
파이썬
맨처음에는 프로그래밍 언어에 대한 쉬운 접근을 위한 교육용 언어였어요.
하지만 배우기 쉽고, 데이터 처리에서 강점을 보여서 AI, 데이터처리 등에서 사용되고 있어요!
장점
- 배우기가 쉬워요(문법, 데이터 처리)
- Interactive하게 실행이 가능해요(대화 형식의 처리가 가능)
- 데이터 처리를 위한 무료 라이브러리가 많아요!
버전
파이썬
2.x
3.x - 우리가 사용할 version이에요!
개발환경 Setting하기
python의 개발환경은 크게 2가지에요
IDE
- pycharm : Web programming을 위한 IDE에요 IntelliJ 만든 회사에서 만들었어요
- jupyter notebook: 데이터분석을 위한 웹 기반의 IDE에요(Data분석, ML, Deep Learning)
Jupyter Notebook
Jupyter Nodebook 사용 방법
1. 내 로컬 환경에 다운로드하기
작업의 안정성이 좋아요
2. Cloud Service이용해서 사용하기
일정 시간이 지나면 자동으로 세션이 만료되어요
Anaconda
우리가 여러가지 library를 사용할 때는 dependencies가 중요했어요 아나콘다라는 플랫폼을 깔게 되면 쉽게 다운로드 하도록 도와줘요
가상 환경
아나콘다는 가상 공간을 활용해서 여러가지 작업을 할 수 있게 해줍니다.
예를 들면 A공간 에서는 web programming을 하고,
B공간에서는 AI를 할 수 있고, C공간에서는 Deep learning을 위한 공간을 만들 수 있는 거에요
Anaconda 가상공간 만들기
# 가상 공간 만들기
conda create -n data_env python=3.8 openssl
# conda: 기본 명령어
# create: 생성
# -n : 이름 명시하겠다는 명령어
# python : 파이썬을 가상공간에 설치합니다.
# python=3.8 : python 버전을 명시합니다.
# openssl: OpenSSL은 암호화 라이브러리와 도구 모음으로, SSL / TLS 프로토콜을 구현하는 데 사용됩니다. python 3.8 version 을 다운해주는 이유는 tensorflow와 같은 library와의 충돌이 발생하지 않게 해주기 위함입니다.
만든 가상환경 진입
# 명령어
conda activate data_env
# data_env 가상환경에 진입합니다.가상 환경 필요한 도구 설치하기
이 3개 도구들은 거의 필수적인 도구들이에요
numpy
conda install numpy
# 버전을 명시하지 않으면 가장 최신 버전을 설치합니다.
# 다차원 자료구조를 사용하기 위한 librarypandas
conda install pandas
# Python에서 사용되는 데이터 조작 및 분석을 위한 라이브러리matplotlib
conda install matplotlib
# 데이터 시각화 도구개발관경 모듈 설치
conda install nb_conda
# Jupyter Notebook에서 Conda 환경을 관리하고 사용할 수 있도록 지원하는 확장 프로그램.jupyter notebook --generate-config
# jupyter notebook 설정파일 만들기/Users/jh/.jupyter/jupyter_notebook_config.py
# 여기에 있는 jupyter notebook설정을 바꿔줘요
450번 줄에 있는 설정을 내가 jupyter notebook파일을 저장하기 원하는 경로로 설정해요가상 환경 설정
참고할 사항
kernerl을 내가 작업하고 있는 data_env로 바꿔주어야 해요
colab 사용해보기
1. 구글 드라이브에 들어가요
2. colab을 만들어줘요
각 셀은 셀 기준으로 결과가 실행 됩니다.
하지만 메모리에는 다른 셀의 정보도 함께 올라가 있어요
다른셀에서 선언한 변수를 실행해 볼 수 있어요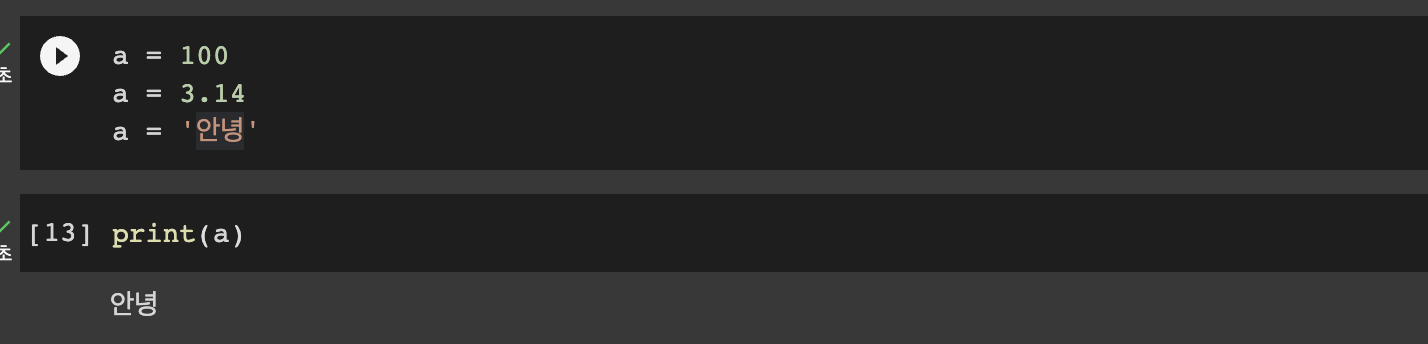
Colab 단축키
# 단축키
# 코드 셀 위에 삽입 (Command+ M + A)
# 코드 셀 아래에 삽입 (Command + M + B)
# 코드 셀 삭제 (Command + M + D)
# 실행하고 커서는 해당셀
# Command + Enter
# 실행하고 커서는 다음셀
# shift + Enter
# 실행하고 다음셀 만들고 커서 다음셀
# option + Enterpython 사용하기
주석
# 한줄 주석은 이렇게 사용 해요
'''
여러줄 주석은 이렇게 사용 해요
'''변수 만들고 삭제하기
변수 만들 때 Data type을 따로 명시하지 않아요
특정 변수 안에 여러가지 Data Type이 들어갈 수 있어요
변수 만들기
a = 100
a = 3.14
a = '안녕'변수 삭제하기
del a
# 할 수 는 있지만 실제로 권장하지는 않아요
# 우리가 삭제하지 않아도 가비지컬렉터가 메모리를 정리해주기 때문이에요python의 build-in data type
# 1. Numeric(숫자)
# - 정수
# - 실수
# - 복소수
# - 진수
# 2. Sequence
# 3. Text Sequence
# 4. Mapping
# 5. Set
# 6. Bool
# 다음의 6가지 범주로 나누어 집니다. 1. Numeric(숫자)
# 1. Numeric(숫자)
# - 정수
a = 123 # 정수
# - 실수
b = 3.14 # 실수
# - 복소수
# 우리는 복소수까지는 알아보지 않을꺼에요
print(type(a)) # <class 'int'>
print(type(b)) # <class 'float'>
result = 3/4 # java인 경우 0 (int / int로 하기 때문에 정수인 0이 나오는게 당연해요)
print(result) # 0.75 (python의 경우 정수, 실수를 모두 Numeric이라는 type이에요. 계산할 때는 모두 실수로 보고 처리해요)Sequence build-in type
# 1. List
# 2. Tuple
# 3. RangeSequence - List
# 2. Sequence
# python은 우리가 알고 있는 데이터타입(Map, list, set)도 data type으로 간주해요
# Sequence는 3가지가 있어요
# list (python의 가장 중요한 자료구조이자 data type)
# 객체를 순서대로 저장하는 집합형 자료구조
# Java의 ArrayList와 상당히 유사합니다.
# literal은 어떻게 되나요? (literal: 코드로 표현하는 방식) = []
# python은 배열이 없어요, list만 있어요! (list와 배열의 차이는 무엇일까요?)
myList = list() # list class 생성자 호출, class를 이용해서 객체 만드는 방식
myList = [1, 2, 3, 4] # literal을 이용한 방식
print(type(myList2)) # <class 'list'>
# 중첩 리스트도 가능해요!
# list안에 list가 들어갈 수 있다는 말이에요
myList = [[1,2],3,4,5,[6,7,[8]]]
print(myList) # [[1, 2], 3, 4, 5, [6, 7, [8]]]
# indexing 예시
print(myList[4]) # [6, 7, [8]]
print(myList[4][2]) # [8]
print(myList[-1]) # -1은 뒤에서 첫번째를 의미해요
# slicing
# 특징 - 원본과 처리 결과의 데이터 타입이 항상 같아요
print(myList[0:2]) # 슬라이싱의 앞은 포함, 뒤쪽은 포함되지 않아요 0 ~ 1을 자르라는 뜻이에요
print(myList[0:])
# rmeofh qhrtk
print(myList[:])
# indexing 할 때
print('인덱싱')
print(myList[0]) # 결과물로 요소가 나와요
print('슬라이싱')
print(myList[0:1]) # 결과물로 list가 나와요
# list
a = [1, 2, 3]
b = [4, 5, 6]
c = a + b
print(c) # [1, 2, 3, 4, 5, 6]
c = a * 3
print(c) # [1, 2, 3, 1, 2, 3, 1, 2, 3]
# list는 객체에요
# 당연히 굉장히 많은 method를 가지고 있어요
a = [1, 2, 3]
a.append(4)
print(a) # [1, 2, 3, 4]Sequence - Tuple
# Sequence built-in data type
# tuple에 대해서 알아봐요
# list와 tuple은 거의 비슷해요.
# 가장 큰 차이점은 tuple이 read only라는 것이에요
# tuple은 literal로 ()를 이용해요
# tuple의 생성
a = tuple() # literal이 아니라 class를 이용해서 객체를 생성
a = (1, 2, 3, 4) # <class 'tuple'>
print(type(a))
a = (1, ) # 요소가 1개인 tuple은 이렇게 표현해요
a = (1, 2, 3, 4)
print(a[2]) # 3
print(a[2:3]) # (3,)
# a[3] = 100 # tuple은 read only이기 때문에 오류 발생
# tuple 내부에 list가 들어가 있으면 값을 변화 시킬 수 있을까?
# list는 바뀌지 않아요
# 하지만 list의 요소는 바뀔 수 있어요
# 객체를 지칭하는 값이 아니라, 객체의 메모리 주소가 변하지 않으면 변하지 않는다고 인식해요
a = (1, 2, 3, [4, 5, 6], 7)
print(a[3][0])
a[3][0] = 100
print(a)
# tuple은 기호를 생략할 수 있어요(??)
a = (1, 2, 3)
a = 1, 2, 3 # 이게 가능해요(일반적으료 이렇게 사용해요)
print(type(a)) # <class 'tuple'>
a, b, c = 1, 2, 3 # a에 1을, b에 2를, c에 3을 넣어요
# 설명한 특성을 제외한 나머지 특성은 list와 유사해요
# typle, list는 서로 바꿀 수 있어요
a = (1, 2, 3)
b = list(a) # tuple을 list로 바꾸기
print(type(b)) # <class 'list'>Sequence - Range
# Sequence built-in data type
# 3. range
# literal로 쓰지 않아요
a = range(10) # 시작은 0부터 시작, 19까지, 1씩 증가하는 숫자의 범위
print(a) # 직접 data를 갖지 않아요
print(type(a))
# range(10000000)
# range가 만약 실제 data를 가지고 있다고 하면 큰 범위의 range를 다룰 때 메모리가 많이 낭비될 수 있어요
a = range(2, 42, 2) # 2부터 시작해서 42의 전까지, 2씩 증가시켜요
print(a)
print(a[0]) # 2
3. Text Sequence(문자열)
# 3. Text Sequence(문자열)
# 문자열 - 사용하는 클래스는 str
# literal은 '', "" 둘 다 사용할 수 있어요(default는 '')
# 문자 개념이 없어요 모두 문자열이에요
a = '뉴진스 화이팅'
print(type(a)) # <class 'str'>
# Text Sequence는 실제로는 list에요
# list의 성질을 갖고 있어요
a = '홍'
b = '길순'
print(a + b)
# indexing 사용하기
print(a[0])
# slicing 사용하기
print(a[0:1])
# 기억해야 할 특이한 연산자 하나가 있어요
print('길' in b) # python은 True(앞글자 대문자)에요 Java는 true에요
# 문자열은 str class의 객체에요. 그러다보니 굉장히 많은 method를 가지고 있어요
print('오늘도 뉴진스 화이팅 {}, {}'.format('Ditto 너무 조아', 'hypeboy도 조아')) # {}는 문자열 안의 {}를 다른것으로 대체한다는 의미에요4. Mapping
# 4. Mapping
# 우리가 흔히 알고 있는 Map 구조(키와 Value로 데이터를 저장하는 구조)
# 파이썬에서는 이런 자료구조를 dictionary라고 불러요(공식적인 이름은 Mapping이에요)
# 사용하는 class는 dict
# literal로 표현할 수 있어요 => {} : dictionary
# 참고
# [] : list
# () : tuple
# {} : dict
a = {'name': '카즈하', 'age': '20'}
print(type(a)) # <class 'dict'>
print(a)
a['주소'] = '서울'
print(a) # {'name': '카즈하', 'age': '20', '주소': '서울'}
print(a.keys()) # dict_keys(['name', 'age', '주소'])
print(a.values()) # dict_values(['카즈하', '20', '서울'])
# 생긴것만 보면 key를 모아서 list로 만들어서 return하는 것 같아요
# 하지만 진짜 list는 아니에요. list와 유사한 자료구조에요
# 일반적으로 for문을 이용할 때 이런걸 사용해요
# for ~ in (list, tuple, list와 유사한 자료구조)
for tmp in a.keys():
print(tmp) # 4칸을 띄워야 해요5. SET
# 5. Set
# 우리가 알고있는 그 Set이에요
# 순서가 없어요. 중복 배제해요
# Set의 literal은 {}이에요
# [], {}(kㅏ됴dhk ㅍ미ㅕㄷdml Tkddmfh vygus), ()
a = { 1, 2, 3, 4, 1, 2, 3 }
6. Bool
# 참(True) 또는 거짓(False) 값을 나타내는 데이터 타입입니다.
# 숫자 0은 False
# 빈 문자열("")은 False
# 0 이외의 숫자는 모두 True
# 비어있지 않은 문자열은 모두 True제어문
if문
# Control statement
# 제어문 (if, for)
area = ['서울', '부산', '제주']
# if문
if '서울' in area:
print(True)
else:
print(False)
if '서울' in area:
pass # 조건이 맞으면 pass! 아무것도 안함
else:
print(False)
for 문
# for 문
# 1. for ~ in range()
# 2. for ~ in list, dict
# 반복할 횟수를 명확히 알고 있을 때
for test in range(5):
print(test)
# 1
# 2
# 3
# 4
# print(): 인자로 들어온 문자열을 출력하고 한줄을 띄워요!
# 줄바꿈을 사용하고 싶지 않을 때
for test in range(5):
print(test, end='')
# 01234
print()
a = ['카즈하', '방시혁', '케이윌']
for name in a:
print(name)python에서 함수 만들기
# 함수를 만드는 방법
# JavaScript
# function myFunc() {};
# Java
# 함수가 없어요. 대신 class안에 method가 있어요
# class A {}
# python에서 함수를 만드는 방법
def myFunc(a, b, c):
print(a, b, c)
result = myFunc(10, 20, 30)