ELK 구축
AWS OpenSearch 구축하기
이 글은 사이드 프로젝트 및 학습 목적으로 구축하였습니다.
맨먼저 AWS 서비스 중 OpenSearch를 들어갑니다.
이후 도메인 생성 을 클릭합니다.
생성과정
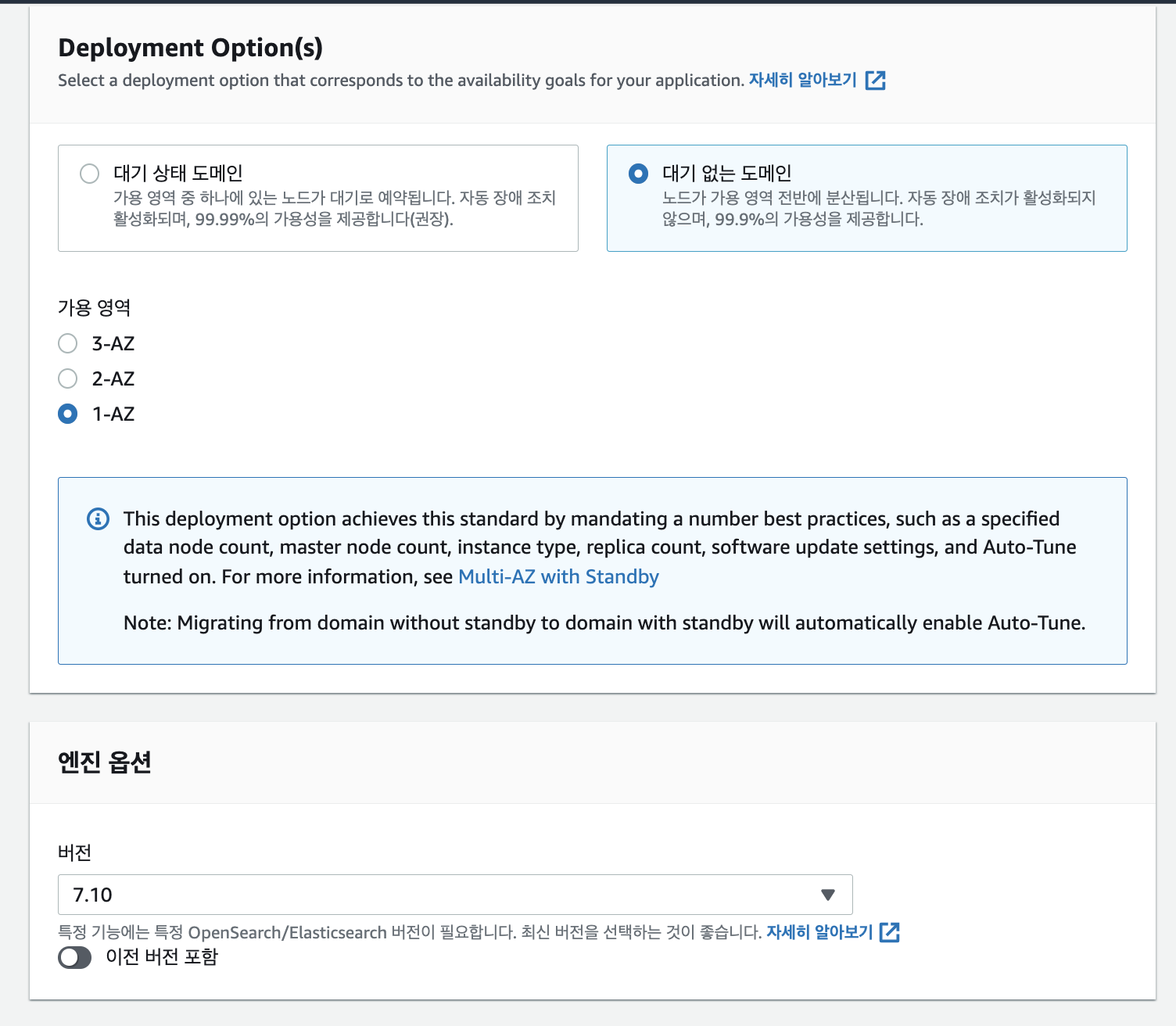
버전을 7.10 ElasticSearch버전을 사용하였으며, 가용 영역은 1-AZ 를 하였습니다.
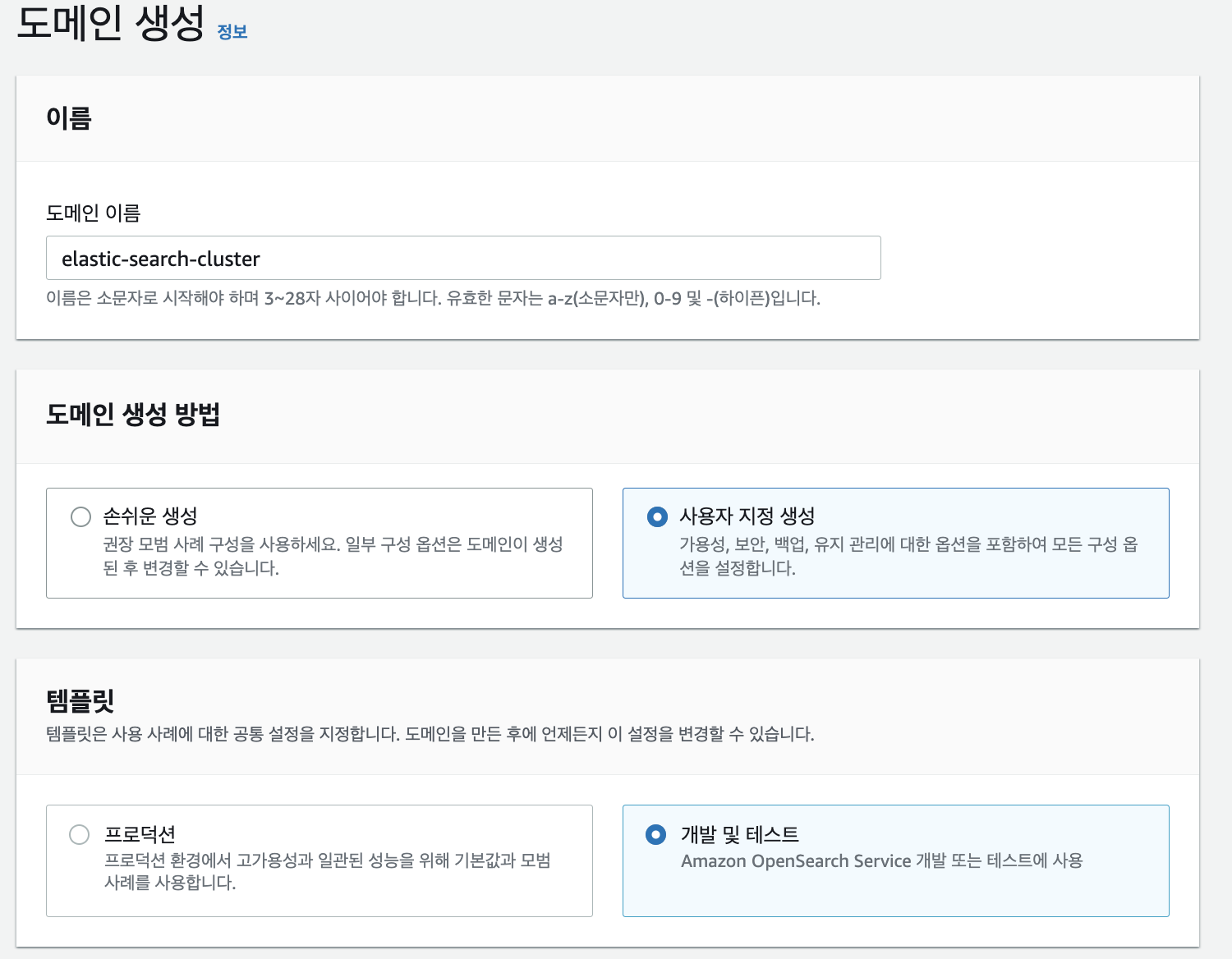
인스턴스유형은 제일 낮은 t3.small.search를 선택하였어요 사이즈가 큰 유형들은 돈이 많이들수도있기에.. 얼른 사용하고 도망....
노드수는 1개 !
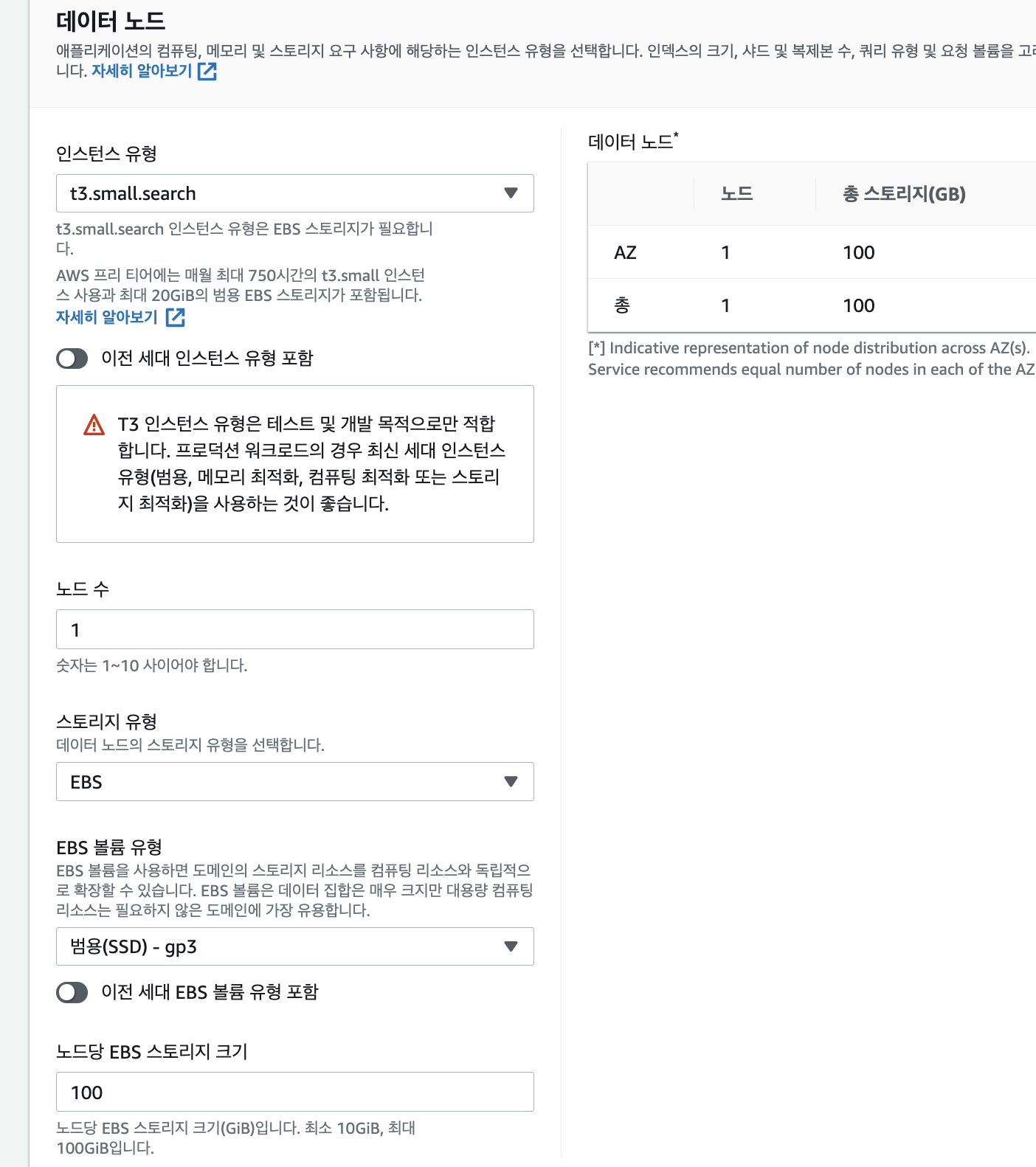
네트워크 부분은 퍼블릭 액세스를 사용하였으며, 이후 마스터 사용자 생성을 클릭합니다.
네트워크 부분은 웬만하면 VPC액세스를 쓰는게 맞는것같습니다. 저는 후다닥 사용해보고 할 예정이여서,, 현업이나, 다른 프로젝트할때는 VPC 정해줘야합니다! .
마스터 사용자 생성 부분은 오픈 서치가 생성 이후 Kibana URL을 받을수있는데 이때 Kibana로 들어갈수있는 로그인 이기에 기억을 잘해둡시당
이후 생성이 될때까지 10~15분 소요가 되었습니다.
도메인상태가 활성으로 되어있다면 완성!
이후 Kibana URL 을 타고 들어가면 이와같이 생성된걸 볼 수 있습니당 .
Log Stash 구축
구축하기위해서 앞서 만들었던 EC2와 같은 스펙으로 똑같이 만들어주고 시작했으며, 도커 가 깔려있는 상태이다.
docker pull docker.elastic.co/logstash/logstash-oss:7.10.2이후 CQRS 도입기 -1 편 아키텍처 에 맞게 CUD 어플리케이션에서 메세지를 보내면 카프카에서 들어온 데이터를 가공하여, OpenSearch로 데이터를 보낸후 READ - Application 에서 컨트롤러를 만든후 데이터를 읽을예정이다.
vi /pipline/logstash.confinput {
kafka {
bootstrap_servers => ["msk 주소"]
topics => ["cud-어플리케이션에서 설정한 topic"]
consumer_threads => 1
}
}
filter{
json {
source => "message"
# READ - Application에서 OpenSearch안에있는
# 데이터를 json으로 가공하여 데이터를 받기위한 filter조건
}
}
output {
elasticsearch {
hosts => ["오픈서치주소URL:443"]
workers => 1
index => "색인된 index"
user => "앞서 생성할때 만들었던 마스터사용자이름"
password => "사용자 비밀번호 "
ilm_enabled => false
}
}
이후
docker run --name logstash -p 5000:5000 -p 5044:5044 -d -e LS_JAVA_OPTS="-Xms512M -Xmx512M -XX:ParallelGCThreads=1" -v ~/pipeline/:/usr/share/logstash/pipeline/ docker.elastic.co/logstash/logstash-oss:7.10.2이후 정상적으로 작 동하는지 보자!
docker logs -f 이미지아이디 포스트에 작성은 안해 보았지만, docker-elk로 한번 로컬에서 띄워보고 해보는걸 추천!

정상작동한다!
READ - Spring Boot Application 구축
CUD어플리케이션 스펙과 동일하며 ElasticSearch의존성만 설치하였다.
implementation 'org.springframework.boot:spring-boot-starter-data-elasticsearch'
implementation 'org.springframework.data:spring-data-elasticsearch'ESConfig
여기서 조금 삽질을 하였다.
분명 OpenSearch에서 퍼블릭엑세스로 설정했는데도 불구하고 연결이안되는걸 알수있었다.
하여 아래 config url만 설정과 OpenSearch를 만드는과정에서 생성하였던 마스터사용자이름 및 마스터사용자비밀번호 를 넣어주자
@Configuration
@EnableElasticsearchRepositories
@Slf4j
public class ESConfiguration extends AbstractElasticsearchConfiguration {
@Override
public RestHighLevelClient elasticsearchClient() {
log.info("elasticsearch configuration");
// http port 와 통신할 주소 주소바꿔줘야하고
ClientConfiguration configuration = ClientConfiguration.builder()
.connectedTo("elastic주소")
.usingSsl()
.withBasicAuth("마스터사용자유저이름", "마스터사용자비밀번호")
.build();
return RestClients.create(configuration).rest();
}
@Override
public ElasticsearchOperations elasticsearchOperations(ElasticsearchConverter elasticsearchConverter,
RestHighLevelClient elasticsearchClient) {
return new ElasticsearchRestTemplate(elasticsearchClient());
}
}
이후 ElasticSearchRepository 추가를 하였습니다.
CriteriaQuery 개체는 Elasticsearch에서 데이터를 검색하는 데 사용되는 개체이기에 불러와서 사용합니다.
operations 개체는 Elasticsearch 클라이언트의 개체입니다. search() 메서드를 사용하여 Elasticsearch 인덱스에서 데이터를 검색하는 데 사용할 수 있고 . search() 메서드를 통해 검색 쿼리를 입력으로 사용하고 검색 결과를 반환하는 SearchHits 개체를 반환하는 형식으로 하였습니다
@RequiredArgsConstructor
@Repository
@Slf4j
public class ManSearchQueryRepository {
private final ElasticsearchOperations operations;
public List<Man> searchMan(SearchManCondition searchManCondition) {
//
CriteriaQuery query = createlikesCriteriaQuery(searchManCondition);
SearchHits<Man> search = operations.search(query, Man.class);
log.info("search ={}", search);
return search.stream().map(SearchHit::getContent).collect(Collectors.toList());
}
private CriteriaQuery createlikesCriteriaQuery(SearchManCondition searchManCondition) {
CriteriaQuery query = new CriteriaQuery(new Criteria());
//
Man man = new Man();
if (StringUtils.hasText(searchManCondition.getHobby())) {
query.addCriteria(Criteria.where("hobby").contains(searchManCondition.getHobby()));
}
if (StringUtils.hasText(searchManCondition.getGithubUrl())) {
query.addCriteria(Criteria.where("githubUrl").contains(searchManCondition.getGithubUrl()));
}
if (searchManCondition.getAge() > 60) {
query.addCriteria(Criteria.where("age").is(searchManCondition.getAge()));
}
if (searchManCondition.getHeight() > 50) {
query.addCriteria(Criteria.where("height").is(searchManCondition.getHeight()));
}
return query;
}
}이후 제일 중요한 매핑과정 ...
엔티티 매핑
@Document(indexName = "색인된 인덱스명")
@Mapping(mappingPath = "classpath:elastic/settings/Man-mappings.json")
@Setting(settingPath = "classpath:elastic/settings/Man-settings.json")
public class Man {
@Id
private String id;
@Field(type = FieldType.Text)
private String name;
@Field(type = FieldType.Integer)
private Integer age;
@Field(type = FieldType.Text)
private String hobby;
@Field(type = FieldType.Integer)
private Integer height;
@Field(type = FieldType.Text)
private String job;
@Field(type = FieldType.Text)
private String tech;
@Field(type = FieldType.Text)
private String githubUrl;
}
위 mapping 어노테이션을 통해 nori 분석기를 사용합니다 .
이 설정을 통해 name 필드의 값은 nori 형태소 분석기를 사용하여 형태소로 분석됩니다.
예를 들어,
"안녕하세요"라는 문자열이 name 필드에 저장되면 다음과 같이 형태소로 분석됩니다.
[안녕, 하세요]nori 형태소 분석기는 한국어에서 자주 사용되는 형태소 분석기이며, nori 형태소 분석기를 사용하여 문자열을 형태소 분석하면, 문자열을 단어와 구로 구분할 수 있습니다. 이 기능은 검색 결과를 필터링하거나, 문서를 분류하는 데 유용하게 사용할 수 있습니다.
테스트 확인
컨트롤러 와 서비스는 안올렸습니당,, 필요한 부분은 github을 통해서 확인해주세요!
이후 CUD 어플리케이션에서 보낸데이터를 읽어볼예정이다.
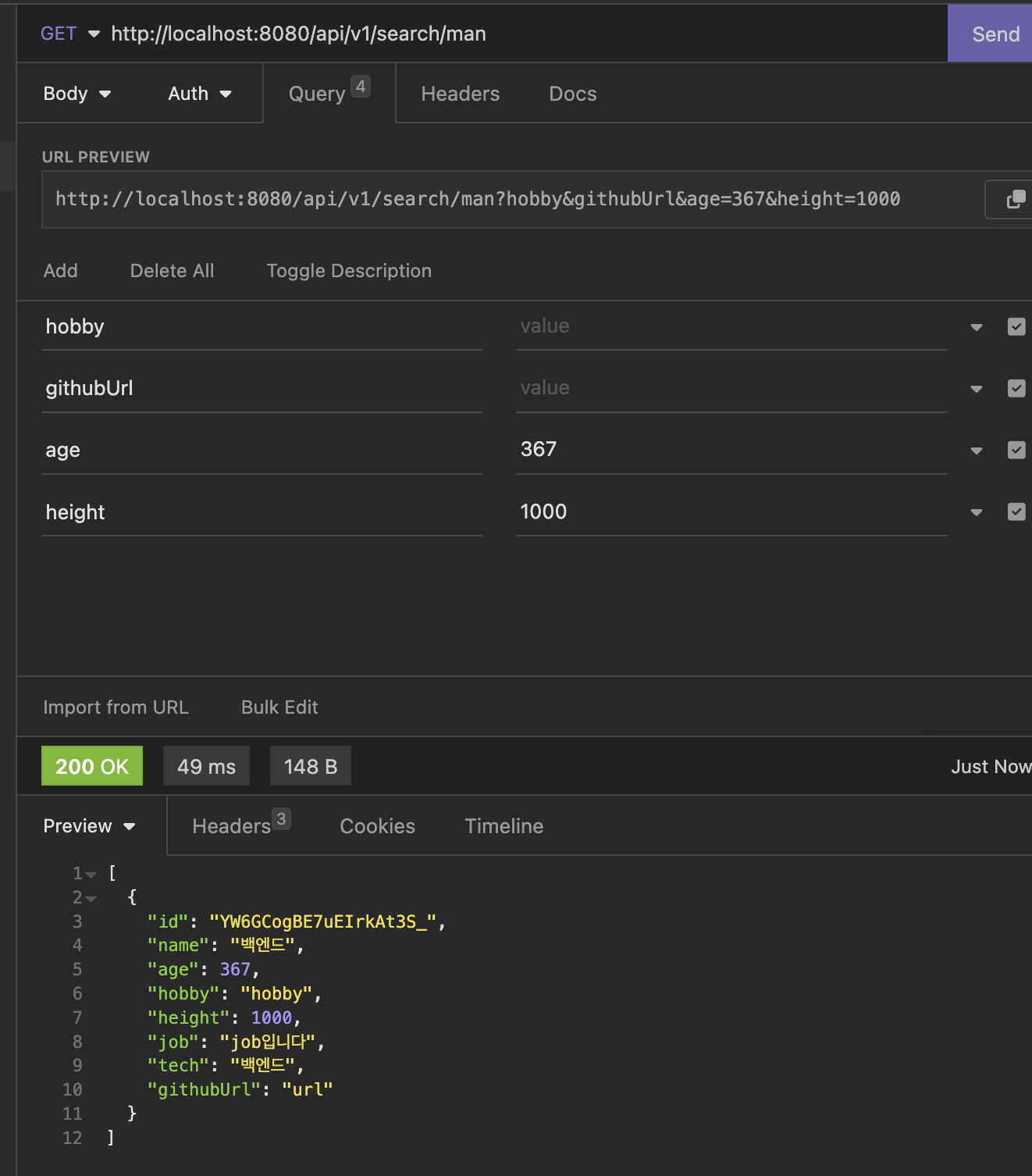
READ 어플리케이션에서 createlikesCriteriaQuery 를 통하여 데이터를 불러와보면
정상적으로 나오는걸 확인 할 수 있었다.
추후 성능 테스트를 해볼예정이다.
