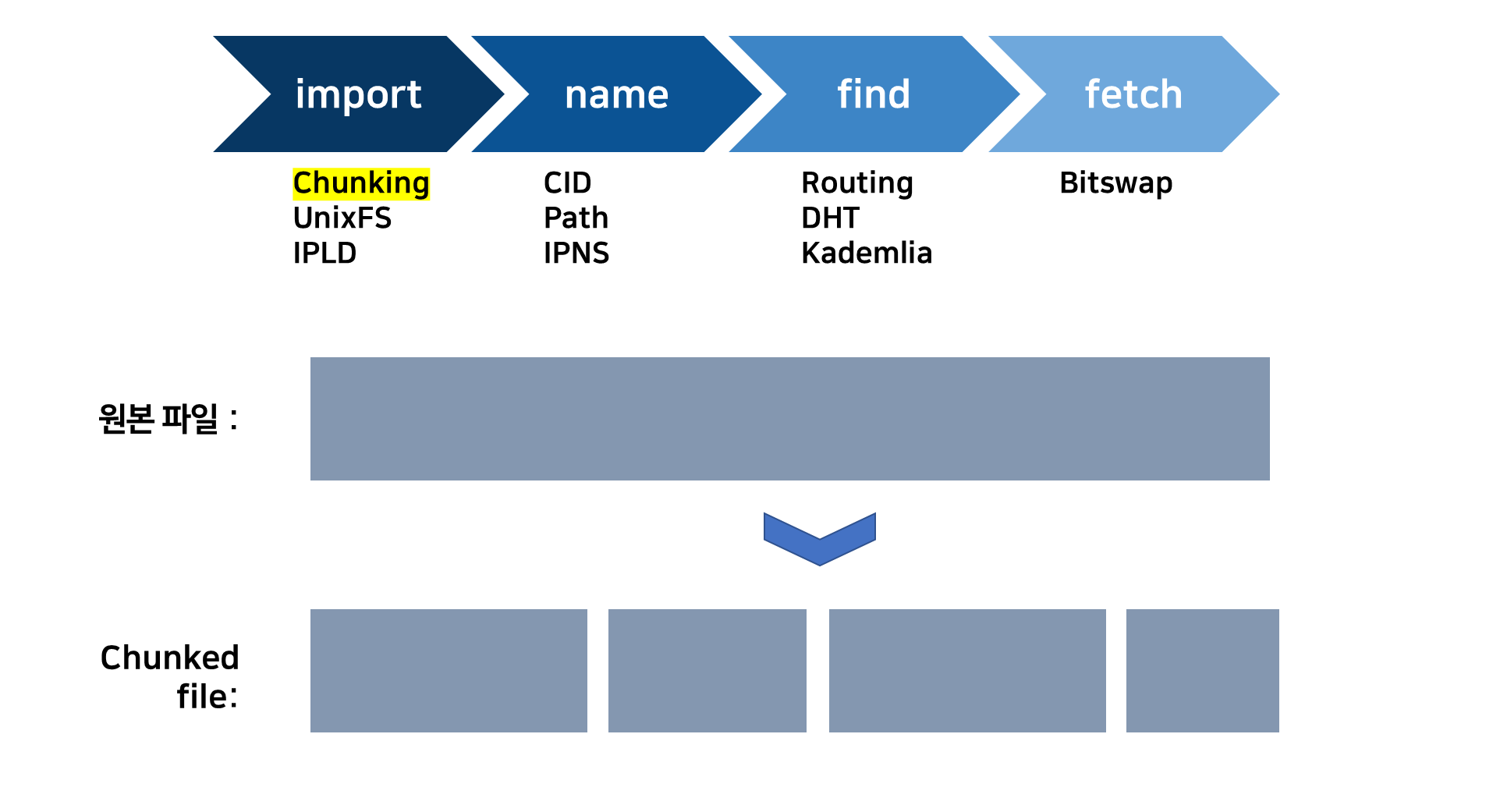
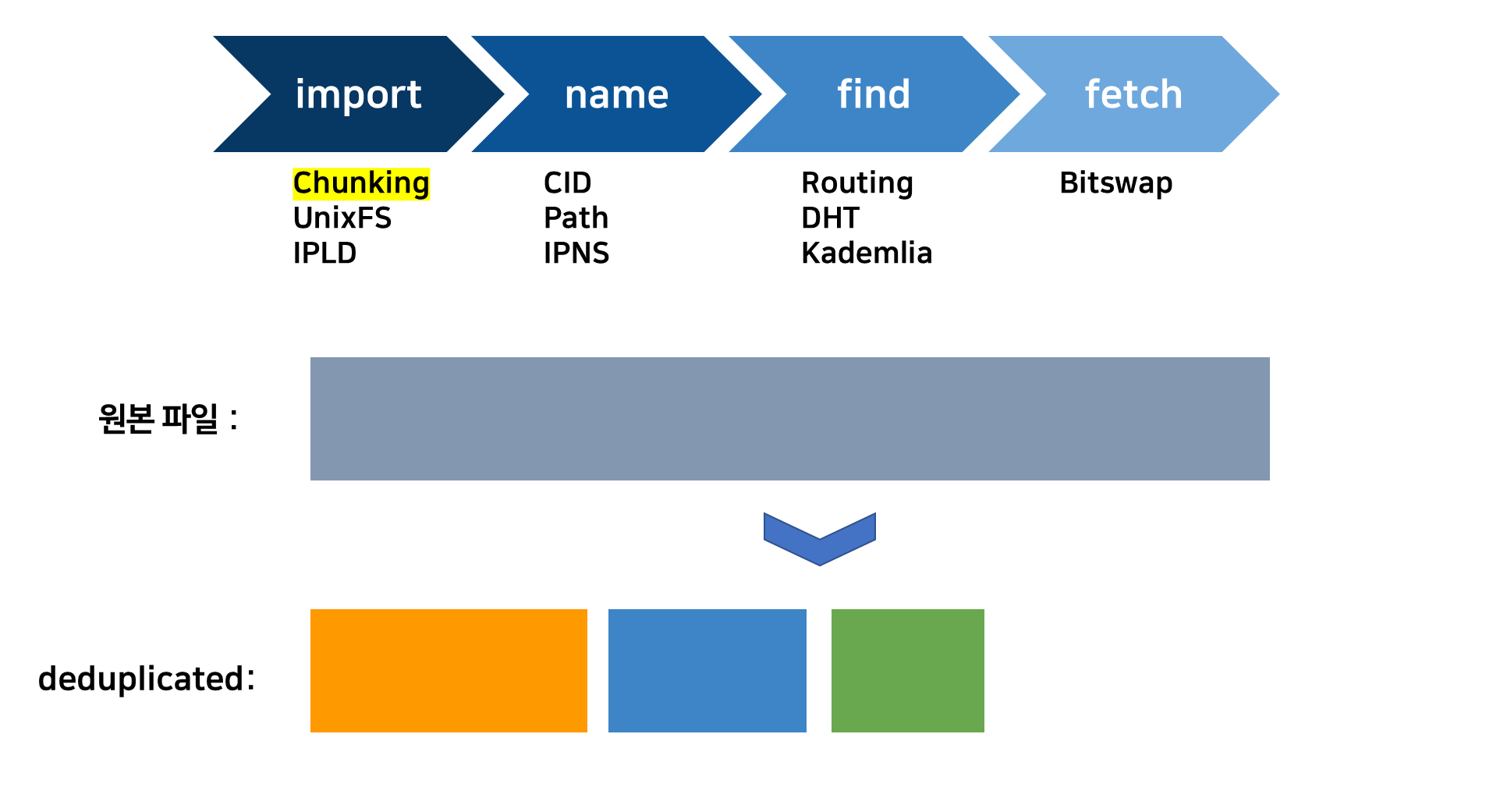
이때 중복되는 청크 데이터 파일은 저장하지 않습니다. 즉, 데이터 중복 제거. 다음과 같은 파일 상태를 UnixFS 데이터 형식이라고 한다.

이미 존재하는 것은 Merkle DAG 노드에 연결하고 새로운 청크만을 Merkle DAG 노드에 저장합니다.
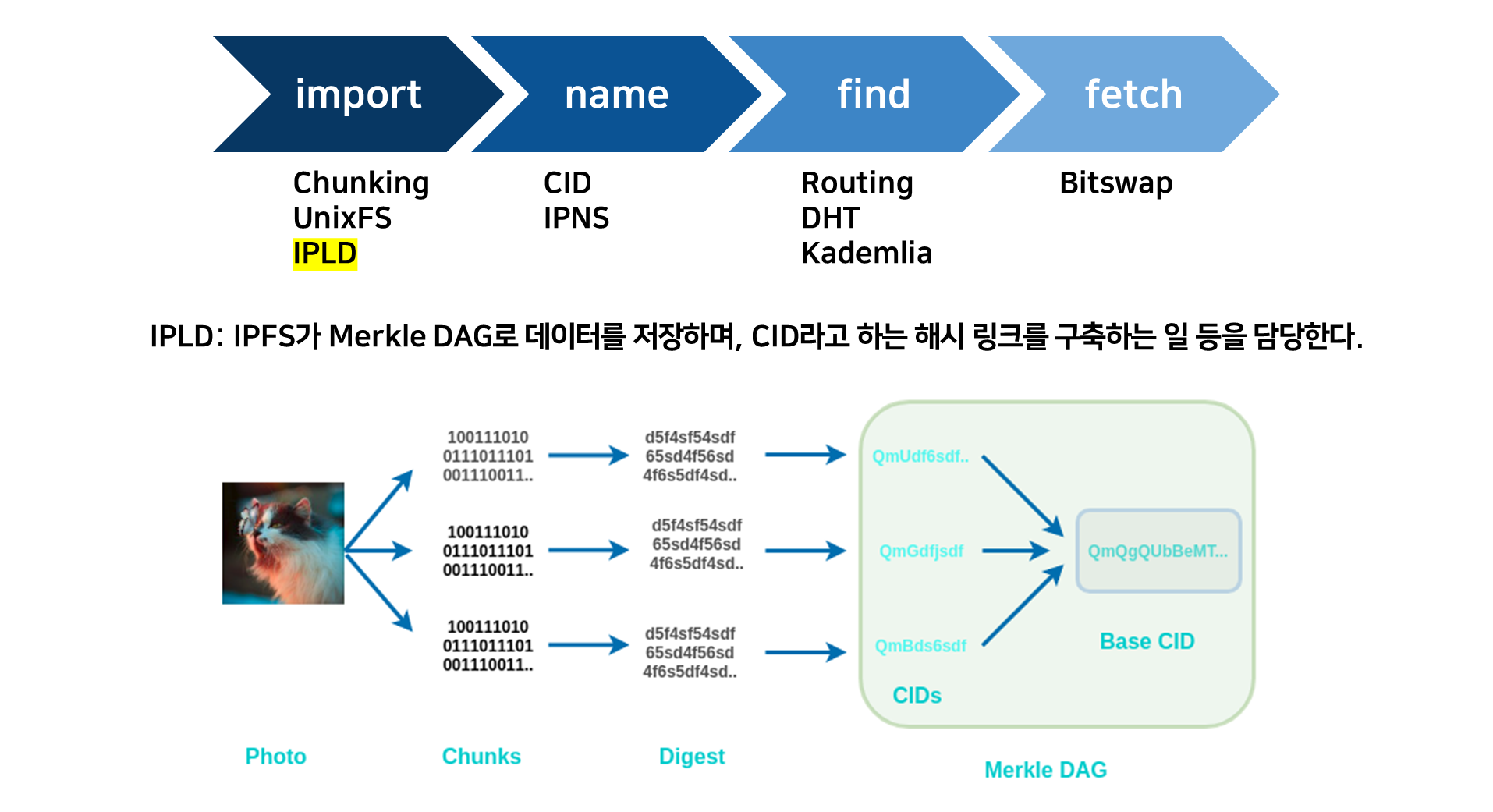
IPFS - IPLD
- IPLD는 IPFS가 Merkle DAG로 데이터를 저장하며 CID라고 하는 해시 링크를 구축하는 일 등을 담당한다.
- UnixFS 데이터 형식을 따르는 데이터에서 Merkle DAG를 생성한다.
- 콘텐츠는 Chunk를 사용하여 블록으로 분할된 다음 '링크 노드'를 사용하여 트리와 같은 구조로 배열되어 함께 묶인다.
- 반환된 CID는 DAG에 있는 루트 노드의 해시이다.
- IPLD는 해당 해시를 디코딩하여 사용자들이 데이터에 액세스할 수 있도록 한다.
IPFS - CID
CID :컨텐츠에서 파생된 IPFS의 데이터 블록에 대한 고유 주소
- content addressing에 사용됨
- IPFS/IPLD의 모든 데이터에 이름 붙이는 데 사용
- 자체 설명
자체설명이란?
- CID 버전
- CID 문자열 읽는 방법(base32, base58, hex,..) => multibase
- 데이터가 인코딩 되는 방법 => multicodec
- 어떤 해시 함수를 사용했는지 => multihash
- 해시 함수 길이 => multihash
CID V0: QmS4ustL54uo8FzR9455qaxZwuMiUhyvMcX9Ba8nUH4uVv
- “Qm”으로 시작
- CID가 base58btc를 사용하여 인코딩한다
- 데이터는 기본적으로 DAG-pb로 인코딩 된다.
- CIDv1로 변환가능 (반대는 불가능)
CID V1: bafybeibxm2nsadl3fnxv2sxcxmxaco2jl53wpeorjdzidjwf5aqdg7wa6u
- 상호 운용성을 극대화하기 위해 여러 prefix를 활용
- CID v1 = Multibase + Multicodec + Multihash
IPFS 다운로드
필자는 VMware를 사용하였고 IPFS를 이미 설치했기 때문에 이 부분에 대해서는 이미지 첨부를 하겠다. git을 통해서 설치하고 "go-ipfs" 로 이동한다.
git clone https://github.com/ipfs/go-ipfs.git
cd go-ipfsIPFS check
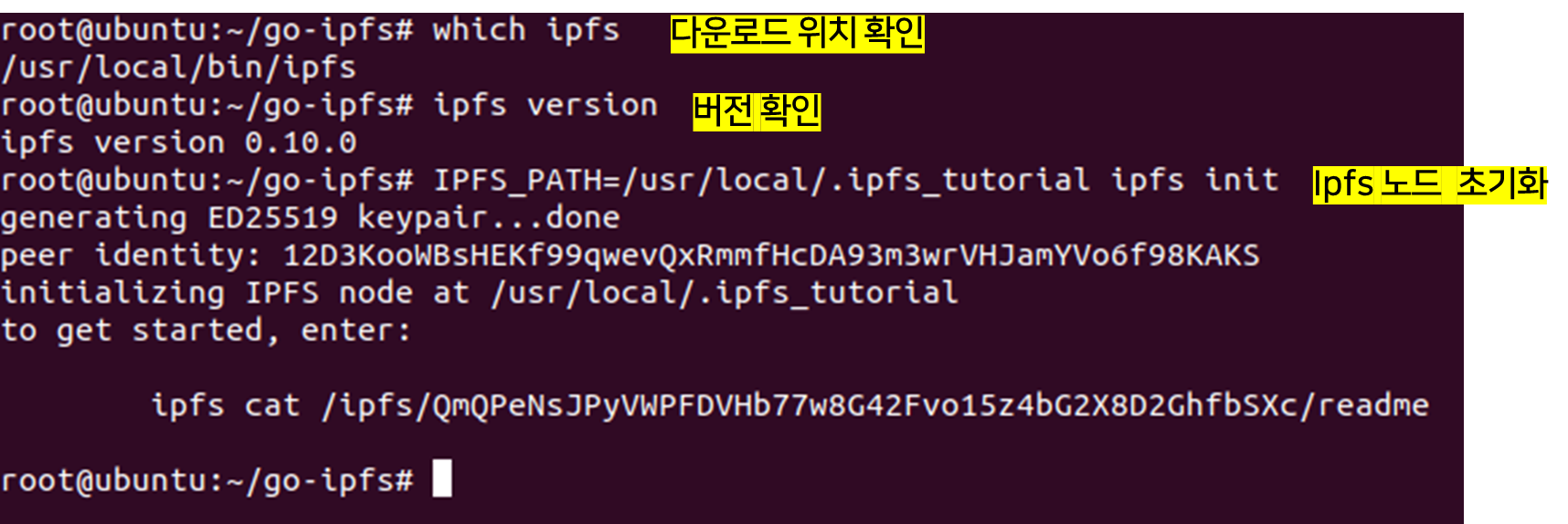
다운로드 한 위치와 버전을 확인한다. 또한 IPFS를 사용하기 전에 명령어 "ipfs init"로 노드를 초기화해준다.
컨텐츠 추가
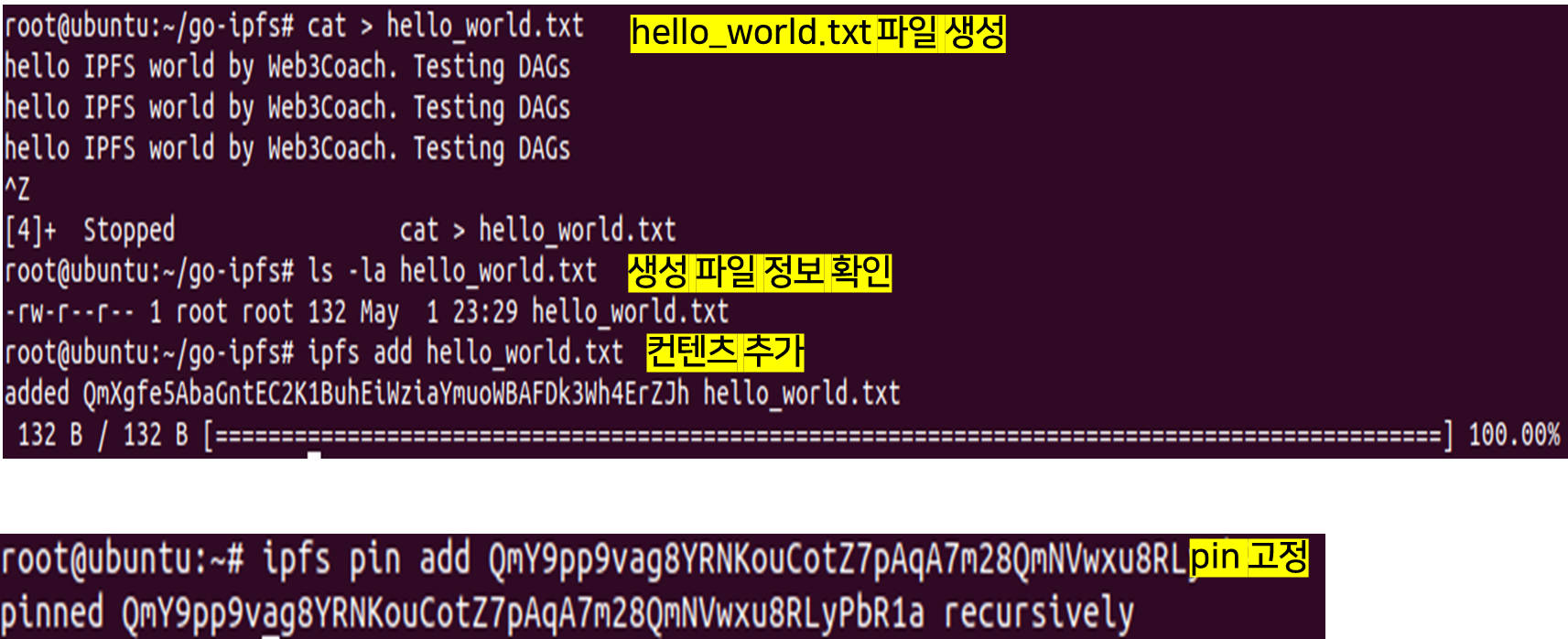
hello_wordl.txt 파일을 우선 생성한다. 이 파일을 앞으로 IPFS로 컨텐츠 추가를 한다. 우선 생성한 파일이 132바이트 크기의 파일이라는 것을 확인해준다. 명령어 "add"를 사용하여 컨텐츠를 추가하면 다음과 같이 hash가 생성된다. 그리고 생성된 hash을 pin 고정을 한다. 만약 pin 고정을 해주지 않으면 daemon을 실행한 후 stop을 하게 되면 IPFS 올리 데이터가 더 이상 공유되지 않기 때문이다.
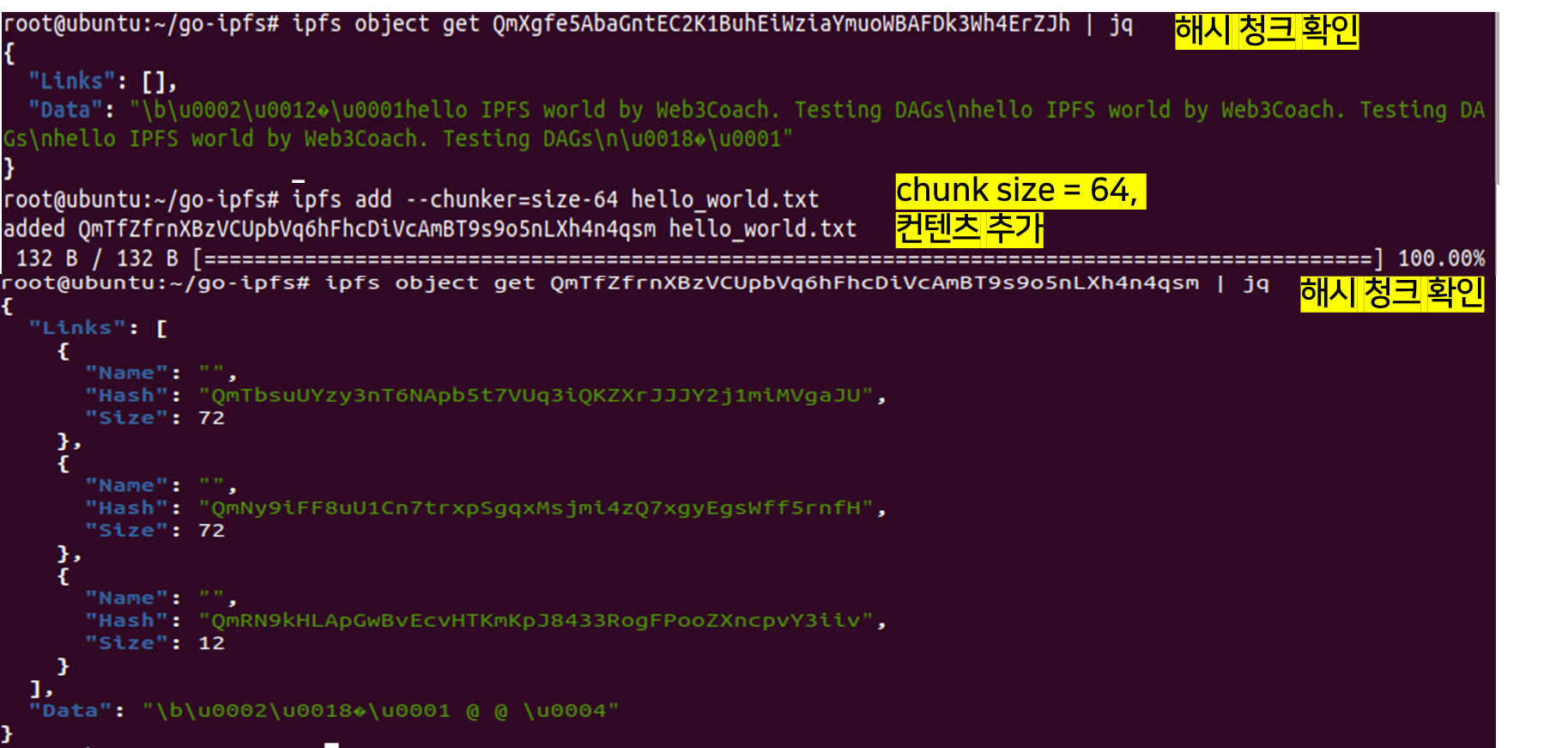
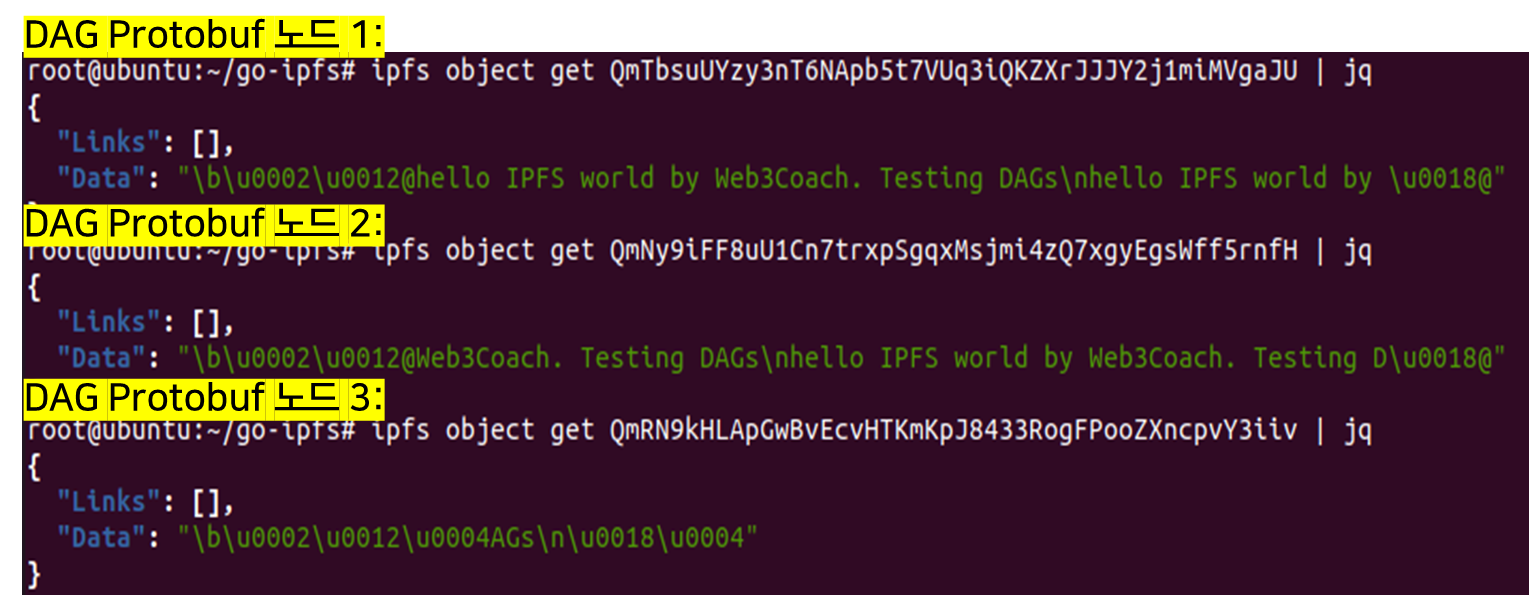
만들어진 해시파일의 청크의 내용물을 "ipfs object get" 명령어를 사용해 확인한다. 형식은 보기 좋게 json으로 확인한다. link와 data를 확인 할 수 있다. IPFS에서 파일은 실제로 매우 작은 청크 단위로 쪼개지며 하나하나 마다 해시값이 부여된다. 매우 작은 이 단위를 블록이라고 한다. 블록이란 IPFS 내부에서 쓰는 데이터 교환의 단위며 모든 블럭은 해시값을 가진다. 보통 청크를 나누는 default 값은 256바이트이다. 이 파일같은 경우 애초에 132바이트 즉, 청크를 나누는 기준보다 작아서 청크가 하나 뿐이다. 하지만 다음과 같이 chunk size를 64바이트로 지정해준다면, 총 3개의 청크가 생긴다는 것을 알 수 있다. 청크된 해시 파일들의 크기가 64가 아닌 72인 이유는 protobuf 인코딩도 추가되기 때문이다. 즉, 72 = (64+protobuf encoding).
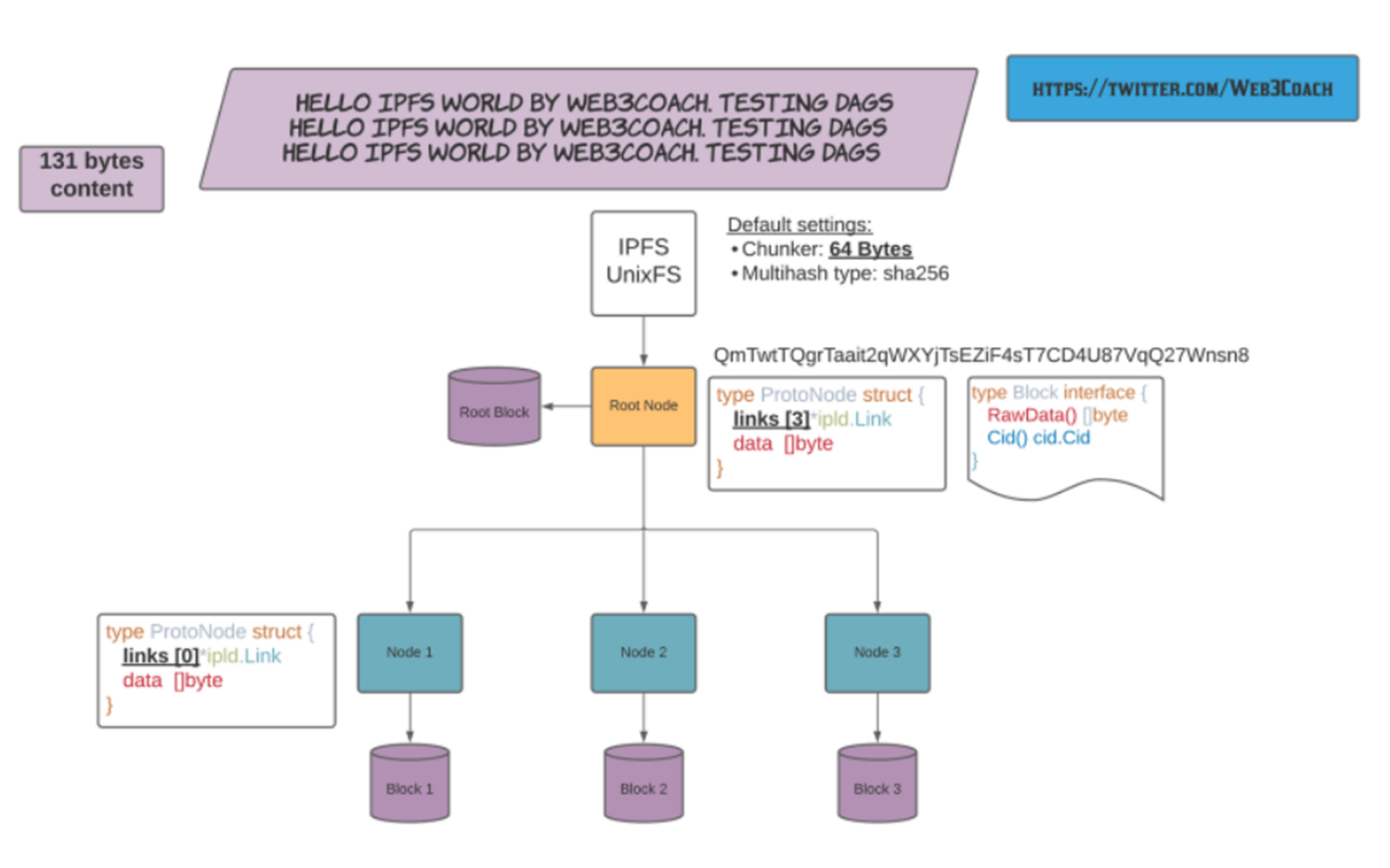
이 때까지의 컨텐츠 추가 방식을 그림으로 표현한 것입니다.
IPFS는 중복 블록을 저장하지 않는다. 대신 이미 존재하는 DAG 노드에 연결하고 새롭고 고유한 청크만 저장한다.
to be continue...

NLP 공부하는 사람